go 和 Web
Web 开发简介
因为Go的 net/http 包提供了基础的路由函数组合与丰富的功能函数。所以在社区里流行一种用Go编写API不需要框架的观点,在我们看来,如果你的项目的路由在个位数、URI固定且不通过URI来传递参数,那么确实使用官方库也就足够。但在复杂场景下,官方的http库还是有些力有不逮。例如下面这样的路由:
GET /card/:id
POST /card/:id
DELTE /card/:id
GET /card/:id/name
...
GET /card/:id/relations可见是否使用框架还是要具体问题具体分析的。
Go的Web框架大致可以分为这么两类:
- Router框架
- MVC类框架
在框架的选择上,大多数情况下都是依照个人的喜好和公司的技术栈。例如公司有 很多技术人员是PHP出身,那么他们一定会非常喜欢像beego这样的框架,但如果 公司有很多C程序员,那么他们的想法可能是越简单越好。比如很多大厂的C程序 员甚至可能都会去用C语言去写很小的CGI程序,他们可能本身并没有什么意愿去 学习MVC或者更复杂的Web框架,他们需要的只是一个非常简单的路由(甚至连路 由都不需要,只需要一个基础的HTTP协议处理库来帮他省掉没什么意思的体力劳 动)。
Go的 net/http 包提供的就是这样的基础功能,写一个简单的 http echo server 只需要30s。
//brief_intro/echo.go
package main
import (...)
func echo(wr http.ResponseWriter, r *http.Request) {
msg, err := ioutil.ReadAll(r.Body)
if err != nil {
wr.Write([]byte("echo error"))
return
}
writeLen, err := wr.Write(msg)
if err != nil || writeLen != len(msg) {
log.Println(err, "write len:", writeLen)
}
}
func main() {
http.HandleFunc("/", echo)
err := http.ListenAndServe(":8080", nil)
if err != nil {
log.Fatal(err)
}
}这个例子是为了说明在Go中写一个HTTP协议的小程序有多么简 单。如果你面临的情况比较复杂,例如几十个接口的企业级应用,直接 用 net/http 库就显得不太合适了。
开源界有这么几种框架,第一种是对httpRouter进行 简单的封装,然后提供定制的中间件和一些简单的小工具集成比如gin,主打轻量, 易学,高性能。第二种是借鉴其它语言的编程风格的一些MVC类框架,例如 beego,方便从其它语言迁移过来的程序员快速上手,快速开发。还有一些框架功 能更为强大,除了数据库schema设计,大部分代码直接生成,例如goa。不管哪种 框架,适合开发者背景的就是最好的。
router 请求路由
在常见的Web框架中,router是必备的组件。Go语言圈子里router也时常被称为 http 的multiplexer。如果开发Web系统对路径中带参数没什么兴趣的话,用 http 标准库中的 mux 就可以。
RESTful是几年前刮起的API设计风潮,在RESTful中除了GET和POST之外,还使用了HTTP协议定义的几种其它的标准化语义。具体包括:
const (
MethodGet = "GET"
MethodHead = "HEAD"
MethodPost = "POST"
MethodPut = "PUT"
MethodPatch = "PATCH" // RFC 5789
MethodDelete = "DELETE"
MethodConnect = "CONNECT"
MethodOptions = "OPTIONS"
MethodTrace = "TRACE"
)来看看RESTful中常见的请求路径:
GET /repos/:owner/:repo/comments/:id/reactions
POST /projects/:project_id/columns
PUT /user/starred/:owner/:repo
DELETE /user/starred/:owner/:repo相信聪明的你已经猜出来了,这是Github官方文档中挑出来的几个API设计。 RESTful风格的API重度依赖请求路径。会将很多参数放在请求URI中。除此之外还 会使用很多并不那么常见的HTTP状态码。如果我们的系统也想要这样的URI设计,使用标准库的 mux 显然就力不从心了。
httprouter
较流行的开源go Web框架大多使用httprouter,或是基于httprouter的变种对路由进 行支持。前面提到的github的参数式路由在httprouter中都是可以支持的。
因为httprouter中使用的是显式匹配,所以在设计路由的时候需要规避一些会导致路 由冲突的情况,例如:
conflict:
GET /user/info/:name
GET /user/:id
no conflict:
GET /user/info/:name
POST /user/:id简单来讲的话,如果两个路由拥有一致的http方法(指 GET/POST/PUT/DELETE)和 请求路径前缀,且在某个位置出现了A路由是wildcard(指:id这种形式)参数,B路 由则是普通字符串,那么就会发生路由冲突。路由冲突会在初始化阶段直接panic:
panic: wildcard route ':id' conflicts with existing children in
path '/user/:id'
goroutine 1 [running]:
github.com/cch123/httprouter.(*node).insertChild(0xc4200801e0, 0
xc42004fc01, 0x126b177, 0x3, 0x126b171, 0x9, 0x127b668)
/Users/caochunhui/go_work/src/github.com/cch123/httprouter/tre
e.go:256 +0x841
github.com/cch123/httprouter.(*node).addRoute(0xc4200801e0, 0x12
6b171, 0x9, 0x127b668)
/Users/caochunhui/go_work/src/github.com/cch123/httprouter/tre
e.go:221 +0x22a
github.com/cch123/httprouter.(*Router).Handle(0xc42004ff38, 0x12
6a39b, 0x3, 0x126b171, 0x9, 0x127b668)
/Users/caochunhui/go_work/src/github.com/cch123/httprouter/rou
ter.go:262 +0xc3
github.com/cch123/httprouter.(*Router).GET(0xc42004ff38, 0x126b1
71, 0x9, 0x127b668)
/Users/caochunhui/go_work/src/github.com/cch123/httprouter/rou
ter.go:193 +0x5e
main.main()
/Users/caochunhui/test/go_web/httprouter_learn2.go:18 +0xaf
exit status 2还有一点需要注意,因为httprouter考虑到字典树的深度,在初始化时会对参数的数 量进行限制,所以在路由中的参数数目不能超过255,否则会导致httprouter无法识 别后续的参数。不过这一点上也不用考虑太多,毕竟URI是人设计且给人来看的, 相信没有长得夸张的URI能在一条路径中带有200个以上的参数。
除支持路径中的wildcard参数之外,httprouter还可以支持 * 号来进行通配,不 过 * 号开头的参数只能放在路由的结尾,例如下面这样:
Pattern: /src/*filepath
/src/ filepath = ""
/src/somefile.go filepath = "somefile.go"
/src/subdir/somefile.go filepath = "subdir/somefile.go"这种设计在RESTful中可能不太常见,主要是为了能够使用httprouter来做简单的HTTP静态文件服务器。
除了正常情况下的路由支持,httprouter也支持对一些特殊情况下的回调函数进行定 制,例如404的时候:
r := httprouter.New()
r.NotFound = http.HandlerFunc(func(w http.ResponseWriter, r *htt
p.Request) {
w.Write([]byte("oh no, not found"))
})或者内部panic的时候:
r.PanicHandler = func(w http.ResponseWriter, r *http.Request, c
interface{}) {
log.Printf("Recovering from panic, Reason: %#v", c.(error))
w.WriteHeader(http.StatusInternalServerError)
w.Write([]byte(c.(error).Error()))
}目前开源界最为流行(star数最多)的Web框架gin使用的就是httprouter的变种。
原理
httprouter和众多衍生router使用的数据结构被称为压缩字典树(Radix Tree)。读者可能没有接触过压缩字典树,但对字典树(Trie Tree)应该有所耳闻。 
字典树常用来进行字符串检索,例如用给定的字符串序列建立字典树。对于目标字 符串,只要从根节点开始深度优先搜索,即可判断出该字符串是否曾经出现过,时 间复杂度为 O(n) ,n可以认为是目标字符串的长度。为什么要这样做?字符串本 身不像数值类型可以进行数值比较,两个字符串对比的时间复杂度取决于字符串长 度。如果不用字典树来完成上述功能,要对历史字符串进行排序,再利用二分查找 之类的算法去搜索,时间复杂度只高不低。可认为字典树是一种空间换时间的典型 做法。
普通的字典树有一个比较明显的缺点,就是每个字母都需要建立一个孩子节点,这 样会导致字典树的层数比较深,压缩字典树相对好地平衡了字典树的优点和缺点。下面是典型的压缩字典树结构:
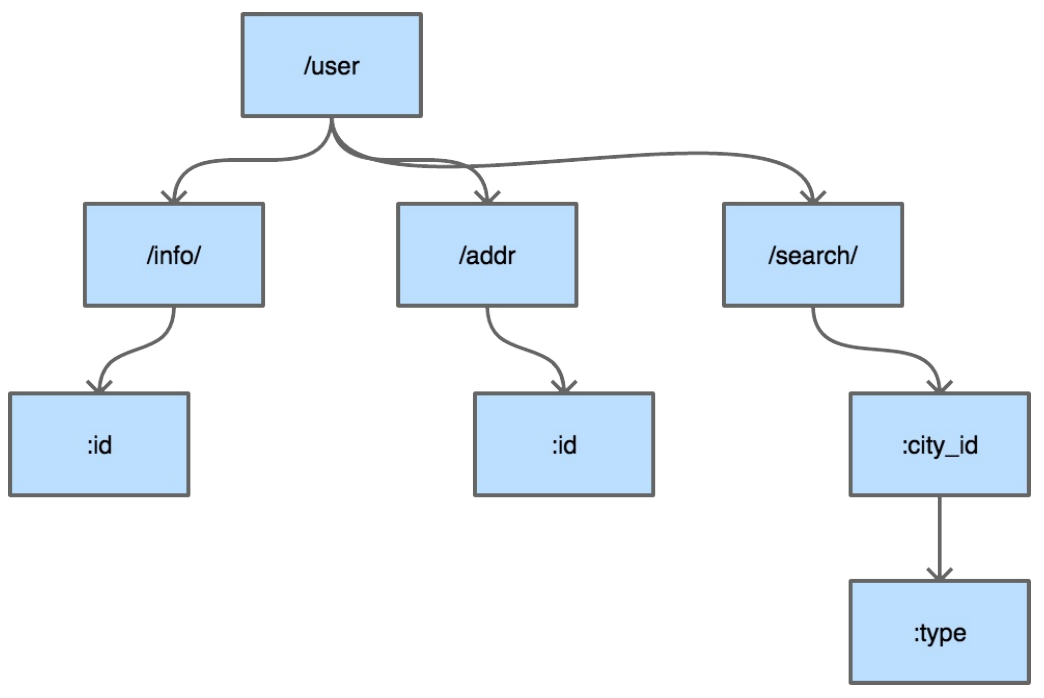
每个节点上不只存储一个字母了,这也是压缩字典树中“压缩”的主要含义。使用压 缩字典树可以减少树的层数,同时因为每个节点上数据存储也比通常的字典树要 多,所以程序的局部性较好(一个节点的path加载到cache即可进行多个字符的对 比),从而对CPU缓存友好。
压缩字典树创建过程
我们来跟踪一下httprouter中,一个典型的压缩字典树的创建过程,路由设定如下:
PUT /user/installations/:installation_id/repositories/:repositor
y_id
GET /marketplace_listing/plans/
GET /marketplace_listing/plans/:id/accounts
GET /search
GET /status
GET /support
补充路由:
GET /marketplace_listing/plans/ohyesroot 节点创建
httprouter的Router结构体中存储压缩字典树使用的是下述数据结构:
// 略去了其它部分的 Router struct
type Router struct {
// ...
trees map[string]*node
// ...
