并发
goroutine
下面的程序会创建两个 goroutine,以并发的形式分别显示大写和小写的英文字母。
// 这个示例程序展示如何创建 goroutine
// 以及调度器的行为
package main
import (
"fmt"
"runtime"
"sync"
)
// main 是所有 Go 程序的入口
func main() {
// 分配一个逻辑处理器给调度器使用
runtime.GOMAXPROCS(1)
// wg 用来等待程序完成
// 计数加 2,表示要等待两个 goroutine
var wg sync.WaitGroup
wg.Add(2)
fmt.Println("Start Goroutines")
// 声明一个匿名函数,并创建一个 goroutine
go func() {
// 在函数退出时调用 Done 来通知 main 函数工作已经完成
defer wg.Done()
// 显示字母表 3 次
for count := 0; count < 3; count++ {
for char := 'a'; char < 'a'+26; char++ {
fmt.Printf("%c ", char)
}
}
}()
// 声明一个匿名函数,并创建一个 goroutine
go func() {
// 在函数退出时调用 Done 来通知 main 函数工作已经完成
defer wg.Done()
// 显示字母表 3 次
for count := 0; count < 3; count++ {
for char := 'A'; char < 'A'+26; char++ {
fmt.Printf("%c ", char)
}
}
}()
// 等待 goroutine 结束
fmt.Println("Waiting To Finish")
wg.Wait()
fmt.Println("\nTerminating Program")
}调用了 runtime 包的 GOMAXPROCS 函数。这个函数允许程序更改调度器可以使用的逻辑处理器的数量。如果不想在代码里做这个调用,也可以通过修改和这个函数名字一样的环境变量的值来更改逻辑处理器的数量。给这个函数传入 1,是通知调度器只能为该程序使用一个逻辑处理器。
一旦两个匿名函数创建 goroutine 来执行,main 中的代码会继续运行。这意味着 main 函数会在 goroutine 完成工作前返回。如果真的返回了,程序就会在 goroutine 有机会运行前终止。因此,main 函数通过 WaitGroup,等待两个 goroutine 完成它们的工作。
WaitGroup 是一个计数信号量,可以用来记录并维护运行的 goroutine。如果 WaitGroup的值大于 0,Wait 方法就会阻塞。创建了一个 WaitGroup 类型的变量,之后在将这个 WaitGroup 的值设置为 2,表示有两个正在运行的 goroutine。为了减小WaitGroup 的值并最终释放 main 函数,要使用 defer 声明在函数退出时调用 Done 方法。
关键字 defer 会修改函数调用时机,在正在执行的函数返回时才真正调用 defer 声明的函数。对这里的示例程序来说,我们使用关键字 defer 保证,每个 goroutine 一旦完成其工作就调用 Done 方法。
如何修改逻辑处理器的数量
import "runtime"
// 给每个可用的核心分配一个逻辑处理器
runtime.GOMAXPROCS(runtime.NumCPU())runtime 提供了修改 Go 语言运行时配置参数的能力。函数 NumCPU 返回可以使用的物理处理器的数量。因此,调用 GOMAXPROCS 函数就为每个可用的物理处理器创建一个逻辑处理器。需要强调的是,使用多个逻辑处理器并不意味着性能更好。在修改任何语言运行时配置参数的时候,都需要配合基准测试来评估程序的运行效果。至于更多的关于goroutine的知识,可以参阅 Goroutines和Channels
竞争状态
如果两个或者多个 goroutine 在没有互相同步的情况下,访问某个共享的资源,并试图同时 读和写这个资源,就处于相互竞争的状态,这种情况被称作竞争状态(race candition)。竞争状态 的存在是让并发程序变得复杂的地方,十分容易引起潜在问题。对一个共享资源的读和写操作必 须是原子化的,换句话说,同一时刻只能有一个 goroutine 对共享资源进行读和写操作。
Go 语言有一个特别的工具,可以在代码里检测竞争状态。在查找这类错误的时候,这个工 具非常好用,尤其是在竞争状态并不像这个例子里这么明显的时候。
