Search流程
GET操作只能对单个文档进行处理,由_index、_type和_id三元 组来确定唯一文档。但搜索需要一种更复杂的模型,因为不知道查询会命中哪些文档。
找到匹配文档仅仅完成了搜索流程的一半,因为多分片中的结果 必须组合成单个排序列表。集群的任意节点都可以接收搜索请求,接收客户端请求的节点称为协调节点。在协调节点,搜索任务被执行成一个两阶段过程,即query then fetch。真正执行搜索任务的节点称为数据节点。
需要两个阶段才能完成搜索的原因是,在查询的时候不知道文档 位于哪个分片,因此索引的所有分片(某个副本)都要参与搜索,然后协调节点将结果合并,再根据文档ID获取文档内容。例如,有5个分片,查询返回前10个匹配度最高的文档,那么每个分片都查询出当前分片的TOP 10,协调节点将5×10 = 50的结果再次排序,返回最终TOP 10的结果给客户端。
索引和搜索
ES中的数据可以分为两类:精确值和全文。
- 精确值,比如日期和用户id、IP地址等。
- 全文,指文本内容,比如一条日志,或者邮件的内容。
这两种类型的数据在查询时是不同的:对精确值的比较是二进制 的,查询要么匹配,要么不匹配;全文内容的查询无法给出“有”还是“没有”的结果,它只能找到结果是“看起来像”你要查询的东西,因此把查询结果按相似度排序,评分越高,相似度越大。

建立索引
如果是全文数据,则对文本内容进行分析,这项工作在 ES 中由 分析器实现。分析器实现如下功能:
- 字符过滤器。主要是对字符串进行预处理,例如,去掉HTML, 将&转换成and等。
- 分词器(Tokenizer)。将字符串分割为单个词条,例如,根据 空格和标点符号分割,输出的词条称为词元(Token)。
- Token过滤器。根据停止词(Stop word)删除词元,例如, and、the等无用词,或者根据同义词表增加词条,例如,jump和 leap。
- 语言处理。对上一步得到的Token做一些和语言相关的处理,例 如,转为小写,以及将单词转换为词根的形式。语言处理组件输出的结果称为词(Term)。
分析完毕后,将分析器输出的词(Term)传递给索引组件,生成 倒排和正排索引,再存储到文件系统中。
执行搜索
搜索调用Lucene完成,如果是全文检索,则:
- 对检索字段使用建立索引时相同的分析器进行分析,产生Token 列表;
- 根据查询语句的语法规则转换成一棵语法树;
- 查找符合语法树的文档;
- 对匹配到的文档列表进行相关性评分,评分策略一般使用 TF/IDF;
- 根据评分结果进行排序。
search type
ES目前有两种搜索类型:
- DFS_QUERY_THEN_FETCH;
- QUERY_THEN_FETCH(默认)。
两种不同的搜索类型的区别在于查询阶段,DFS查询阶段的流程 要多一些,它使用全局信息来获取更准确的评分。
分布式搜索过程
一个搜索请求必须询问请求的索引中所有分片的某个副本来进行 匹配。假设一个索引有5个主分片,每个主分片有1个副分片,共10个分片,一次搜索请求会由5个分片来共同完成,它们可能是主分片,也可能是副分片。也就是说,一次搜索请求只会命中所有分片副本中的一个。

协调节点流程
两阶段相应的实现位置:查询(Query)阶段—search.InitialSearchPhase;取回(Fetch)阶段 —search.FetchSearchPhase。
Query阶段
在初始查询阶段,查询会广播到索引中每一个分片副本(主分片 或副分片)。每个分片在本地执行搜索并构建一个匹配文档的优先队列。
优先队列是一个存有topN匹配文档的有序列表。优先队列大小为 分页参数from + size。