}trees 中的 key 即为HTTP 1.1的RFC中定义的各种方法,具体有:
GET
HEAD
OPTIONS
POST
PUT
PATCH
DELETE每一种方法对应的都是一棵独立的压缩字典树,这些树彼此之间不共享数据。具体 到我们上面用到的路由, PUT 和 GET 是两棵树而非一棵。 简单来讲,某个方法第一次插入的路由就会导致对应字典树的根节点被创建,我们按顺序,先是一个 PUT :
r := httprouter.New()
r.PUT("/user/installations/:installation_id/repositories/:reposit", Hello)这样 PUT 对应的根节点就会被创建出来。把这棵 PUT 的树画出来:  radix的节点类型为 *httprouter.node ,为了说明方便,我们留下了目前关心的几个字段:
radix的节点类型为 *httprouter.node ,为了说明方便,我们留下了目前关心的几个字段:
path: 当前节点对应的路径中的字符串
wildChild: 子节点是否为参数节点,即 wildcard node,或者说 :id 这种类型的节点
nType: 当前节点类型,有四个枚举值: 分别为 static/root/param/catchAll。
static // 非根节点的普通字符串节点
root // 根节点
param // 参数节点,例如 :id
catchAll // 通配符节点,例如 *anyway
indices:子节点索引,当子节点为非参数类型,即本节点的wildChild为false时,
会将每个子节点的首字母放在该索引数组。说是数组,实际上是个string。当然, PUT 路由只有唯一的一条路径。接下来,我们以后续的多条GET路径为例,讲解子节点的插入过程。
子节点插入
当插入 GET /marketplace_listing/plans 时,类似前面PUT的过程,GET树的结构如图  因为第一个路由没有参数,path都被存储到根节点上了。所以只有一个节点。然后插入 GET /marketplace_listing/plans/:id/accounts ,新的路径与之前 的路径有共同的前缀,且可以直接在之前叶子节点后进行插入,那么结果也很简单
因为第一个路由没有参数,path都被存储到根节点上了。所以只有一个节点。然后插入 GET /marketplace_listing/plans/:id/accounts ,新的路径与之前 的路径有共同的前缀,且可以直接在之前叶子节点后进行插入,那么结果也很简单 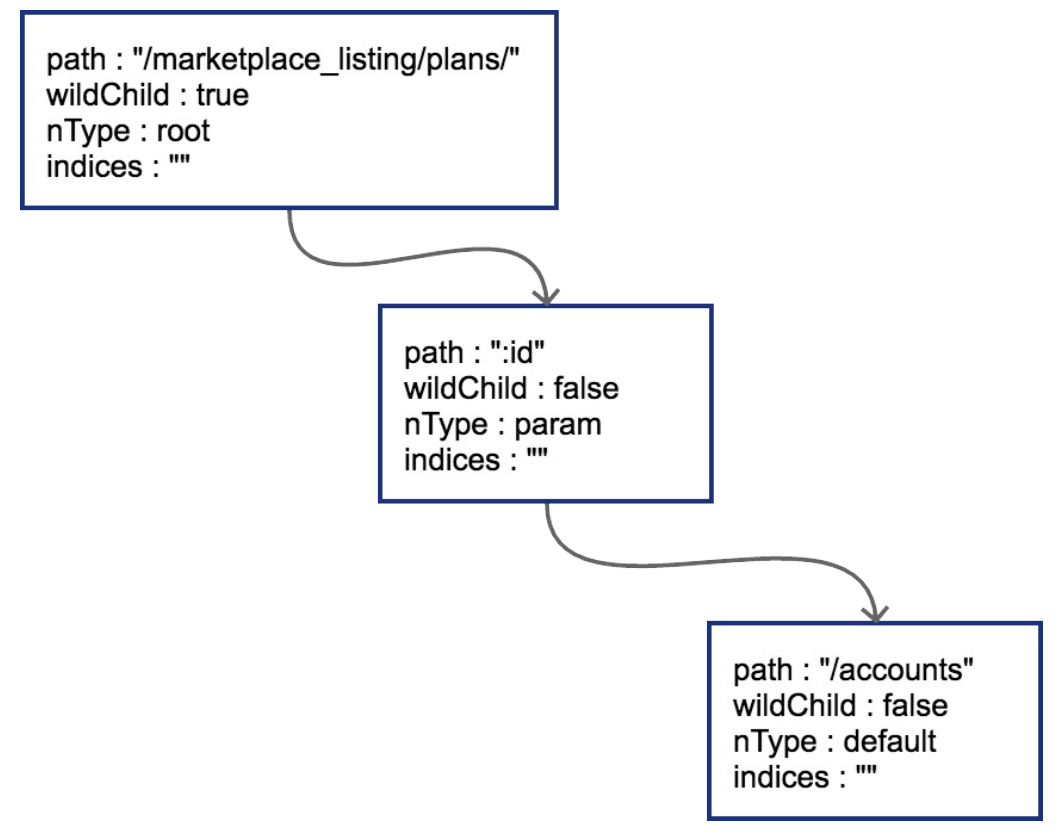 由于 :id 这个节点只有一个字符串的普通子节点,所以indices还依然不需要处 理。上面这种情况比较简单,新的路由可以直接作为原路由的子节点进行插入。实际情况不会这么美好。
由于 :id 这个节点只有一个字符串的普通子节点,所以indices还依然不需要处 理。上面这种情况比较简单,新的路由可以直接作为原路由的子节点进行插入。实际情况不会这么美好。
边分裂
接下来我们插入 GET /search ,这时会导致树的边分裂 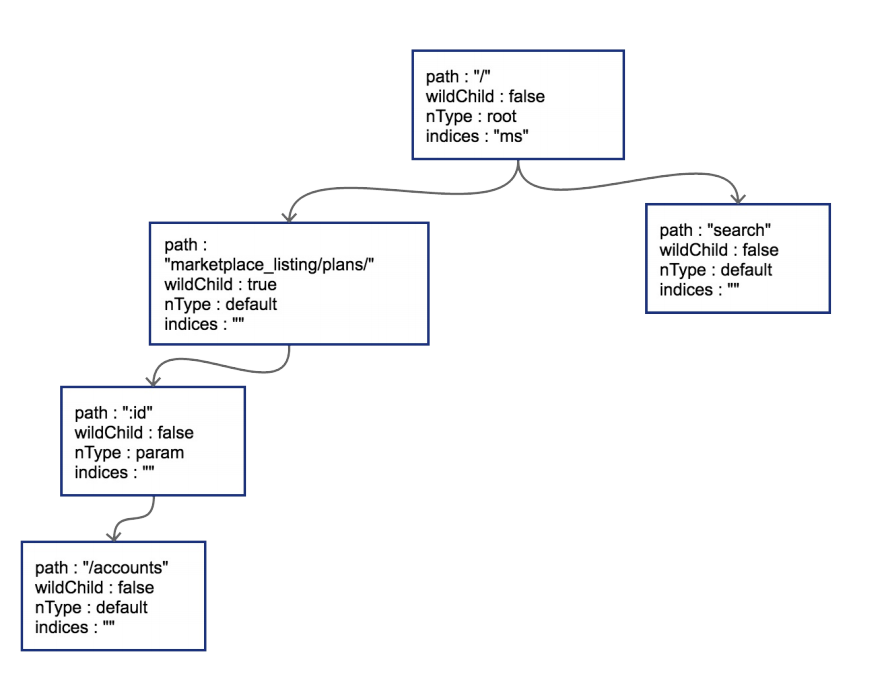
原有路径和新的路径在初始的 / 位置发生分裂,这样需要把原有的root节点内容下 移,再将新路由 search 同样作为子节点挂在root节点之下。这时候因为子节点出 现多个,root节点的indices提供子节点索引,这时候该字段就需要派上用场 了。"ms"代表子节点的首字母分别为m(marketplace)和s(search)。 我们一口作气,把 GET /status 和 GET /support 也插入到树中。这时候会导致 在 search 节点上再次发生分裂 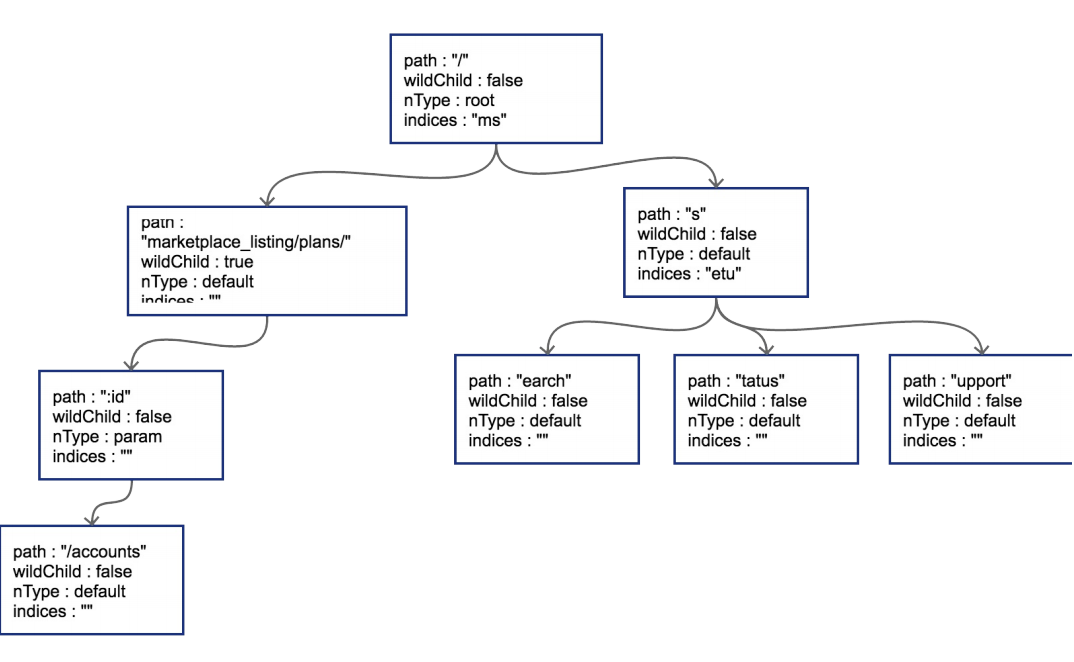
子节点冲突处理
在路由本身只有字符串的情况下,不会发生任何冲突。只有当路由中含有 wildcard(类似 :id)或者catchAll的情况下才可能冲突。这一点在前面已经提到 了。 子节点的冲突处理很简单,分几种情况:
1. 在插入wildcard节点时,父节点的children数组非空且wildChild被设置为false。
例如: GET /user/getAll 和 GET /user/:id/getAddr ,或者 GET
/user/*aaa 和 GET /user/:id 。
2. 在插入wildcard节点时,父节点的children数组非空且wildChild被设置为true,但该父节点的wildcard子节点要插入的wildcard名字不一样。例如: GET/user/:id/info 和 GET /user/:name/info 。
3. 在插入catchAll节点时,父节点的children非空。例如: GET
/src/abc 和 GET /src/*filename ,或者 GET /src/:id 和 GET
/src/*filename 。
4. 在插入static节点时,父节点的wildChild字段被设置为true。
5. 在插入static节点时,父节点的children非空,且子节点nType为catchAll。只要发生冲突,都会在初始化的时候panic。例如,在插入我们臆想的路由 GET /marketplace_listing/plans/ohyes 时,出现第4种冲突情况:它的父节 点 marketplace_listing/plans/ 的wildChild字段为true。
中间件
代码泥潭
// middleware/hello.go
package main
func hello(wr http.ResponseWriter, r *http.Request) {
wr.Write([]byte("hello"))
}
func main() {
http.HandleFunc("/", hello)
err := http.ListenAndServe(":8080", nil)
...