go build -race // 用竞争检测器标志来编译程序一种修正代码、消除竞争状态的办法是,使用 Go 语言提供的锁机制,来锁住共享资源,从 而保证 goroutine 的同步状态。
锁住共享资源
Go 语言提供了传统的同步 goroutine 的机制,就是对共享资源加锁。如果需要顺序访问一个 整型变量或者一段代码,atomic 和 sync 包里的函数提供了很好的解决方案。下面我们了解一 下 atomic 包里的几个函数以及 sync 包里的 mutex 类型。
原子函数
原子函数能够以很底层的加锁机制来同步访问整型变量和指针。我们可以用原子函数来修正 代码中创建的竞争状态
// 这个示例程序展示如何使用 atomic 包来提供
// 对数值类型的安全访问
package main
import (
"fmt"
"runtime"
"sync"
"sync/atomic"
)
var (
// counter 是所有 goroutine 都要增加其值的变量
counter int64
// wg 用来等待程序结束
wg sync.WaitGroup
)
// main 是所有 Go 程序的入口
func main() {
// 计数加 2,表示要等待两个 goroutine
wg.Add(2)
// 创建两个 goroutine
go incCounter(1)
go incCounter(2)
// 等待 goroutine 结束
wg.Wait()
// 显示最终的值
fmt.Println("Final Counter:", counter)
}
// incCounter 增加包里 counter 变量的值
func incCounter(id int) {
// 在函数退出时调用 Done 来通知 main 函数工作已经完成
defer wg.Done()
for count := 0; count < 2; count++ {
// 安全地对 counter 加 1
atomic.AddInt64(&counter, 1)
// 当前 goroutine 从线程退出,并放回到队列
runtime.Gosched()
}
}现在,程序使用了 atmoic 包的 AddInt64 函数。这个函数会同步整型值的加法,方法是强制同一时刻只能有一个 goroutine 运行并完成这个加法操作。当 goroutine 试图去调用任何原子函数时,这些 goroutine 都会自动根据所引用的变量做同步处理。现在我们得到了正确的值 4。
另外两个有用的原子函数是 LoadInt64 和 StoreInt64。这两个函数提供了一种安全地读 和写一个整型值的方式。下面代码中的示例程序使用 LoadInt64 和 StoreInt64 来创建 一个同步标志,这个标志可以向程序里多个 goroutine 通知某个特殊状态。
// 这个示例程序展示如何使用 atomic 包里的
// Store 和 Load 类函数来提供对数值类型
// 的安全访问
package main
import (
"fmt"
"sync"
"sync/atomic"
"time"
)
var (
// shutdown 是通知正在执行的 goroutine 停止工作的标志
shutdown int64
// wg 用来等待程序结束
wg sync.WaitGroup
)
// main 是所有 Go 程序的入口
func main() {
// 计数加 2,表示要等待两个 goroutine
wg.Add(2)
// 创建两个 goroutine
go doWork("A")
go doWork("B")
// 给定 goroutine 执行的时间
time.Sleep(1 * time.Second)
// 该停止工作了,安全地设置 shutdown 标志
fmt.Println("Shutdown Now")
atomic.StoreInt64(&shutdown, 1)
// 等待 goroutine 结束
wg.Wait()
}
// doWork 用来模拟执行工作的 goroutine,
// 检测之前的 shutdown 标志来决定是否提前终止
func doWork(name string) {
// 在函数退出时调用 Done 来通知 main 函数工作已经完成
defer wg.Done()
for {
fmt.Printf("Doing %s Work\n", name)
time.Sleep(250 * time.Millisecond)
// 要停止工作了吗?
