GET流程
ES的读取分为GET和Search两种操作,这两种读取操作有较大的 差异,GET/MGET必须指定三元组:_index、_type、_id。也就是说,根据文档id从正排索引中获取内容。而Search不指定_id,根据关键词从倒排索引中获取内容。
可选参数
与写请求相同,GET请求时可以在URI中设置一些可选参数,如下 表所示。
GET基本流程
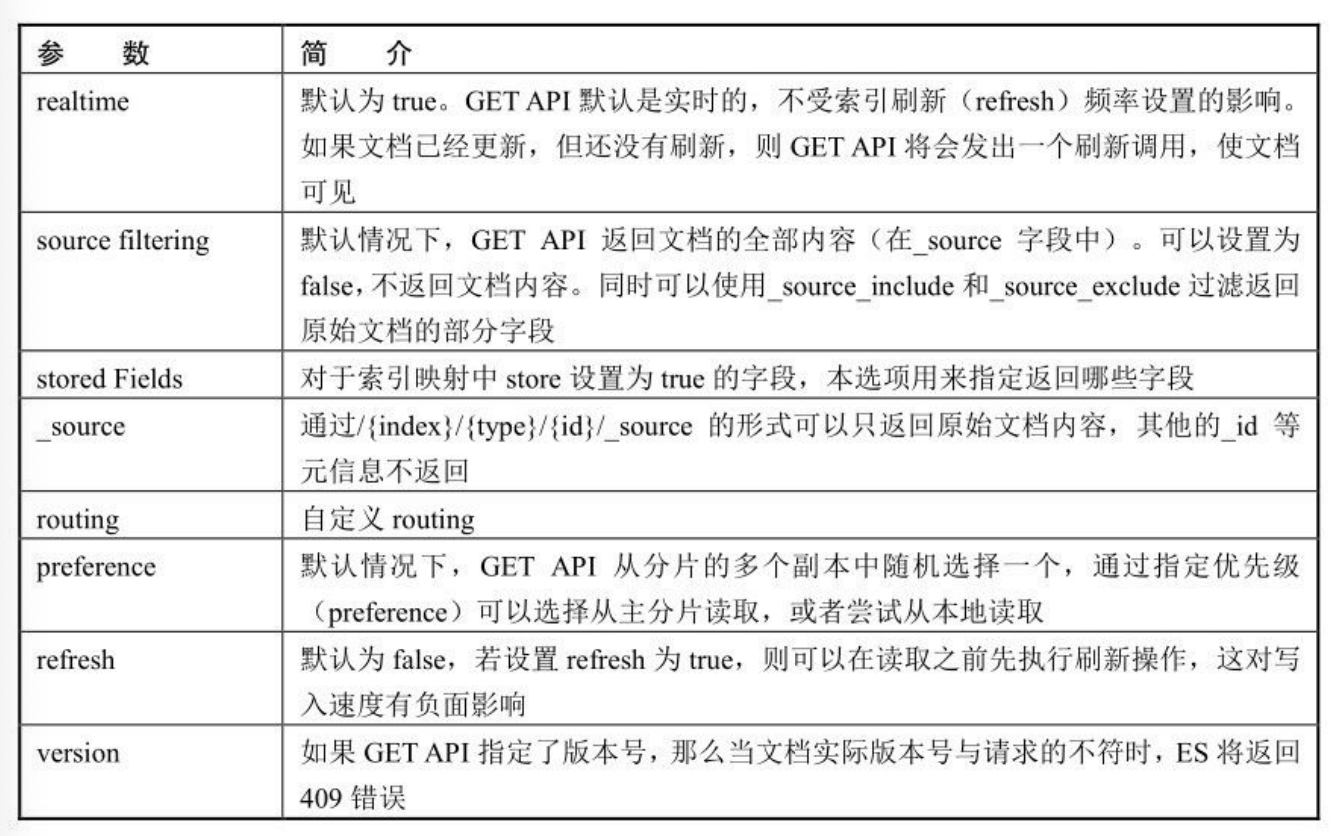
搜索和读取文档都属于读操作,可以从主分片或副分片中读取数 据。 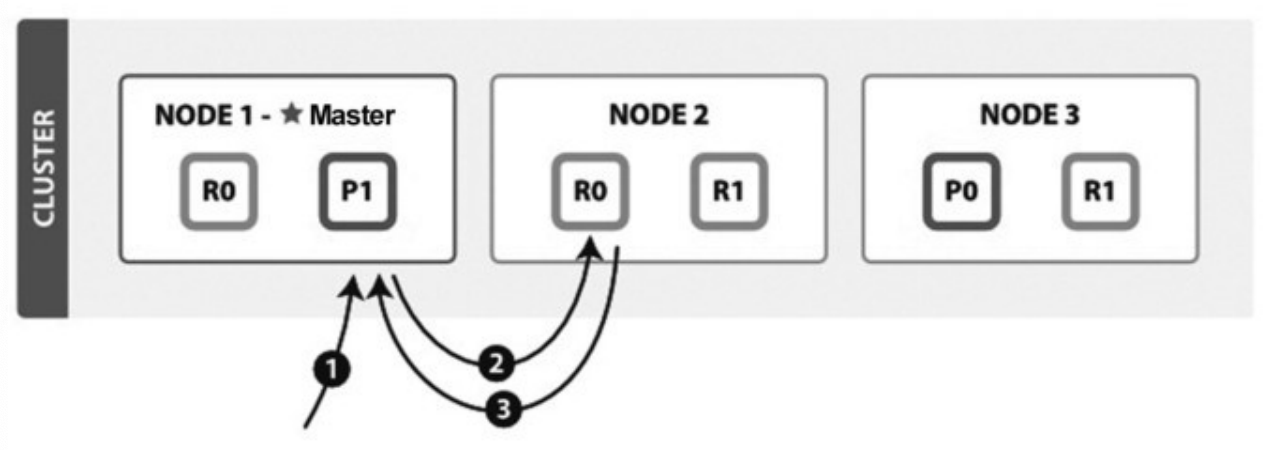
- (1)客户端向NODE1发送读请求。
- (2)NODE1使用文档ID来确定文档属于分片0,通过集群状态 中的内容路由表信息获知分片0有三个副本数据,位于所有的三个节点中,此时它可以将请求发送到任意节点,这里它将请求转发到 NODE2。
- (3)NODE2将文档返回给 NODE1,NODE1将文档返回给客户 端。
NODE1作为协调节点,会将客户端请求轮询发送到集群的所有副 本来实现负载均衡。在读取时,文档可能已经存在于主分片上,但还没有复制到副分片。在这种情况下,读请求命中副分片时可能会报告文档不存在,但是命中主分片可能成功返回文档。一旦写请求成功返回给客户端,则意味着文档在主分片和副分片都是可用的。
GET详细分析
GET/MGET流程涉及两个节点:协调节点和数据节点,流程如下 图所示。

协调节点