}这是一个典型的Web服务,挂载了一个简单的路由。我们的线上服务一般也是从这 样简单的服务开始逐渐拓展开去的。 现在突然来了一个新的需求,我们想要统计之前写的hello服务的处理耗时,需求很 简单,我们对上面的程序进行少量修改:
// middleware/hello_with_time_elapse.go
var logger = log.New(os.Stdout, "", 0)
func hello(wr http.ResponseWriter, r *http.Request) {
timeStart := time.Now()
wr.Write([]byte("hello"))
timeElapsed := time.Since(timeStart)
logger.Println(timeElapsed)
}这样便可以在每次接收到http请求时,打印出当前请求所消耗的时间。 完成了这个需求之后,我们继续进行业务开发,提供的API逐渐增加,现在我们的 路由看起来是这个样子:
// middleware/hello_with_more_routes.go
// 省略了一些相同的代码
package main
func helloHandler(wr http.ResponseWriter, r *http.Request) {
// ...
}
func showInfoHandler(wr http.ResponseWriter, r *http.Request) {
// ...
}
func showEmailHandler(wr http.ResponseWriter, r *http.Request) {
// ...
}
func showFriendsHandler(wr http.ResponseWriter, r *http.Request)
{
timeStart := time.Now()
wr.Write([]byte("your friends is tom and alex"))
timeElapsed := time.Since(timeStart)
logger.Println(timeElapsed)
}
func main() {
http.HandleFunc("/", helloHandler)
http.HandleFunc("/info/show", showInfoHandler)
http.HandleFunc("/email/show", showEmailHandler)
http.HandleFunc("/friends/show", showFriendsHandler)
// ...
}每一个handler里都有之前提到的记录运行时间的代码,每次增加新的路由我们也同 样需要把这些看起来长得差不多的代码拷贝到我们需要的地方去。因为代码不太 多,所以实施起来也没有遇到什么大问题。 渐渐的我们的系统增加到了30个路由和 handler 函数,每次增加新的handler,我 们的第一件工作就是把之前写的所有和业务逻辑无关的周边代码先拷贝过来。
接下来系统安稳地运行了一段时间,突然有一天,老板找到你,我们最近找人新开 发了监控系统,为了系统运行可以更加可控,需要把每个接口运行的耗时数据主动 上报到我们的监控系统里。给监控系统起个名字吧,叫metrics。现在你需要修改代 码并把耗时通过HTTP Post的方式发给metrics系统了。我们来修改一 下 helloHandler() :
func helloHandler(wr http.ResponseWriter, r *http.Request) {
timeStart := time.Now()
wr.Write([]byte("hello"))
timeElapsed := time.Since(timeStart)
logger.Println(timeElapsed)
// 新增耗时上报
metrics.Upload("timeHandler", timeElapsed)
}修改到这里,本能地发现我们的开发工作开始陷入了泥潭。无论未来对我们的这个 Web系统有任何其它的非功能或统计需求,我们的修改必然牵一发而动全身。只要 增加一个非常简单的非业务统计,我们就需要去几十个handler里增加这些业务无关 的代码。虽然一开始我们似乎并没有做错,但是显然随着业务的发展,我们的行事 方式让我们陷入了代码的泥潭。
使用中间件剥离非业务逻辑
我们犯的最大的错误,是把业务代码和非业务代码揉在了一起。对于大多数的场景来讲,非业务的需求都是在http请求处理前做一些事情,并且在响应完成之后做一些事情。我们有没有办法使用一些重构思路把这些公共的非业务功能代码剥离出去呢?回到刚开头的例子,我们需要给我们的 helloHandler() 增加超时时间统计,我们可以使用一种叫 function adapter 的方法来对 helloHandler() 进行包装:
func hello(wr http.ResponseWriter, r *http.Request) {
wr.Write([]byte("hello"))
}
func timeMiddleware(next http.Handler) http.Handler {
return http.HandlerFunc(func(wr http.ResponseWriter, r *http
.Request) {
timeStart := time.Now()
// next handler
next.ServeHTTP(wr, r)
timeElapsed := time.Since(timeStart)
logger.Println(timeElapsed)
})
}
func main() {
http.Handle("/", timeMiddleware(http.HandlerFunc(hello)))
err := http.ListenAndServe(":8080", nil)
...
}这样就非常轻松地实现了业务与非业务之间的剥离,魔法就在于这 个 timeMiddleware 。可以从代码中看到,我们的 timeMiddleware() 也是一个 函数,其参数为 http.Handler , http.Handler 的定义在 net/http 包中:
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}任何方法实现了 ServeHTTP ,即是一个合法的 http.Handler ,读到这里你可能会有一些混乱,我们先来梳理一下http库的 Handler , HandlerFunc 和 ServeHTTP 的关系:
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
type HandlerFunc func(ResponseWriter, *Request)
func (f HandlerFunc) ServeHTTP(w ResponseWriter, r *Request) {
f(w, r)
}只要你的handler函数签名是:
func (ResponseWriter, *Request)那么这个 handler 和 http.HandlerFunc() 就有了一致的函数签名,可以将 该 handler() 函数进行类型转换,转为 http.HandlerFunc 。 而 http.HandlerFunc 实现了 http.Handler 这个接口。在 http 库需要调用你 的handler函数来处理http请求时,会调用 HandlerFunc() 的 ServeHTTP() 函 数,可见一个请求的基本调用链是这样的:
h = getHandler() => h.ServeHTTP(w, r) => h(w, r)上面提到的把自定义 handler 转换为 http.HandlerFunc() 这个过程是必须 的,因为我们的 handler 没有直接实现 ServeHTTP 这个接口。上面的代码中我 们看到的HandleFunc(注意HandlerFunc和HandleFunc的区别)里也可以看到这个强制转换过程:
func HandleFunc(pattern string, handler func(ResponseWriter, *Re
quest)) {
DefaultServeMux.HandleFunc(pattern, handler)
}
// 调用
func (mux *ServeMux) HandleFunc(pattern string, handler func(Res
ponseWriter, *Request)) {
mux.Handle(pattern, HandlerFunc(handler))
}知道handler是怎么一回事,我们的中间件通过包装handler,再返回一个新的handler就好理解了。
总结一下,我们的中间件要做的事情就是通过一个或多个函数对handler进行包装, 返回一个包括了各个中间件逻辑的函数链。我们把上面的包装再做得复杂一些:
customizedHandler = logger(timeout(ratelimit(helloHandler)))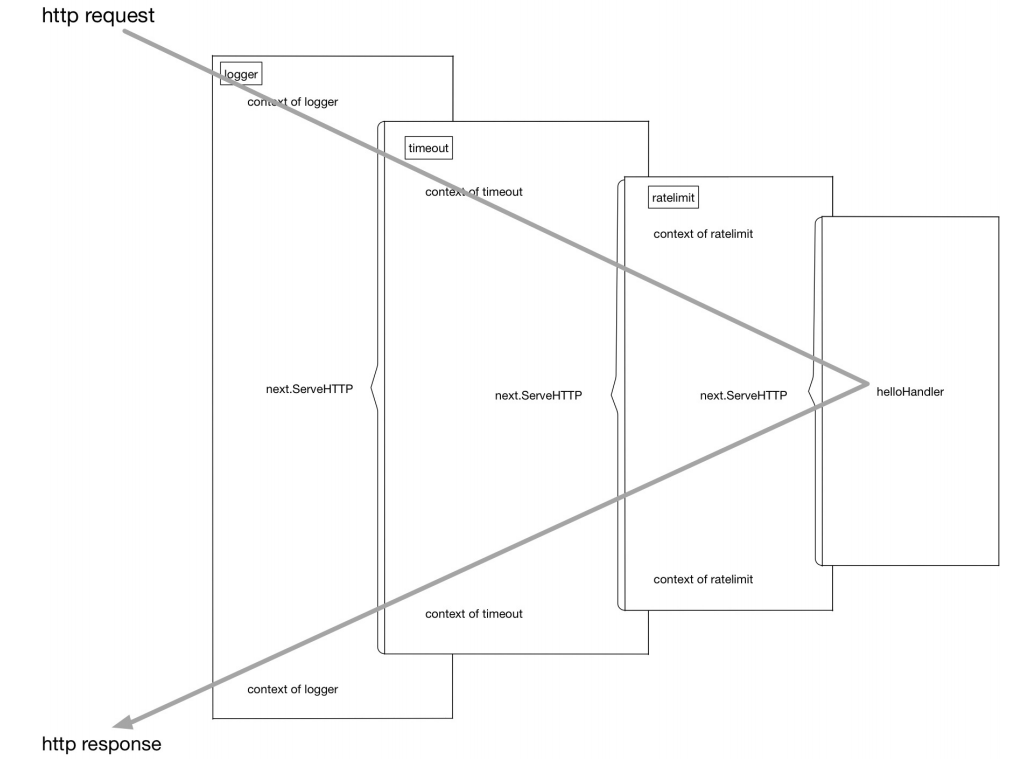 再直白一些,这个流程在进行请求处理的时候就是不断地进行函数压栈再出栈,有 一些类似于递归的执行流:
再直白一些,这个流程在进行请求处理的时候就是不断地进行函数压栈再出栈,有 一些类似于递归的执行流:
[exec of logger logic] 函数栈: []
[exec of timeout logic] 函数栈: [logger]
[exec of ratelimit logic] 函数栈: [timeout/logger]
[exec of helloHandler logic] 函数栈: [ratelimit/timeout/logge
r]
[exec of ratelimit logic part2] 函数栈: [timeout/logger]
[exec of timeout logic part2] 函数栈: [logger]
[exec of logger logic part2] 函数栈: []功能实现了,但在上面的使用过程中我们也看到了,这种函数套函数的用法不是很 美观,同时也不具备什么可读性。
更优雅的中间件写法
看一个例子:
r = NewRouter()
r.Use(logger)
r.Use(timeout)
r.Use(ratelimit)
r.Add("/", helloHandler)通过多步设置,我们拥有了和上一节差不多的执行函数链。胜在直观易懂,如果我 们要增加或者删除中间件,只要简单地增加删除对应的 Use() 调用就可以了。非 常方便。 从框架的角度来讲,怎么实现这样的功能呢?也不复杂:
type middleware func(http.Handler) http.Handler
type Router struct {
middlewareChain [] middleware
mux map[string] http.Handler
}
func NewRouter() *Router{
return &Router{}
}
func (r *Router) Use(m middleware) {
r.middlewareChain = append(r.middlewareChain, m)
}
func (r *Router) Add(route string, h http.Handler) {
var mergedHandler = h
for i := len(r.middlewareChain) - 1; i >= 0; i-- {
mergedHandler = r.middlewareChain[i](mergedHandler)
}
r.mux[route] = mergedHandler
}注意代码中的 middleware 数组遍历顺序,和用户希望的调用顺序应该是"相 反"的。应该不难理解。
哪些事情适合在中间件中做
以较流行的开源Go语言框架chi为例:
compress.go
=> 对http的响应体进行压缩处理
heartbeat.go
=> 设置一个特殊的路由,例如/ping,/healthcheck,用来给负载均衡一类的前置服务进行探活
logger.go
=> 打印请求处理处理日志,例如请求处理时间,请求路由
profiler.go
=> 挂载pprof需要的路由,如`/pprof`、`/pprof/trace`到系统中
realip.go
=> 从请求头中读取X-Forwarded-For和X-Real-IP,将http.Request中的RemoteAddr修改为得到的
RealIPrequestid.go
=> 为本次请求生成单独的requestid,可一路透传,用来生成分布式调用链路,也可用于在日志中串连单次请求的所有逻辑
timeout.go
=> 用context.Timeout设置超时时间,并将其通过http.Request一路透传下去
throttler.go
=> 通过定长大小的channel存储token,并通过这些token对接口进行限流每一个Web框架都会有对应的中间件组件,如果你有兴趣,也可以向这些项目贡献 有用的中间件,只要合理一般项目的维护人也愿意合并你的Pull Request。 比如开源界很火的gin这个框架,就专门为用户贡献的中间件开了一个仓库
validator请求校验
重构请求校验函数
假设我们的数据已经通过某个开源绑定库绑定到了具体的结构体上。
type RegisterReq struct {
Username string `json:"username"`
PasswordNew string `json:"password_new"`
PasswordRepeat string `json:"password_repeat"`
Email string `json:"email"`
}
func register(req RegisterReq) error{
if len(req.Username) > 0 {
if len(req.PasswordNew) > 0 && len(req.PasswordRepeat) >
0 {
if req.PasswordNew == req.PasswordRepeat {
if emailFormatValid(req.Email) {
createUser()
return nil
} else {
return errors.New("invalid email")
}
} else {
return errors.New("password and reinput must be
the same")
}
} else {
return errors.New("password and password reinput mus
t be longer than 0")
}
} else {
return errors.New("length of username cannot be 0")
}
}我们用Go里成功写出了波动拳开路的箭头型代码。。这种代码一般怎么进行优化呢?
func register(req RegisterReq) error{
if len(req.Username) == 0 {
return errors.New("length of username cannot be 0")
}
if len(req.PasswordNew) == 0 || len(req.PasswordRepeat) == 0
{
return errors.New("password and password reinput must be
longer than 0")
}
if req.PasswordNew != req.PasswordRepeat {
return errors.New("password and reinput must be the same"
)
}
if emailFormatValid(req.Email) {
return errors.New("invalid email")
}
createUser()
return nil
}代码更清爽,看起来也不那么别扭了。这是比较通用的重构理念。虽然使用了重构 方法使我们的校验过程代码看起来优雅了,但我们还是得为每一个 http 请求都去 写这么一套差不多的 validate() 函数,有没有更好的办法来帮助我们解除这项 体力劳动?答案就是validator。
用validator解放体力劳动
从设计的角度讲,我们一定会为每个请求都声明一个结构体。前文中提到的校验场 景我们都可以通过validator完成工作。还以前文中的结构体为例。为了美观起见, 我们先把json tag省略掉。 这里我们引入一个新的validator库:
import "gopkg.in/go-playground/validator.v9"
type RegisterReq struct {
// 字符串的 gt=0 表示长度必须 > 0,gt = greater than
Username string `validate:"gt=0"`
// 同上
PasswordNew string `validate:"gt=0"`
// eqfield 跨字段相等校验
PasswordRepeat string `validate:"eqfield=PasswordNew"`
// 合法 email 格式校验
Email string `validate:"email"`
}
validate := validator.New()
func validate(req RegisterReq) error {
err := validate.Struct(req)
if err != nil {
doSomething()
return err
}
...
}这样就不需要在每个请求进入业务逻辑之前都写重复的 validate() 函数了。本 例中只列出了这个校验器非常简单的几个功能。 我们试着跑一下这个程序,输入参数设置为:
//...
