选主流程
Discovery模块负责发现集群中的节点,以及选择主节点。ES支 持多种不同Discovery类型选择,内置的实现称为Zen Discovery, 其他的包括公有云平台亚马逊的EC2、谷歌的GCE等。
设计思想
所有分布式系统都需要以某种方式处理一致性问题。一般情况 下,可以将策略分为两组:试图避免不一致及定义发生不一致之后如 何协调它们。后者在适用场景下非常强大,但对数据模型有比较严格 的限制。因此这里研究前者,以及如何应对网络故障。
为什么使用主从模式
除主从(Leader/Follower)模式外,另一种选择是分布式哈希 表(DHT),可以支持每小时数千个节点的离开和加入,其可以在不 了解底层网络拓扑的异构网络中工作,查询响应时间大约为4到10跳 (中转次数),例如,Cassandra就使用这种方案。但是在相对稳定 的对等网络中,主从模式会更好。
ES的典型场景中的另一个简化是集群中没有那么多节点。通常, 节点的数量远远小于单个节点能够维护的连接数,并且网络环境不必 经常处理节点的加入和离开。这就是为什么主从模式更适合ES。
选举算法
在主节点选举算法的选择上,基本原则是不重复造轮子。最好实 现一个众所周知的算法,这样的好处是其中的优点和缺陷是已知的。 ES的选举算法的选择上主要考虑下面两种。
1. Bully算法
Leader选举的基本算法之一。它假定所有节点都有一个唯一的 ID,使用该ID对节点进行排序。任何时候的当前Leader都是参与集群 的最高ID节点。该算法的优点是易于实现。但是,当拥有最大ID的节 点处于不稳定状态的场景下会有问题。例如,Master负载过重而假 死,集群拥有第二大ID的节点被选为新主,这时原来的Master恢复, 再次被选为新主,然后又假死……
ES 通过推迟选举,直到当前的 Master 失效来解决上述问题,只 要当前主节点不挂掉,就不重新选主。但是容易产生脑裂(双主), 为此,再通过“法定得票人数过半”解决脑裂问题。
2. Paxos算法
Paxos非常强大,尤其在什么时机,以及如何进行选举方面的灵活 性比简单的Bully算法有很大的优势,因为在现实生活中,存在比网络 连接异常更多的故障模式。但 Paxos 实现起来非常复杂。
相关配置
与选主过程相关的重要配置有下列几个,并非全部配置。
discovery.zen.minimum_master_nodes:最小主节点数,这 是防止脑裂、防止数据丢失的极其重要的参数。这个参数的实际作用 早已超越了其表面的含义。除了在选主时用于决定“多数”,还用于多 处重要的判断,至少包含以下时机:
· 触发选主 进入选主的流程之前,参选的节点数需要达到法定人 数。
· 决定Master 选出临时的Master之后,这个临时Master需要判 断加入它的节点达到法定人数,才确认选主成功。
· gateway选举元信息 向有Master资格的节点发起请求,获取 元数据,获取的响应数量必须达到法定人数,也就是参与元信息选举 的节点数。
· Master发布集群状态 发布成功数量为多数。
为了避免脑裂,它的值应该是半数以上(quorum):
(master_eligible_nodes / 2) + 1discovery.zen.ping.unicast.hosts:集群的种子节点列表,构 建集群时本节点会尝试连接这个节点列表,那么列表中的主机会看到 整个集群中都有哪些主机。可以配置为部分或全部集群节点。可以像 下面这样指定:
discovery.zen.ping.unicast.hosts:
- 192.168.1.10:9300
- 192.168.1.11
- seeds.mydomain.com
默认使用9300端口,如果需要更改端口号,则可以在IP后手工指 定端口。也可以设置一个域名,让该域名解析到多个IP地址,ES会尝 试连接这个IP列表中的全部地址。
discovery.zen.ping.unicast.hosts.resolve_timeout:DNS 解 析超时时间,默认为5秒
discovery.zen.join_timeout:节点加入现有集群时的超时时 间,默认为 ping_timeout的20倍。
discovery.zen.join_retry_attempts join_timeout:超时之后 的重试次数,默认为3次。
discovery.zen.join_retry_delay join_timeout:超时之后,重 试前的延迟时间,默认为100毫秒。
discovery.zen.master_election.ignore_non_master_pings :设置为true时,选主阶段将忽略来自不具备Master资格节点 (node.master: false)的ping请求,默认为false。
discovery.zen.fd.ping_interval:故障检测间隔周期,默认为1 秒。
discovery.zen.fd.ping_timeout:故障检测请求超时时间,默 认为30秒。
discovery.zen.fd.ping_retries:故障检测超时后的重试次数, 默认为3次。
流程概述
ZenDiscovery的选主过程如下:
- 每个节点计算最小的已知节点ID,该节点为临时Master。向该 节点发送领导投票。
- 如果一个节点收到足够多的票数,并且该节点也为自己投票,那 么它将扮演领导者的角色,开始发布集群状态。
所有节点都会参与选举,并参与投票,但是,只有有资格成为 Master的节点(node.master为true)的投票才有效.