if atomic.LoadInt64(&shutdown) == 1 {
fmt.Printf("Shutting %s Down\n", name)
break
}
}
}在这个例子中,启动了两个 goroutine,并完成一些工作。在各自循环的每次迭代之后,goroutine 会使用 LoadInt64 来检查 shutdown 变量的值。这个函数会安全地返回shutdown 变量的一个副本。如果这个副本的值为 1,goroutine 就会跳出循环并终止。在main 函数使用 StoreInt64 函数来安全地修改 shutdown 变量的值。如果哪个 doWork goroutine 试图在 main 函数调用 StoreInt64 的同时调用 LoadInt64 函数,那么原子函数会将这些调用互相同步,保证这些操作都是安全的,不会进入竞争状态。
互斥锁
另一种同步访问共享资源的方式是使用互斥锁(mutex)。互斥锁这个名字来自互斥(mutual exclusion)的概念。互斥锁用于在代码上创建一个临界区,保证同一时间只有一个 goroutine 可以 执行这个临界区代码。
// 这个示例程序展示如何使用互斥锁来
// 定义一段需要同步访问的代码临界区
// 资源的同步访问
package main
import (
"fmt"
"runtime"
"sync"
)
var (
// counter 是所有 goroutine 都要增加其值的变量
counter int
// wg 用来等待程序结束
wg sync.WaitGroup
// mutex 用来定义一段代码临界区
mutex sync.Mutex
)
// main 是所有 Go 程序的入口
func main() {
// 计数加 2,表示要等待两个 goroutine
wg.Add(2)
// 创建两个 goroutine
go incCounter(1)
go incCounter(2)
// 等待 goroutine 结束
wg.Wait()
fmt.Printf("Final Counter: %d\\n", counter)
}
// incCounter 使用互斥锁来同步并保证安全访问,
// 增加包里 counter 变量的值
func incCounter(id int) {
// 在函数退出时调用 Done 来通知 main 函数工作已经完成
defer wg.Done()
for count := 0; count < 2; count++ {
// 同一时刻只允许一个 goroutine 进入
// 这个临界区
mutex.Lock()
{
// 捕获 counter 的值
value := counter
// 当前 goroutine 从线程退出,并放回到队列
runtime.Gosched()
// 增加本地 value 变量的值
value++
// 将该值保存回 counter
counter = value
}
mutex.Unlock()
// 释放锁,允许其他正在等待的 goroutine
// 进入临界区
}
}对 counter 变量的操作 Lock()和 Unlock()函数调用定义的临界区里被保护起来。使用大括号只是为了让临界区看起来更清晰,并不是必需的。同一时刻只有一个 goroutine 可以进入临界区。之后,直到调用 Unlock()函数之后,其他 goroutine 才能进入临界区。当强制将当前 goroutine 退出当前线程后,调度器会再次分配这个 goroutine 继续运行。当程序结束时,我们得到正确的值 4,竞争状态不再存在。
通道
原子函数和互斥锁都能工作,但是依靠它们都不会让编写并发程序变得更简单,更不容易出 错,或者更有趣。在 Go 语言里,你不仅可以使用原子函数和互斥锁来保证对共享资源的安全访 问以及消除竞争状态,还可以使用通道,通过发送和接收需要共享的资源,在 goroutine 之间做 同步。
当一个资源需要在 goroutine 之间共享时,通道在 goroutine 之间架起了一个管道,并提供了 确保同步交换数据的机制。声明通道时,需要指定将要被共享的数据的类型。可以通过通道共享 内置类型、命名类型、结构类型和引用类型的值或者指针。
// 无缓冲的整型通道
unbuffered := make(chan int)
// 有缓冲的字符串通道