var req = RegisterReq {
Username : "Xargin",
PasswordNew : "ohno",
PasswordRepeat : "ohn",
Email : "alex@abc.com",
}
err := validate(req)
fmt.Println(err)
// Key: 'RegisterReq.PasswordRepeat' Error:Field validation for
// 'PasswordRepeat' failed on the 'eqfield' tag如果觉得这个 validator 提供的错误信息不够人性化,例如要把错误信息返回给 用户,那就不应该直接显示英文了。可以针对每种tag进行错误信息定制,读者可以 自行探索。
原理
从结构上来看,每一个结构体都可以看成是一棵树。假如我们有如下定义的结构体:
type Nested struct {
Email string `validate:"email"`
}
type T struct {
Age int `validate:"eq=10"`
Nested Nested
}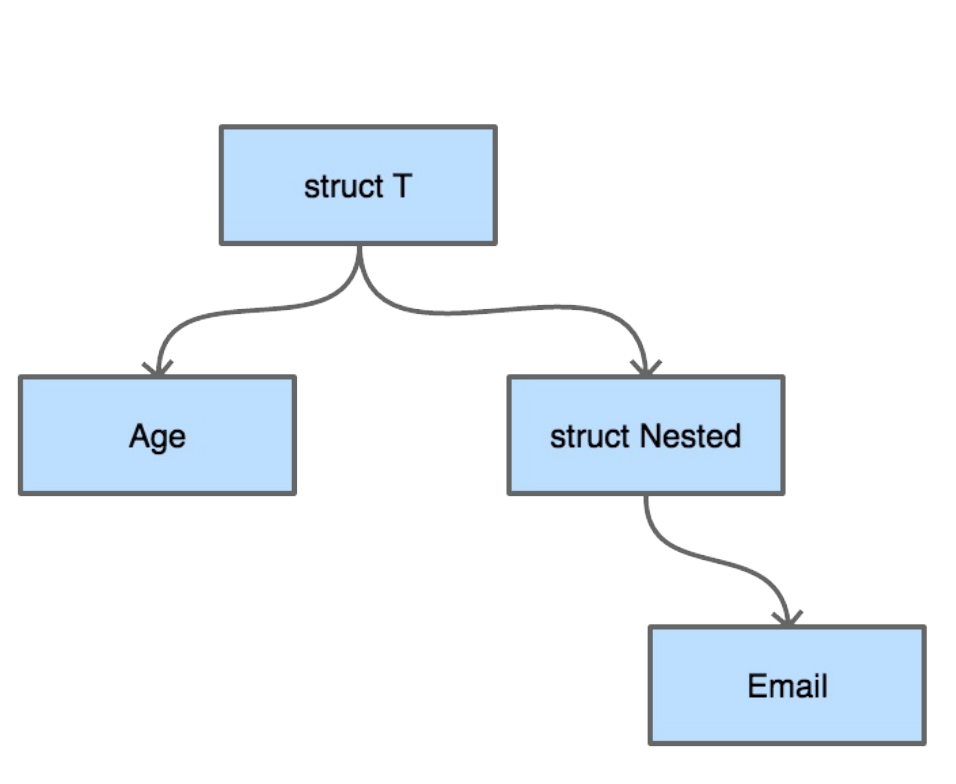 从字段校验的需求来讲,无论我们采用深度优先搜索还是广度优先搜索来对这棵结构体树来进行遍历,都是可以的。
从字段校验的需求来讲,无论我们采用深度优先搜索还是广度优先搜索来对这棵结构体树来进行遍历,都是可以的。
package main
import (
"fmt"
"reflect"
"regexp"
"strconv"
"strings"
)
type Nested struct {
Email string `validate:"email"`
}
type T struct {
Age int `validate:"eq=10"`
Nested Nested
}
func validateEmail(input string) bool {
if pass, _ := regexp.MatchString(
`^([\w\.\_]{2,10})@(\w{1,}).([a-z]{2,4})$`, input,
); pass {
return true
}
return false
}
func validate(v interface{}) (bool, string) {
validateResult := true
errmsg := "success"
vt := reflect.TypeOf(v)
vv := reflect.ValueOf(v)
for i := 0; i < vv.NumField(); i++ {
fieldVal := vv.Field(i)
tagContent := vt.Field(i).Tag.Get("validate")
k := fieldVal.Kind()
switch k {
case reflect.Int:
val := fieldVal.Int()
tagValStr := strings.Split(tagContent, "=")
tagVal, _ := strconv.ParseInt(tagValStr[1], 10, 64)
if val != tagVal {
errmsg = "validate int failed, tag is: "+ strcon
v.FormatInt(
tagVal, 10,
)
validateResult = false
}
case reflect.String:
val := fieldVal.String()
tagValStr := tagContent
switch tagValStr {
case "email":
nestedResult := validateEmail(val)
if nestedResult == false {
errmsg = "validate mail failed, field val is
: "+ val
validateResult = false
}
}
case reflect.Struct:
// 如果有内嵌的 struct,那么深度优先遍历
// 就是一个递归过程
valInter := fieldVal.Interface()
nestedResult, msg := validate(valInter)
if nestedResult == false {
validateResult = false
errmsg = msg
}
}
}
return validateResult, errmsg
}
func main() {
var a = T{Age: 10, Nested: Nested{Email: "abc@abc.com"}}
validateResult, errmsg := validate(a)
fmt.Println(validateResult, errmsg)
}这里我们简单地对 eq=x 和 email 这两个tag进行了支持,读者可以对这个程序进 行简单的修改以查看具体的validate效果。为了演示精简掉了错误处理和复杂情况 的处理,例如 reflect.Int8/16/32/64 , reflect.Ptr 等类型的处理,如果给 生产环境编写校验库的话,请务必做好功能的完善和容错
原 理很简单,就是用反射对结构体进行树形遍历。有心的读者这时候可能会产生一个 问题,我们对结构体进行校验时大量使用了反射,而Go的反射在性能上不太出众, 有时甚至会影响到我们程序的性能。这样的考虑确实有一些道理,但需要对结构体 进行大量校验的场景往往出现在Web服务,这里并不一定是程序的性能瓶颈所在, 实际的效果还是要从pprof中做更精确的判断。
如果基于反射的校验真的成为了你服务的性能瓶颈怎么办?现在也有一种思路可以 避免反射:使用Go内置的Parser对源代码进行扫描,然后根据结构体的定义生成校 验代码。我们可以将所有需要校验的结构体放在单独的包内。这就交给读者自己去 探索了。
Database 和数据库打交道
从 database/sql 讲起
Go官方提供了 database/sql 包来给用户进行和数据库打交道的工 作, database/sql 库实际只提供了一套操作数据库的接口和规范,例如抽象好的SQL预处理(prepare),连接池管理,数据绑定,事务,错误处理等等。官方并没有提供具体某种数据库实现的协议支持。
和具体的数据库,例如MySQL打交道,还需要再引入MySQL的驱动,像下面这 样:
import "database/sql"
import _ "github.com/go-sql-driver/mysql"
db, err := sql.Open("mysql", "user:password@/dbname")import _ "github.com/go-sql-driver/mysql"这条import语句会调用了 mysql 包的 init 函数,做的事情也很简单:
func init() {
sql.Register("mysql", &MySQLDriver{})
}在 sql 包的全局 map 里把 mysql 这个名字的 driver 注册 上。 Driver 在 sql 包中是一个接口:
type Driver interface {
Open(name string) (Conn, error)
}调用 sql.Open() 返回的 db 对象就是这里的 Conn 。
type Conn interface {
Prepare(query string) (Stmt, error)
Close() error
Begin() (Tx, error)
}也是一个接口。如果你仔细地查看 database/sql/driver/driver.go 的代码会 发现,这个文件里所有的成员全都是接口,对这些类型进行操作,还是会调用具体 的 driver 里的方法。
从用户的角度来讲,在使用 database/sql 包的过程中,你能够使用的也就是这 些接口里提供的函数。来看一个使用 database/sql 和 go-sql-driver/mysql 的完整的例子:
package main
import (
"database/sql"
_ "github.com/go-sql-driver/mysql"
)
func main() {
// db 是一个 sql.DB 类型的对象
// 该对象线程安全,且内部已包含了一个连接池
// 连接池的选项可以在 sql.DB 的方法中设置,这里为了简单省略了
db, err := sql.Open("mysql",
"user:password@tcp(127.0.0.1:3306)/hello")
if err != nil {
log.Fatal(err)
}
defer db.Close()
var (
id int
name string
)
rows, err := db.Query("select id, name from users where id =
?", 1)
if err != nil {
log.Fatal(err)
}
defer rows.Close()
// 必须要把 rows 里的内容读完,或者显式调用 Close() 方法,
// 否则在 defer 的 rows.Close() 执行之前,连接永远不会释放
for rows.Next() {
err := rows.Scan(&id, &name)
if err != nil {
log.Fatal(err)
}
log.Println(id, name)
}
err = rows.Err()
if err != nil {
log.Fatal(err)
}
}如果读者想了解官方这个 database/sql 库更加详细的用法的话,可以参 考 http://go-database-sql.org/ 。 包括该库的功能介绍、用法、注意事项和反直觉的一些实现方式(例如同一个 goroutine内对 sql.DB 的查询,可能在多个连接上)都有涉及
聪明如你的话,在上面这段简短的程序中可能已经嗅出了一些不好的味道。官方 的 db 库提供的功能这么简单,我们每次去数据库里读取内容岂不是都要去写这么 一套差不多的代码?或者如果我们的对象是结构体,把 sql.Rows 绑定到对象的工 作就会变得更加得重复而无聊。
是的,所以社区才会有各种各样的SQL Builder和ORM百花齐放。
提高生产效率的ORM和SQL Builder
在Web开发领域常常提到的ORM是什么?我们先看看万能的维基百科:
对象关系映射(英语:Object Relational Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序设计技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换。
从效果上说,它其实是创建了一个可在编程语言里使用的“虚拟对象数据库”。最为常见的ORM做的是从db到程序的类或结构体这样的映射。所以你手边的程序 可能是从MySQL的表映射你的程序内的类。我们可以先来看看其它的程序语言里的 ORM写起来是怎么样的感觉:
>>> from blog.models import Blog
>>> b = Blog(name='Beatles Blog', tagline='All the latest Beatle
s news.')