获得多少选票可以赢得选举胜利,就是所谓的法定人数。在 ES 中 , 法定大小是一个可配置的参数。配置项 : discovery.zen.minimum_master_nodes。为了避免脑裂,最小值 应该是有Master资格的节点数n/2+1。
流程分析
整体流程可以概括为:选举临时Master,如果本节点当选,则等 待确立Master,如果其他节点当选,则尝试加入集群,然后启动节点 失效探测器。具体如下图所示。

执行本流程的线程池:generic。
选举临时Master
选举过程的实现位于 ZenDiscovery#findMaster。该函数查找 当前集群的活跃 Master,或者从候选者中选择新的Master。如果选 主成功,则返回选定的Master,否则返回空。
为什么是临时Master?因为还需要等待下一个步骤,该节点的得 票数足够时,才确立为真正的Master。
临时Master的选举过程如下:
- (1)“ping”所有节点,获取节点列表fullPingResponses,ping 结果不包含本节点,把本节点单独添加到fullPingResponses中。
- (2)构建两个列表。
activeMasters列表:存储集群当前活跃Master列表。遍历第一 步获取的所有节点,将每个节点所认为的当前Master节点加入 activeMasters列表中(不包括本节点)。在遍历过程中,如果配置 了 discovery.zen.master_election.ignore_non_master_pings 为 true(默认为false),而节点又不具备Master资格,则跳过该节点。
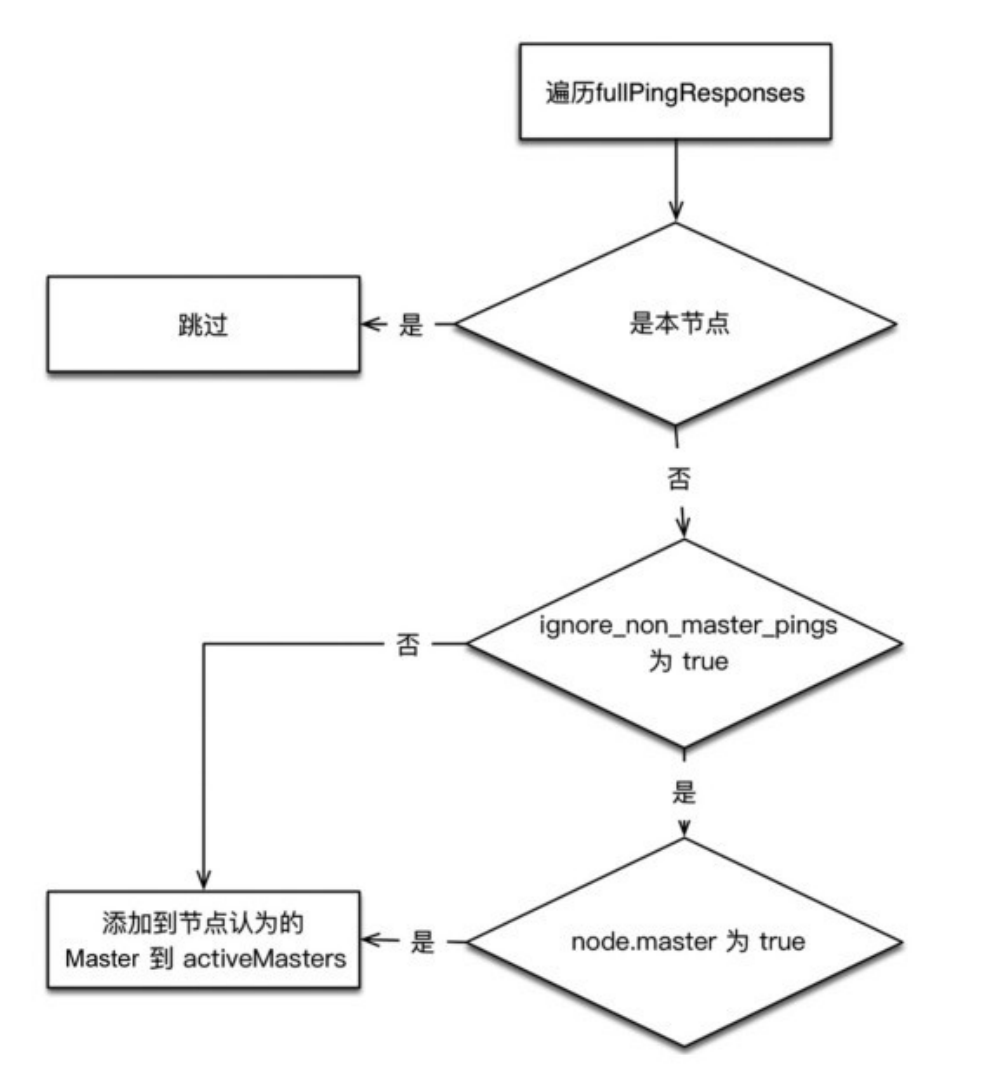
这个过程是将集群当前已存在的Master加入activeMasters列 表,正常情况下只有一个。如果集群已存在Master,则每个节点都记 录了当前Master是哪个,考虑到异常情况下,可能各个节点看到的当 前Master不同。在构建activeMasters列表过程中,如果节点不具备 Master资格,则可以通过ignore_non_master_pings选项忽略它认 为的那个Master。
masterCandidates列表:存储master候选者列表。遍历第一步 获取列表,去掉不具备Master资格的节点,添加到这个列表中。