执行本流程的线程池:http_server_worker。 TransportSingleShardAction 类用来处理存在于一个单个(主或副)分片上的读请求。将请求转发到目标节点,如果请求执行失败,则尝试转发到其他节点读取。在收到读请求后,处理过程如下。
内容路由
( 1 ) 在 TransportSingleShardAction.AsyncSingleAction 构造函数中,准备集群状态、节点列表等信息。
(2)根据内容路由算法计算目标shardid,也就是文档应该落在 哪个分片上。
(3)计算出目标shardid后,结合请求参数中指定的优先级和集 群状态确定目标节点,由于分片可能存在多个副本,因此计算出的是一个列表。
转发请求
作为协调节点,向目标节点转发请求,或者目标是本地节点,直 接读取数据。发送函数声明了如何对 Response 进行处理 : AsyncSingleAction类中声明对Response进行处理的函数。无论请求在本节点处理还是发送到其他节点,均对Response执行相同的处理逻辑。
数据节点
执行本流程的线程池:get。
数据节点接收协调节点请求的入口为: TransportSingleShardAction.ShardTransportHandler# messageReceived。读取数据并组织成Response,给客户端channel返回
MGET流程分析
MGET 的主要处理类:TransportMultiGetAction,通过封装单个 GET 请求实现,处理流程如下图所示。
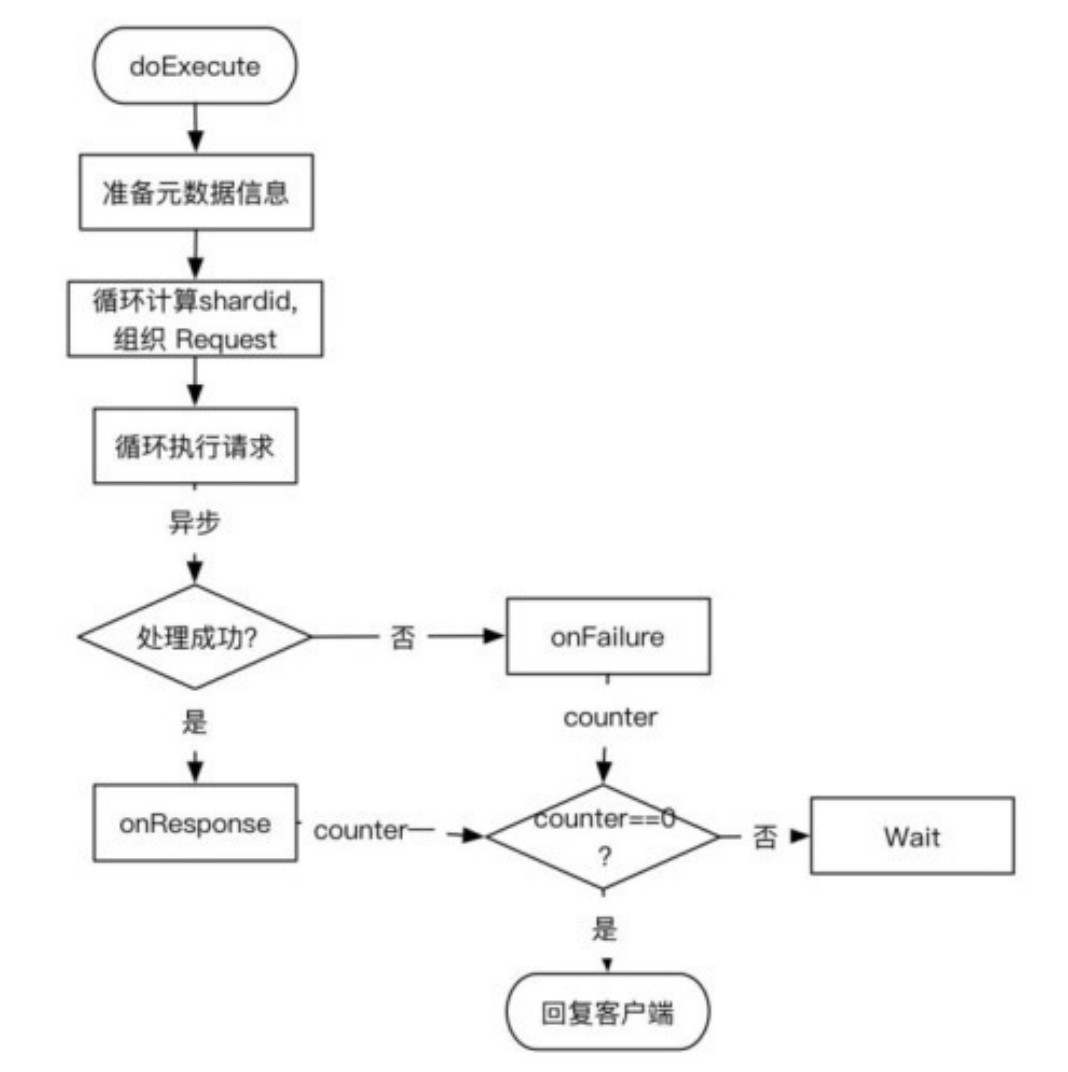
主要流程如下:
(1)遍历请求,计算出每个doc的路由信息,得到由shardid为 key 组 成 的 request map 。 这 个 过 程 没 有 在 TransportSingleShardAction中实现,是因为如果在那里实现,
shardid就会重复,这也是合并为基于分片的请求的过程。 (2)循环处理组织好的每个 shard 级请求,调用处理 GET 请求时使用 TransportSingleShardAction#AsyncSingleAction处理单 个doc的流程。
( 3 ) 收 集 Response , 全 部 Response 返 回 后 执 行finishHim(),给客户端返回结果。
回复的消息中文档顺序与请求的顺序一致。如果部分文档读取失 败,则不影响其他结果,检索失败的doc会在回复信息中标出。
最后
我们需要警惕实时读取特性,GET API默认是实时的,实时的意 思是写完了可以立刻读取,但仅限于GET、MGET操作,不包括搜 索。在5.x版本之前,GET/MGET的实时读取依赖于从translog中读取实现,5.x版本之后的版本改为refresh,因此系统对实时读取的支持会对写入速度有负面影响。
由此引出另一个较深层次的问题是,update操作需要先GET再 写,为了保证一致性,update调用GET时将realtime选项设置为 true,并且不可配置。因此update操作可能会导致refresh生成新的Lucene分段。
读失败是怎么处理的? 尝试从别的分片副本读取。
优先级 优先级策略只是将匹配到优先级的节点放到了目标节点列 表的前面。