>>> b.save()完全没有数据库的痕迹,没错,ORM的目的就是屏蔽掉DB层,很多语言的ORM只 要把你的类或结构体定义好,再用特定的语法将结构体之间的一对一或者一对多关 系表达出来。那么任务就完成了。然后你就可以对这些映射好了数据库表的对象进 行各种操作,例如save,create,retrieve,delete。至于ORM在背地里做了什么阴 险的勾当,你是不一定清楚的。使用ORM的时候,我们往往比较容易有一种忘记了 数据库的直观感受。举个例子,我们有个需求:向用户展示最新的商品列表,我们 再假设,商品和商家是1:1的关联关系,我们就很容易写出像下面这样的代码:
# 伪代码
shopList := []
for product in productList {
shopList = append(shopList, product.GetShop)
}当然了,我们不能批判这样写代码的程序员是偷懒的程序员。因为ORM一类的工具 在出发点上就是屏蔽sql,让我们对数据库的操作更接近于人类的思维方式。这样很 多只接触过ORM而且又是刚入行的程序员就很容易写出上面这样的代码。 这样的代码将对数据库的读请求放大了N倍。也就是说,如果你的商品列表有15个 SKU,那么每次用户打开这个页面,至少需要执行1(查询商品列表)+ 15(查询 相关的商铺信息)次查询。这里N是16。如果你的列表页很大,比如说有600个条 目,那么你就至少要执行1+600次查询。如果说你的数据库能够承受的最大的简单 查询是12万QPS,而上述这样的查询正好是你最常用的查询的话,你能对外提供的 服务能力是多少呢?是200 qps!互联网系统的忌讳之一,就是这种无端的读放 大。 当然,你也可以说这不是ORM的问题,如果你手写sql你还是可能会写出差不多的 程序,那么再来看两个demo:
o := orm.NewOrm()
num, err := o.QueryTable("cardgroup").Filter("Cards__Card__Name"
, cardName).All(&cardgroups)很多ORM都提供了这种Filter类型的查询方式,不过在某些ORM背后可能隐藏了非 常难以察觉的细节,比如生成的SQL语句会自动 limit 1000 。
也许喜欢ORM的读者读到这里会反驳了,你是没有认真阅读文档就瞎写。是的,尽 管这些ORM工具在文档里说明了All查询在不显式地指定Limit的话会自动limit 1000,但对于很多没有阅读过文档或者看过ORM源码的人,这依然是一个非常难 以察觉的“魔鬼”细节。喜欢强类型语言的人一般都不喜欢语言隐式地去做什么事 情,例如各种语言在赋值操作时进行的隐式类型转换然后又在转换中丢失了精度的 勾当,一定让你非常的头疼。所以一个程序库背地里做的事情还是越少越好,如果 一定要做,那也一定要在显眼的地方做。比如上面的例子,去掉这种默认的自作聪 明的行为,或者要求用户强制传入limit参数都是更好的选择。 除了limit的问题,我们再看一遍这个下面的查询:
num, err := o.QueryTable("cardgroup").Filter("Cards__Card__Name" , cardName).All(&cardgroups)你可以看得出来这个Filter是有表join的操作么?当然了,有深入使用经验的用户还 是会觉得这是在吹毛求疵。但这样的分析想证明的是,ORM想从设计上隐去太多的 细节。而方便的代价是其背后的运行完全失控。这样的项目在经过几任维护人员之 后,将变得面目全非,难以维护。
当然,我们不能否认ORM的进步意义,它的设计初衷就是为了让数据的操作和存储 的具体实现相剥离。但是在上了规模的公司的人们渐渐达成了一个共识,由于隐藏 重要的细节,ORM可能是失败的设计。其所隐藏的重要细节对于上了规模的系统开 发来说至关重要。
相比ORM来说,SQL Builder在SQL和项目可维护性之间取得了比较好的平衡。首 先sql builder不像ORM那样屏蔽了过多的细节,其次从开发的角度来讲,SQL Builder进行简单封装后也可以非常高效地完成开发,举个例子:
where := map[string]interface{} {
"order_id > ?" : 0,
"customer_id != ?" : 0,
}
limit := []int{0,100}
orderBy := []string{"id asc", "create_time desc"}
orders := orderModel.GetList(where, limit, orderBy)写SQL Builder的相关代码,或者读懂都不费劲。把这些代码脑内转换为sql也不会 太费劲。所以通过代码就可以对这个查询是否命中数据库索引,是否走了覆盖索 引,是否能够用上联合索引进行分析了。
说白了SQL Builder是sql在代码里的一种特殊方言,如果你们没有DBA但研发有自 己分析和优化sql的能力,或者你们公司的DBA对于学习这样一些sql的方言没有异 议。那么使用SQL Builder是一个比较好的选择,不会导致什么问题。
另外在一些本来也不需要DBA介入的场景内,使用SQL Builder也是可以的,例如 你要做一套运维系统,且将MySQL当作了系统中的一个组件,系统的QPS不高, 查询不复杂等等。
一旦你做的是高并发的OLTP在线系统,且想在人员充足分工明确的前提下最大程 度控制系统的风险,使用SQL Builder就不合适了。
脆弱的数据库
无论是ORM还是SQL Builder都有一个致命的缺点,就是没有办法进行系统上线的 事前sql审核。虽然很多ORM和SQL Builder也提供了运行期打印sql的功能,但只在 查询的时候才能进行输出。而SQL Builder和ORM本身提供的功能太过灵活。使得 你不可能通过测试枚举出所有可能在线上执行的sql。例如你可能用SQL Builder写 出下面这样的代码:
where := map[string]interface{} {
"product_id = ?" : 10,
"user_id = ?" : 1232 ,
}
if order_id != 0 {
where["order_id = ?"] = order_id
}
res, err := historyModel.GetList(where, limit, orderBy)你的系统里有大量类似上述样例的 if 的话,就难以通过测试用例来覆盖到所有可 能的sql组合了。这样的系统只要发布,就已经孕育了初期的巨大风险。
对于现在7乘24服务的互联网公司来说,服务不可用是非常重大的问题。存储层的 技术栈虽经历了多年的发展,在整个系统中依然是最为脆弱的一环。系统宕机对于 24小时对外提供服务的公司来说,意味着直接的经济损失。个中风险不可忽视。
从行业分工的角度来讲,现今的互联网公司都有专职的DBA。大多数DBA并不一定 有写代码的能力,去阅读SQL Builder的相关“拼SQL”代码多多少少还是会有一点障 碍。从DBA角度出发,还是希望能够有专门的事前SQL审核机制,并能让其低成本 地获取到系统的所有SQL内容,而不是去阅读业务研发编写的SQL Builder的相关代 码。
所以现如今,大型的互联网公司核心线上业务都会在代码中把SQL放在显眼的位置 提供给DBA评审,举一个例子:
const ( getAllByProductIDAndCustomerID = `select * from p_orders whe re product_id in (:product_id) and customer_id=:customer_id` )
// GetAllByProductIDAndCustomerID
// @param driver_id
// @param rate_date
// @return []Order, error
func GetAllByProductIDAndCustomerID(ctx context.Context, product IDs []uint64, customerID uint64) ([]Order, error) {
var orderList []
Order params := map[string]interface{}{
"product_id" : productIDs,
"customer_id": customerID,
}
// getAllByProductIDAndCustomerID 是 const 类型的 sql 字符串
sql, args, err := sqlutil.Named(getAllByProductIDAndCustomer ID, params)
if err != nil { return nil, err }
err = dao.QueryList(ctx, sqldbInstance, sql, args, &orderLis t)
if err != nil { return nil, err }
return orderList, err
}像这样的代码,在上线之前把DAO层的变更集的const部分直接拿给DBA来进行审 核,就比较方便了。代码中的 sqlutil.Named 是类似于 sqlx 中的 Named 函数,同 时支持 where 表达式中的比较操作符和 in。这里为了说明简便,函数写得稍微复杂一些,仔细思考一下的话查询的导出函数还 可以进一步进行简化。请读者朋友们自行尝试。
Ratelimit 服务流量限制
计算机程序可依据其瓶颈分为磁盘IO瓶颈型,CPU计算瓶颈型,网络带宽瓶颈型, 分布式场景下有时候也会外部系统而导致自身瓶颈。
Web系统打交道最多的是网络,无论是接收,解析用户请求,访问存储,还是把响 应数据返回给用户,都是要走网络的。在没有 epoll/kqueue 之类的系统提供的 IO多路复用接口之前,多个核心的现代计算机最头痛的是C10k问题,C10k问题会 导致计算机没有办法充分利用CPU来处理更多的用户连接,进而没有办法通过优化 程序提升CPU利用率来处理更多的请求。
自从Linux实现了 epoll ,FreeBSD实现了 kqueue ,这个问题基本解决了,我 们可以借助内核提供的API轻松解决当年的C10k问题,也就是说如今如果你的程序 主要是和网络打交道,那么瓶颈一定在用户程序而不在操作系统内核。
随着时代的发展,编程语言对这些系统调用又进一步进行了封装,如今做应用层开 发,几乎不会在程序中看到 epoll 之类的字眼,大多数时候我们就只要聚焦在业 务逻辑上就好。Go 的 net 库针对不同平台封装了不同的syscall API, http 库又 是构建在 net 库之上,所以在Go语言中我们可以借助标准库,很轻松地写出高性 能的 http 服务,下面是一个简单的 hello world 服务的代码:
package main
import (
"io"
"log"
"net/http"
)
func sayhello(wr http.ResponseWriter, r *http.Request) {
wr.WriteHeader(200)
io.WriteString(wr, "hello world")
}
func main() {
http.HandleFunc("/", sayhello)
err := http.ListenAndServe(":9090", nil)
if err != nil { log.Fatal("ListenAndServe:", err) }
}这里的 hello world 服务没有任何业务逻辑。真实环境的程序要复杂得多,有些 程序偏网络IO瓶颈,例如一些CDN服务、Proxy服务;有些程序偏CPU/GPU瓶颈, 例如登陆校验服务、图像处理服务;有些程序瓶颈偏磁盘,例如专门的存储系统, 数据库。不同的程序瓶颈会体现在不同的地方,这里提到的这些功能单一的服务相 对来说还算容易分析。如果碰到业务逻辑复杂代码量巨大的模块,其瓶颈并不是三 下五除二可以推测出来的,还是需要从压力测试中得到更为精确的结论。
对于IO/Network瓶颈类的程序,其表现是网卡/磁盘IO会先于CPU打满,这种情况 即使优化CPU的使用也不能提高整个系统的吞吐量,只能提高磁盘的读写速度,增 加内存大小,提升网卡的带宽来提升整体性能。而CPU瓶颈类的程序,则是在存储 和网卡未打满之前CPU占用率先到达100%,CPU忙于各种计算任务,IO设备相对 则较闲。
无论哪种类型的服务,在资源使用到极限的时候都会导致请求堆积,超时,系统 hang死,最终伤害到终端用户。对于分布式的Web服务来说,瓶颈还不一定总在系 统内部,也有可能在外部。非计算密集型的系统往往会在关系型数据库环节失守, 而这时候Web模块本身还远远未达到瓶颈。不管我们的服务瓶颈在哪里,最终要做的事情都是一样的,那就是流量限制。
常见的流量限制手段
流量限制的手段有很多,最常见的:漏桶、令牌桶两种:
- 漏桶是指我们有一个一直装满了水的桶,每过固定的一段时间即向外漏一滴 水。如果你接到了这滴水,那么你就可以继续服务请求,如果没有接到,那么 就需要等待下一滴水。
- 令牌桶则是指匀速向桶中添加令牌,服务请求时需要从桶中获取令牌,令牌的 数目可以按照需要消耗的资源进行相应的调整。如果没有令牌,可以选择等 待,或者放弃。
这两种方法看起来很像,不过还是有区别的。漏桶流出的速率固定,而令牌桶只要 在桶中有令牌,那就可以拿。也就是说令牌桶是允许一定程度的并发的,比如同一 个时刻,有100个用户请求,只要令牌桶中有100个令牌,那么这100个请求全都会 放过去。令牌桶在桶中没有令牌的情况下也会退化为漏桶模型。
实际应用中令牌桶应用较为广泛,开源界流行的限流器大多数都是基于令牌桶思想 的。并且在此基础上进行了一定程度的扩充,比 如 github.com/juju/ratelimit 提供了几种不同特色的令牌桶填充方式:
func NewBucket(fillInterval time.Duration, capacity int64) *Buck et默认的令牌桶, fillInterval 指每过多长时间向桶里放一个令 牌, capacity 是桶的容量,超过桶容量的部分会被直接丢弃。桶初始是满的。
func NewBucketWithQuantum(fillInterval time.Duration, capacity, quantum int64) *Bucket和普通的 NewBucket() 的区别是,每次向桶中放令牌时,是放 quantum 个令 牌,而不是一个令牌。
func NewBucketWithRate(rate float64, capacity int64) *Bucket这个就有点特殊了,会按照提供的比例,每秒钟填充令牌数。例如 capacity 是 100,而 rate 是0.1,那么每秒会填充10个令牌。 从桶中获取令牌也提供了几个API:
func (tb *Bucket) Take(count int64) time.Duration {}
func (tb *Bucket) TakeAvailable(count int64) int64 {}
func (tb *Bucket) TakeMaxDuration(count int64, maxWait time.Dura tion) ( time.Duration, bool, ) {} func (tb *Bucket) Wait(count int64) {}
func (tb *Bucket) WaitMaxDuration(count int64, maxWait time.Dura tion) bool {}名称和功能都比较直观,这里就不再赘述了。相比于开源界更为有名的Google的 Java工具库Guava中提供的ratelimiter,这个库不支持令牌桶预热,且无法修改初 始的令牌容量,所以可能个别极端情况下的需求无法满足。但在明白令牌桶的基本 原理之后,如果没办法满足需求,相信你也可以很快对其进行修改并支持自己的业 务场景。
原理
从功能上来看,令牌桶模型就是对全局计数的加减法操作过程,但使用计数需要我 们自己加读写锁,有小小的思想负担。如果我们对Go语言已经比较熟悉的话,很容 易想到可以用buffered channel来完成简单的加令牌取令牌操作:
var tokenBucket = make(chan struct{}, capacity)每过一段时间向 tokenBucket 中添加 token ,如果 bucket 已经满了,那么直 接放弃:
fillToken := func() {
ticker := time.NewTicker(fillInterval)
for {
select {
case <-ticker.C:
select {
case tokenBucket <- struct{}{}:
default:
}
fmt.Println("current token cnt:", len(tokenBucket), time.Now())
}
}
}把代码组合起来:
package main
import ( "fmt" "time" )
func main() {
var fillInterval = time.Millisecond * 10
var capacity = 100
var tokenBucket = make(chan struct{}, capacity)
fillToken := func() {
ticker := time.NewTicker(fillInterval)
for {
select {
case <-ticker.C:
select {
case tokenBucket <- struct{}{}:
default:
}
fmt.Println("current token cnt:", len(tokenBucket), time.Now())
}
}
}
go fillToken()
time.Sleep(time.Hour)
}上面的令牌桶的取令牌操作实现起来也比较简单,简化问题,我们这里只取一个令 牌:
func TakeAvailable(block bool) bool{
var takenResult bool
if block {
select {
case <-tokenBucket:
takenResult = true
}
}
else {
select {
case <-tokenBucket:
takenResult = true
default: takenResult = false
}
}
return takenResult
}一些公司自己造的限流的轮子就是用上面这种方式来实现的,不过如果开源版 ratelimit 也如此的话,那我们也没什么可说的了。现实并不是这样的。
我们来思考一下,令牌桶每隔一段固定的时间向桶中放令牌,如果我们记下上一次 放令牌的时间为 t1,和当时的令牌数k1,放令牌的时间间隔为ti,每次向令牌桶中 放x个令牌,令牌桶容量为cap。现在如果有人来调用 TakeAvailable 来取n个令 牌,我们将这个时刻记为t2。在t2时刻,令牌桶中理论上应该有多少令牌呢?伪代 码如下:
cur = k1 + ((t2 - t1)/ti) * x
cur = cur > cap ? cap : cur我们用两个时间点的时间差,再结合其它的参数,理论上在取令牌之前就完全可以 知道桶里有多少令牌了。那劳心费力地像本小节前面向channel里填充token的操 作,理论上是没有必要的。只要在每次 Take 的时候,再对令牌桶中的token数进 行简单计算,就可以得到正确的令牌数。是不是很像 惰性求值 的感觉?
在得到正确的令牌数之后,再进行实际的 Take 操作就好,这个 Take 操作只需 要对令牌数进行简单的减法即可,记得加锁以保证并发安 全。 github.com/juju/ratelimit 这个库就是这样做的。
服务瓶颈和 QoS
前面我们说了很多CPU瓶颈、IO瓶颈之类的概念,这种性能瓶颈从大多数公司都有 的监控系统中可以比较快速地定位出来,如果一个系统遇到了性能问题,那监控图 的反应一般都是最快的。
虽然性能指标很重要,但对用户提供服务时还应考虑服务整体的QoS。QoS全称是 Quality of Service,顾名思义是服务质量。QoS包含有可用性、吞吐量、时延、时 延变化和丢失等指标。一般来讲我们可以通过优化系统,来提高Web服务的CPU利 用率,从而提高整个系统的吞吐量。但吞吐量提高的同时,用户体验是有可能变差 的。用户角度比较敏感的除了可用性之外,还有时延。虽然你的系统吞吐量高,但 半天刷不开页面,想必会造成大量的用户流失。所以在大公司的Web服务性能指标 中,除了平均响应时延之外,还会把响应时间的95分位,99分位也拿出来作为性能 标准。平均响应在提高CPU利用率没受到太大影响时,可能95分位、99分位的响应 时间大幅度攀升了,那么这时候就要考虑提高这些CPU利用率所付出的代价是否值 得了。
在线系统的机器一般都会保持CPU有一定的余裕。
layout 常见大型 Web 项目分层
流行的Web框架大多数是MVC框架,MVC这个概念最早由Trygve Reenskaug在 1978年提出,为了能够对GUI类型的应用进行方便扩展,将程序划分为:
- 控制器(Controller)- 负责转发请求,对请求进行处理。
- 视图(View) - 界面设计人员进行图形界面设计。
- 模型(Model) - 程序员编写程序应有的功能(实现算法等等)、数据库专家 进行数据管理和数据库设计(可以实现具体的功能)。
随着时代的发展,前端也变成了越来越复杂的工程,为了更好地工程化,现在更为 流行的一般是前后分离的架构。可以认为前后分离是把V层从MVC中抽离单独成为 项目。这样一个后端项目一般就只剩下 M和C层了。前后端之间通过ajax来交互, 有时候要解决跨域的问题,但也已经有了较为成熟的方案。这里就不作详细描述。
接口和表驱动开发
在Web项目中经常会遇到外部依赖环境的变化,比如:
- 公司的老存储系统年久失修,现在已经没有人维护了,新的系统上线也没有考 虑平滑迁移,但最后通牒已下,要求N天之内迁移完毕。
- 平台部门的老用户系统年久失修,现在已经没有人维护了,真是悲伤的故事。 新系统上线没有考虑兼容老接口,但最后通牒已下,要求N个月之内迁移完 毕。
- 公司的老消息队列人走茶凉,年久失修,新来的技术精英们没有考虑向前兼 容,但最后通牒已下,要求半年之内迁移完毕。
嗯,所以你看到了,我们的外部依赖总是为了自己爽而不断地做升级,且不想做向 前兼容,然后来给我们下最后通牒。如果我们的部门工作饱和,领导强势,那么有 时候也可以倒逼依赖方来做兼容。但世事不一定如人愿,即使我们的领导强势,读 者朋友的领导也还是可能认怂的。 我们可以思考一下怎么缓解这个问题。
业务系统的发展过程
互联网公司只要可以活过三年,工程方面面临的首要问题就是代码膨胀。系统的代 码膨胀之后,可以将系统中与业务本身流程无关的部分做拆解和异步化。什么算是 业务无关呢,比如一些统计、反作弊、营销发券、价格计算、用户状态更新等等需 求。这些需求往往依赖于主流程的数据,但又只是挂在主流程上的旁支,自成体 系。
这时候我们就可以把这些旁支拆解出去,作为独立的系统来部署、开发以及维护。 这些旁支流程的时延如若非常敏感,比如用户在界面上点了按钮,需要立刻返回 (价格计算、支付),那么需要与主流程系统进行RPC通信,并且在通信失败时, 要将结果直接返回给用户。如果时延不敏感,比如抽奖系统,结果稍后公布的这 种,或者非实时的统计类系统,那么就没有必要在主流程里为每一套系统做一套 RPC流程。我们只要将下游需要的数据打包成一条消息,传入消息队列,之后的事 情与主流程一概无关(当然,与用户的后续交互流程还是要做的)。
通过拆解和异步化虽然解决了一部分问题,但并不能解决所有问题。随着业务发 展,单一职责的模块也会变得越来越复杂,这是必然的趋势。一件事情本身变的复 杂的话,这时候拆解和异步化就不灵了。我们还是要对事情本身进行一定程度的封 装抽象。
使用函数封装业务流程
最基本的封装过程,我们把相似的行为放在一起,然后打包成一个一个的函数,让 自己杂乱无章的代码变成下面这个样子:
func BusinessProcess(ctx context.Context, params Params) (resp, error){
ValidateLogin()
ValidateParams()
AntispamCheck()
GetPrice()
CreateOrder()
UpdateUserStatus()
NotifyDownstreamSystems()
}不管是多么复杂的业务,系统内的逻辑都是可以分解为 step1 -> step2 -> step3 ... 这样的流程的。每一个步骤内部也会有复杂的流程,比如:
func CreateOrder() {
ValidateDistrict()
// 判断是否是地区限定商品
ValidateVIPProduct()
// 检查是否是只提供给 vip 的商品
GetUserInfo()
// 从用户系统获取更详细的用户信息
GetProductDesc()
// 从商品系统中获取商品在该时间点的详细信息
DecrementStorage()
// 扣减库存
CreateOrderSnapshot()
// 创建订单快照
return CreateSuccess
}在阅读业务流程代码时,我们只要阅读其函数名就能知晓在该流程中完成了哪些操 作,如果需要修改细节,那么就继续深入到每一个业务步骤去看具体的流程。写得 稀烂的业务流程代码则会将所有过程都堆积在少数的几个函数中,从而导致几百甚 至上千行的函数。这种意大利面条式的代码阅读和维护都会非常痛苦。在开发的过 程中,一旦有条件应该立即进行类似上面这种方式的简单封装。
使用接口来做抽象
业务发展的早期,是不适宜引入接口(interface)的,很多时候业务流程变化很 大,过早引入接口会使业务系统本身增加很多不必要的分层,从而导致每次修改几 乎都要全盘否定之前的工作。
当业务发展到一定阶段,主流程稳定之后,就可以适当地使用接口来进行抽象了。 这里的稳定,是指主流程的大部分业务步骤已经确定,即使再进行修改,也不会进 行大规模的变动,而只是小修小补,或者只是增加或删除少量业务步骤。
如果我们在开发过程中,已经对业务步骤进行了良好的封装,这时候进行接口抽象 化就会变的非常容易,伪代码:
// OrderCreator 创建订单流程
type OrderCreator interface {
ValidateDistrict()
// 判断是否是地区限定商品
ValidateVIPProduct()
// 检查是否是只提供给 vip 的商品
GetUserInfo()
// 从用户系统获取更详细的用户信息
GetProductDesc()
// 从商品系统中获取商品在该时间点的详细信息
DecrementStorage()
// 扣减库存
CreateOrderSnapshot()
// 创建订单快照
}我们只要把之前写过的步骤函数签名都提到一个接口中,就可以完成抽象了。 在进行抽象之前,我们应该想明白的一点是,引入接口对我们的系统本身是否有意 义,这是要按照场景去进行分析的。假如我们的系统只服务一条产品线,并且内部 的代码只是针对很具体的场景进行定制化开发,那么引入接口是不会带来任何收益的。
如果我们正在做的是平台系统,需要由平台来定义统一的业务流程和业务规范,那 么基于接口的抽象就是有意义的。
平台需要服务多条业务线,但数据定义需要统一,所以希望都能走平台定义的流 程。作为平台方,我们可以定义一套类似上文的接口,然后要求接入方的业务必须 将这些接口都实现。如果接口中有其不需要的步骤,那么只要返回 nil ,或者忽 略就好。
在业务进行迭代时,平台的代码是不用修改的,这样我们便把这些接入业务当成了 平台代码的插件(plugin)引入进来了。如果没有接口的话,我们会怎么做?