- (3)如果activeMasters为空,则从masterCandidates中选 举,结果可能选举成功,也可能选举失败。如果不为空,则从 activeMasters中选择最合适的作为Master。

从masterCandidates中选主
与选主的具体细节实现封装在ElectMasterService类中,例如, 判断候选者是否足够,选择具体的节点作为Master等。
从masterCandidates中选主时,首先需要判断当前候选者人数 是否达到法定人数,否则选主失败
当候选者人数达到法定人数后,从候选者中选一个出来做 Master
这里只是将节点排序后选择最小的节点作为Master。但 是排序时使用自定义的比较函数 MasterCandidate::compare,早 期的版本中只是对节点 ID 进行排序,现在会优先把集群状态版本号高 的节点放在前面。
对于排序效果来说,如果 传入的两个节点中,有一个节点具备 Master 资格,而另一个不具 备,则把有 Master 资格的节点排在前面。如果都不具备Master资 格,或者都具备Master资格,则比较节点ID。
从activeMasters列表中选择 列表存储着集群当前存在活跃的Master,从这些已知的Master节 点中选择一个作为选举结果。选择过程非常简单,取列表中的最小 值,比较函数仍然通过compareNodes实现,activeMasters列表中 的节点理论情况下都是具备Master资格的。
投票与得票的实现
在ES中,发送投票就是发送加入集群(JoinRequest)请求。得 票就是申请加入该节点的请求的数量。
当节点检查收到的投票是否足够时,就是检查加入它的连接数是否足够,其中会去掉没有Master资格节点的投票
确立Master或加入集群
选举出的临时Master有两种情况:该临时Master是本节点或非本 节点。为此单独处理。现在准备向其发送投票。
如果临时Master是本节点:
- (1)等待足够多的具备Master资格的节点加入本节点(投票达 到法定人数),以完成选举。
- (2)超时(默认为30秒,可配置)后还没有满足数量的join请 求,则选举失败,需要进行新一轮选举。
- (3)成功后发布新的clusterState。
如果其他节点被选为Master:
- (1)不再接受其他节点的join请求。