buffered := make(chan string, 10)可以看到使用内置函数 make 创建了两个通道,一个无缓冲的通道,一个有缓冲的通道。make 的第一个参数需要是关键字 chan,之后跟着允许通道交换的数据的类型。如果创建的是一个有缓冲的通道,之后还需要在第二个参数指定这个通道的缓冲区的大小。向通道发送值或者指针需要用到<-操作符
// 有缓冲的字符串通道
buffered := make(chan string, 10)
// 通过通道发送一个字符串
buffered <- "Gopher"我们创建了一个有缓冲的通道,数据类型是字符串,包含一个 10 个值的缓冲区。之后我们通过通道发送字符串"Gopher"。为了让另一个 goroutine 可以从该通道里接收到这个字符串,我们依旧使用<-操作符,但这次是一元运算符。
// 从通道接收一个字符串
value := <-buffered当从通道里接收一个值或者指针时,<-运算符在要操作的通道变量的左侧
无缓冲的通道
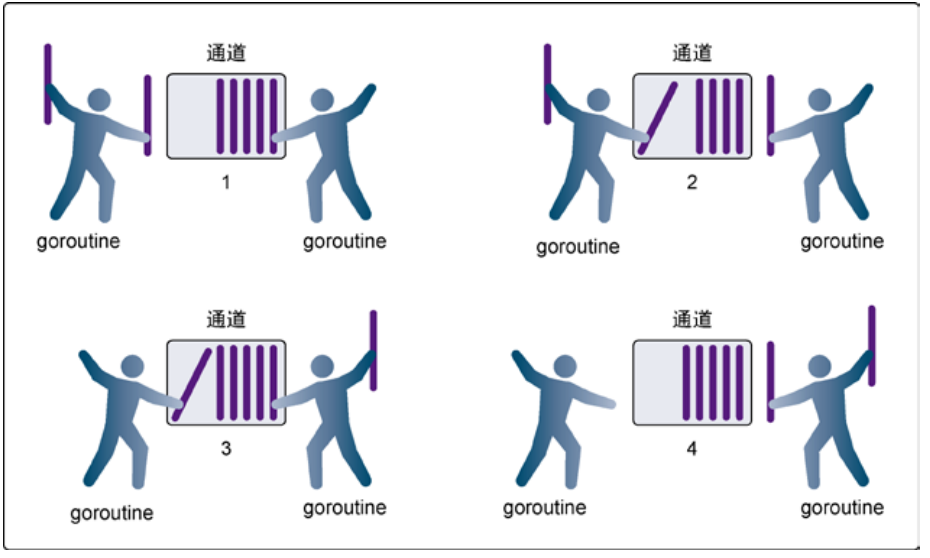
无缓冲的通道(unbuffered channel)是指在接收前没有能力保存任何值的通道。这种类型的通 道要求发送 goroutine 和接收 goroutine 同时准备好,才能完成发送和接收操作。如果两个 goroutine没有同时准备好,通道会导致先执行发送或接收操作的 goroutine 阻塞等待。这种对通道进行发送和接收的交互行为本身就是同步的。其中任意一个操作都无法离开另一个操作单独存在。

在第 1 步,两个 goroutine 都到达通道,但哪个都没有开始执行发送或者接收。在第 2 步,左侧 的 goroutine 将它的手伸进了通道,这模拟了向通道发送数据的行为。这时,这个 goroutine 会在 通道中被锁住,直到交换完成。在第 3 步,右侧的 goroutine 将它的手放入通道,这模拟了从通 道里接收数据。这个 goroutine 一样也会在通道中被锁住,直到交换完成。在第 4 步和第 5 步, 进行交换,并最终,在第 6 步,两个 goroutine 都将它们的手从通道里拿出来,这模拟了被锁住 的 goroutine 得到释放。两个 goroutine 现在都可以去做别的事情了。
在网球比赛中,两位选手会把球在两个人之间来回传递。选手总是处在以下两种状态之一: 要么在等待接球,要么将球打向对方。可以使用两个 goroutine 来模拟网球比赛,并使用无缓冲 的通道来模拟球的来回:
// 这个示例程序展示如何用无缓冲的通道来模拟
// 2 个 goroutine 间的网球比赛
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
// wg 用来等待程序结束
var wg sync.WaitGroup
func init() {
rand.Seed(time.Now().UnixNano())
}
// main 是所有 Go 程序的入口
func main() {
// 创建一个无缓冲的通道
court := make(chan int)
// 计数加 2,表示要等待两个 goroutine
wg.Add(2)
// 启动两个选手
go player("Nadal", court)
go player("Djokovic", court)
// 发球
court <- 1
// 等待游戏结束
wg.Wait()
}
// player 模拟一个选手在打网球
func player(name string, court chan int) {
// 在函数退出时调用 Done 来通知 main 函数工作已经完成
defer wg.Done()
for {
// 等待球被击打过来
ball, ok := <-court
if !ok {
// 如果通道被关闭,我们就赢了
fmt.Printf("Player %s Won\n", name)
return
}
// 选随机数,然后用这个数来判断我们是否丢球
n := rand.Intn(100)
if n%13 == 0 {
fmt.Printf("Player %s Missed\n", name)
// 关闭通道,表示我们输了
close(court)
return
}
// 显示击球数,并将击球数加 1
fmt.Printf("Player %s Hit %d\n", name, ball)