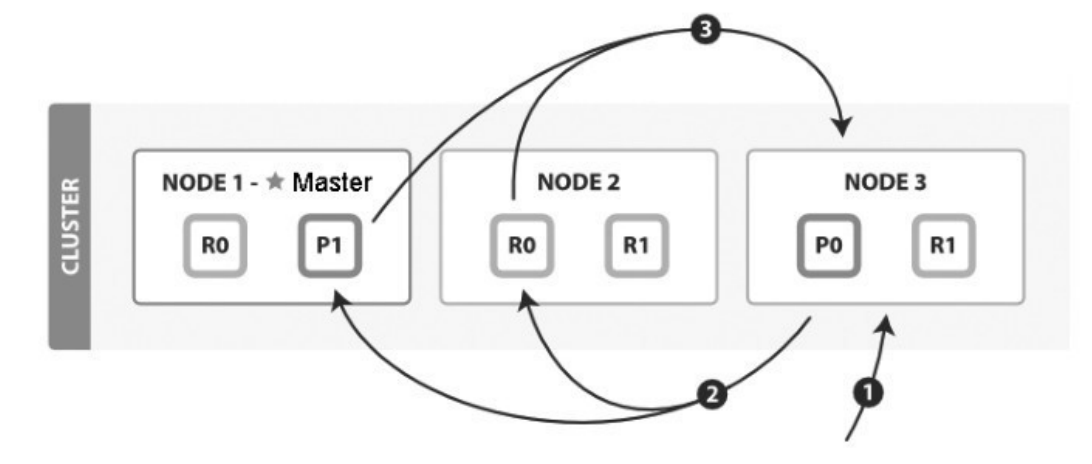
QUERY_THEN_FETCH搜索类型的查询阶段步骤如下:
- (1)客户端发送search请求到NODE 3。
- (2)Node 3将查询请求转发到索引的每个主分片或副分片中。
- (3)每个分片在本地执行查询,并使用本地的Term/Document Frequency信息进行打分,添加结果到大小为from + size的本地有序优先队列中。
- (4)每个分片返回各自优先队列中所有文档的ID和排序值给协调节点,协调节点合并这些值到自己的优先队列中,产生一个全局排序后的列表。
协调节点广播查询请求到所有相关分片时,可以是主分片或副分 片,协调节点将在之后的请求中轮询所有的分片副本来分摊负载。
查询阶段并不会对搜索请求的内容进行解析,无论搜索什么内 容,只看本次搜索需要命中哪些shard,然后针对每个特定shard选择一个副本,转发搜索请求。
Fetch阶段
Query阶段知道了要取哪些数据,但是并没有取具体的数据,这 就是Fetch阶段要做的。
Fetch阶段由以下步骤构成:
- (1)协调节点向相关NODE发送GET请求。
- (2)分片所在节点向协调节点返回数据。
- (3)协调节点等待所有文档被取得,然后返回给客户端。
分片所在节点在返回文档数据时,处理有可能出现的_source字段 和高亮参数。协调节点首先决定哪些文档“确实”需要被取回,例如,如果查询指定了{ "from": 90, "size":10 },则只有从第91个开始的10个结果需要被取回。为了避免在协调节点中创建的number_of_shards * (from +size)优先队列过大,应尽量控制分页深度。
执行搜索的数据节点流程
执行本流程的线程池:search。
对 各 种 Query 、 Fetch 请 求 的 处 理 入 口 注 册 于 SearchTransportService#registerRequestHandler。
响应Query请求
查询实现入口在 searchService.executeQueryPhase 中(完全封装在这个方法中)。查询时,先看是否允许cache,由以下配置决定:
index.requests.cache.enable
默认为true,会把查询结果放到cache中,查询时优先从cache 中取。这个cache由节点的所有分片共享,基于LRU算法实现:空间满的时候删除最近最少使用的数据。cache并不缓存全部检索结果。
核心的查询封装在queryPhase.execute(context)中,其中 调用Lucene实现检索,同时实现聚合:
- execute(),调用Lucene、searcher.search()实现搜 索;
- rescorePhase,全文检索且需要打分;
- suggestPhase,自动补全及纠错;
- aggregationPhase,实现聚合。
总结:
- 慢查询Query日志的统计时间在于本阶段的处理时间。
- 聚合操作在本阶段实现,在Lucene检索后完成。
最后
- 聚合是在ES中实现的,而非Lucene。
- Query和Fetch请求之间是无状态的,除非是scroll方式。
- 分页搜索不会单独“cache”,cache和分页没有关系。
- 每次分页的请求都是一次重新搜索的过程,而不是从第一次搜索 的结果中获取。看上去不太符合常规的做法,事实上互联网的搜索引擎都是重新执行了搜索过程:人们基本只看前几页,很少深度分页;重新执行一次搜索很快;如果缓存第一次搜索结果等待翻页命中,则这种缓存的代价较大,意义却不大,因此不如重新执行一次搜索。
- 搜索需要遍历分片所有的Lucene分段,因此合并Lucene分段对 搜索性能有好处。