- (2)向Master发送加入请求,并等待回复。超时时间默认为1分 钟(可配置),如果遇到异常,则默认重试3次(可配置)。这个步骤 在joinElectedMaster方法中实现。
- (3)最终当选的Master会先发布集群状态,才确认客户的join请 求,因此,joinElectedMaster返回代表收到了join请求的确认,并且 已经收到了集群状态。本步骤检查收到的集群状态中的Master节点如 果为空,或者当选的Master不是之前选择的节点,则重新选举。
节点失效检测
到此为止,选主流程已执行完毕,Master身份已确认,非Master 节点已加入集群。
节点失效检测会监控节点是否离线,然后处理其中的异常。失效 检测是选主流程之后不可或缺的步骤,不执行失效检测可能会产生脑 裂(双主或多主)。在此我们需要启动两种失效探测器:
- 在 Master 节 点 , 启 动 NodesFaultDetection , 简 称 NodesFD。定期探测加入集群的节点是否活跃。
- 在 非 Master 节 点 启 动 MasterFaultDetection , 简 称 MasterFD。定期探测Master节点是否活跃。
NodesFaultDetection和MasterFaultDetection都是通过定期 (默认为1秒)发送的ping请求探测节点是否正常的,当失败达到一定 次数(默认为3次),或者收到来自底层连接模块的节点离线通知时, 开始处理节点离开事件。
NodesFaultDetection事件处理
检查一下当前集群总节点数是否达到法定节点数(过半),如果 不足,则会放弃 Master 身份,重新加入集群。为什么要这么做?设 想下面的场景,如下图所示。 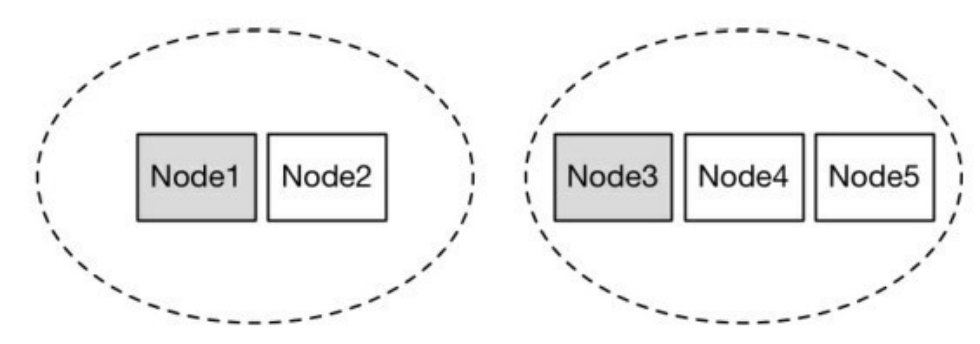
假设有5台机器组成的集群产生网络分区,2台组成一组,另外3 台组成一组,产生分区前,原Master为Node1。此时3台一组的节点 会重新选举并成功选取Noded3作为Master,会不会产生双主? NodesFaultDetection就是为了避免上述场景下产生双主。
MasterFaultDetection事件处理
探测Master离线的处理很简单,重新加入集群。本质上就是该节 点重新执行一遍选主的流程。
最后
选主流程在集群中启动,从无主状态到产生新主时执行,同时集 群在正常运行过程中, Master探测到节点离开,非Master节点探测 到Master离开时都会执行。