ball++
// 将球打向对手
court <- ball
}
}有缓冲的通道
有缓冲的通道(buffered channel)是一种在被接收前能存储一个或者多个值的通道。这种类 型的通道并不强制要求 goroutine 之间必须同时完成发送和接收。通道会阻塞发送和接收动作的 条件也会不同。只有在通道中没有要接收的值时,接收动作才会阻塞。只有在通道没有可用缓冲 区容纳被发送的值时,发送动作才会阻塞。这导致有缓冲的通道和无缓冲的通道之间的一个很大 的不同:无缓冲的通道保证进行发送和接收的 goroutine 会在同一时间进行数据交换;有缓冲的 通道没有这种保证。
可以看到两个goroutine分别向有缓冲的通道里增加一个值和从有缓冲的通道里移 除一个值。在第 1 步,右侧的 goroutine 正在从通道接收一个值。在第 2 步,右侧的这个 goroutine 独立完成了接收值的动作,而左侧的 goroutine 正在发送一个新值到通道里。在第 3 步,左侧的 goroutine 还在向通道发送新值,而右侧的 goroutine 正在从通道接收另外一个值。这个步骤里的 两个操作既不是同步的,也不会互相阻塞。最后,在第 4 步,所有的发送和接收都完成,而通道 里还有几个值,也有一些空间可以存更多的值。
让我们看一个使用有缓冲的通道的例子,这个例子管理一组 goroutine 来接收并完成工作。
// 这个示例程序展示如何使用
// 有缓冲的通道和固定数目的
// goroutine 来处理一堆工作
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
const (
numberGoroutines = 4 // 要使用的 goroutine 的数量
taskLoad = 10 // 要处理的工作的数量
)
// wg 用来等待程序完成
var wg sync.WaitGroup
// init 初始化包,Go 语言运行时会在其他代码执行之前
// 优先执行这个函数
func init() {
// 初始化随机数种子
rand.Seed(time.Now().Unix())
}
// main 是所有 Go 程序的入口
func main() {
// 创建一个有缓冲的通道来管理工作
tasks := make(chan string, taskLoad)
// 启动 goroutine 来处理工作
wg.Add(numberGoroutines)
for gr := 1; gr <= numberGoroutines; gr++ {
go worker(tasks, gr)
}
// 增加一组要完成的工作
for post := 1; post <= taskLoad; post++ {
tasks <- fmt.Sprintf("Task : %d", post)
}
// 当所有工作都处理完时关闭通道
// 以便所有 goroutine 退出
close(tasks)
// 等待所有工作完成
wg.Wait()
}
// worker 作为 goroutine 启动来处理
// 从有缓冲的通道传入的工作
func worker(tasks chan string, worker int) {
// 通知函数已经返回
defer wg.Done()
for {
// 等待分配工作
task, ok := <-tasks
if !ok {
// 这意味着通道已经空了,并且已被关闭
fmt.Printf("Worker: %d : Shutting Down\n", worker)
return
}
// 显示我们开始工作了
fmt.Printf("Worker: %d : Started %s\n", worker, task)
// 随机等一段时间来模拟工作
sleep := rand.Int63n(100)
time.Sleep(time.Duration(sleep) * time.Millisecond)
// 显示我们完成了工作
fmt.Printf("Worker: %d : Completed %s\n", worker, task)
}由于程序和 Go 语言的调度器带有随机成分,这个程序每次执行得到的输出会不一样。不过, 通过有缓冲的通道,使用所有 4 个 goroutine 来完成工作,这个流程不会变。从输出可以看到每 个 goroutine 是如何接收从通道里分发的工作。