import ( "sample.com/travelorder" "sample.com/marketorder" )
func CreateOrder() {
switch businessType {
case TravelBusiness: travelorder.CreateOrder()
case MarketBusiness: marketorder.CreateOrderForMarket()
default: return errors.New("not supported business")
}
}
func ValidateUser() {
switch businessType {
case TravelBusiness: travelorder.ValidateUserVIP()
case MarketBusiness: marketorder.ValidateUserRegistered()
default: return errors.New("not supported business")
}
}
// ...
switch ...
switch ...
switch ...没错,就是无穷无尽的 switch ,和没完没了的垃圾代码。引入了接口之后,我们 的 switch 只需要在业务入口做一次。
type BusinessInstance interface {
ValidateLogin()
ValidateParams()
AntispamCheck()
GetPrice()
CreateOrder()
UpdateUserStatus()
NotifyDownstreamSystems()
}
func entry() {
var bi BusinessInstance
switch businessType {
case TravelBusiness: bi = travelorder.New()
case MarketBusiness: bi = marketorder.New()
default: return errors.New("not supported business")
}
}
func BusinessProcess(bi BusinessInstance) {
bi.ValidateLogin()
bi.ValidateParams()
bi.AntispamCheck()
bi.GetPrice()
bi.CreateOrder()
bi.UpdateUserStatus()
bi.NotifyDownstreamSystems()
}接口的优缺点
Go被人称道的最多的地方是其接口设计的正交性,模块之间不需要知晓相互的存 在,A模块定义接口,B模块实现这个接口就可以。如果接口中没有A模块中定义的 数据类型,那B模块中甚至都不用 import A 。比如标准库中的 io.Writer :
type Writer interface { Write(p []byte) (n int, err error) }我们可以在自己的模块中实现 io.Writer 接口:
type MyType struct {}
func (m MyType) Write(p []byte) (n int, err error) { return 0, nil }那么我们就可以把我们自己的 MyType 传给任何使用 io.Writer 作为参数的函数 来使用了,比如:
package log
func SetOutput(w io.Writer) { output = w }然后:
package my-business
import "xy.com/log"
func init() {
log.SetOutput(MyType)
}在 MyType 定义的地方,不需要 import "io" 就可以直接实现 io.Writer 接 口,我们还可以随意地组合很多函数,以实现各种类型的接口,同时接口实现方和 接口定义方都不用建立import产生的依赖关系。因此很多人认为Go的这种正交是一 种很优秀的设计。
在 MyType 定义的地方,不需要 import "io" 就可以直接实现 io.Writer 接 口,我们还可以随意地组合很多函数,以实现各种类型的接口,同时接口实现方和 接口定义方都不用建立import产生的依赖关系。因此很多人认为Go的这种正交是一 种很优秀的设计。
虽有不便,接口带给我们的好处也是不言而喻的:一是依赖反转,这是接口在大多 数语言中对软件项目所能产生的影响,在Go的正交接口的设计场景下甚至可以去除 依赖;二是由编译器来帮助我们在编译期就能检查到类似“未完全实现接口”这样的 错误,如果业务未实现某个流程,但又将其实例作为接口强行来使用的话。
表驱动开发
熟悉开源lint工具的同学应该见到过圈复杂度的说法,在函数中如果 有 if 和 switch 的话,会使函数的圈复杂度上升,所以有强迫症的同学即使在 入口一个函数中有 switch ,还是想要干掉这个 switch ,有没有什么办法呢? 当然有,用表驱动的方式来存储我们需要实例:
func entry() {
var bi BusinessInstance
switch businessType {
case TravelBusiness: bi = travelorder.New()
case MarketBusiness: bi = marketorder.New()
default: return errors.New("not supported business")
}
}可以修改为:
var businessInstanceMap = map[int]BusinessInstance {
TravelBusiness : travelorder.New(),
MarketBusiness : marketorder.New(),
}
func entry() { bi := businessInstanceMap[businessType] }表驱动的设计方式,很多设计模式相关的书籍并没有把它作为一种设计模式来讲, 但我认为这依然是一种非常重要的帮助我们来简化代码的手段。在日常的开发工作 中可以多多思考,哪些不必要的 switch case 可以用一个字典和一行代码就可以 轻松搞定。 当然,表驱动也不是缺点,因为需要对输入 key 计算哈希,在性能敏感的场合, 需要多加斟酌。
灰度发布和 A/B test
中型的互联网公司往往有着以百万计的用户,而大型互联网公司的系统则可能要服 务千万级甚至亿级的用户需求。大型系统的请求流入往往是源源不断的,任何风吹 草动,都一定会有最终用户感受得到。例如你的系统在上线途中会拒绝一些上游过 来的请求,而这时候依赖你的系统没有做任何容错,那么这个错误就会一直向上抛 出,直到触达最终用户。形成一次对用户切切实实的伤害。这种伤害可能是在用户 的APP上弹出一个让用户摸不着头脑的诡异字符串,用户只要刷新一下页面就可以 忘记这件事。但也可能会让正在心急如焚地和几万竞争对手同时抢夺秒杀商品的用 户,因为代码上的小问题,丧失掉了先发优势,与自己蹲了几个月的心仪产品失之 交臂。对用户的伤害有多大,取决于你的系统对于你的用户来说有多重要。 不管怎么说,在大型系统中容错是重要的,能够让系统按百分比,分批次到达最终 用户,也是很重要的。虽然当今的互联网公司系统,名义上会说自己上线前都经过 了充分慎重严格的测试,但就算它们真得做到了,代码的bug总是在所难免的。即 使代码没有bug,分布式服务之间的协作也是可能出现“逻辑”上的非技术问题的。
这时候,灰度发布就显得非常重要了,灰度发布也称为金丝雀发布,传说17世纪的 英国矿井工人发现金丝雀对瓦斯气体非常敏感,瓦斯达到一定浓度时,金丝雀即会 死亡,但金丝雀的致死量瓦斯对人并不致死,因此金丝雀被用来当成他们的瓦斯检 测工具。互联网系统的灰度发布一般通过两种方式实现:
- 通过分批次部署实现灰度发布
- 通过业务规则进行灰度发布
在对系统的旧功能进行升级迭代时,第一种方式用的比较多。新功能上线时,第二 种方式用的比较多。当然,对比较重要的老功能进行较大幅度的修改时,一般也会 选择按业务规则来进行发布,因为直接全量开放给所有用户风险实在太大。
通过分批次部署实现灰度发布
假如服务部署在15个实例(可能是物理机,也可能是容器)上,我们把这15个实例 分为四组,按照先后顺序,分别有1-2-4-8台机器,保证每次扩展时大概都是二倍的 关系。
为什么要用2倍?这样能够保证我们不管有多少台机器,都不会把组划分得太多。 例如1024台机器,也就只需要1-2-4-8-16-32-64-128-256-512部署十次就可以全部 部署完毕。
这样我们上线最开始影响到的用户在整体用户中占的比例也不大,比如1000台机器 的服务,我们上线后如果出现问题,也只影响1/1000的用户。如果10组完全平均 分,那一上线立刻就会影响1/10的用户,1/10的业务出问题,那可能对于公司来说 就已经是一场不可挽回的事故了。
在上线时,最有效的观察手法是查看程序的错误日志,如果较明显的逻辑错误,一 般错误日志的滚动速度都会有肉眼可见的增加。这些错误也可以通过metrics一类的 系统上报给公司内的监控系统,所以在上线过程中,也可以通过观察监控曲线,来 判断是否有异常发生。 如果有异常情况,首先要做的自然就是回滚了。
通过业务规则进行灰度发布
常见的灰度策略有多种,较为简单的需求,例如我们的策略是要按照千分比来发 布,那么我们可以用用户id、手机号、用户设备信息,等等,来生成一个简单的哈 希值,然后再求模,用伪代码表示一下:
// pass 3/1000
func passed() bool {
key := hashFunctions(userID) % 1000
if key <= 2 {
return true
}
return false
}可选规则
常见的灰度发布系统会有下列规则提供选择:
- 按城市发布
- 按概率发布
- 按百分比发布
- 按白名单发布
- 按业务线发布
- 按UA发布(APP、Web、PC)
- 按分发渠道发布
因为和公司的业务相关,所以城市、业务线、UA、分发渠道这些都可能会被直接编 码在系统里,不过功能其实大同小异。 按白名单发布比较简单,功能上线时,可能我们希望只有公司内部的员工和测试人 员可以访问到新功能,会直接把账号、邮箱写入到白名单,拒绝其它任何账号的访 问。