Snapshot模块分析
快照模块是ES备份、迁移数据的重要手段。它支持增量备份,支 持多种类型的仓库存储。仓库用于存储快照,支持共享文件系统(例如,NFS),以及通过 插 件 支 持 的 HDFS 、 AmazonS3 、 Microsoft Azure 、 Google GCS。
升级集群前建议先通过快照备份数据。跨越大版本的数据迁移可 以考虑使用reindex API。
当需要迁移数据时,可以将快照恢复到另一个集群。快照不仅可 以对索引备份,还可以将模板一起保存。恢复到的目标集群不需要相 同的节点规模,只要它的存储空间足够容纳这些数据即可。
要使用快照,首先应该注册仓库。快照存储于仓库中。
仓库
仓库用于存储创建的快照。建议为每个大版本创建单独的快照存 储库。如果使用多个集群注册相同的快照存储库,那么最好只有一个 集群对存储库进行写操作。连接到该存储库的其他集群都应该将存储 库设置为readonly模式。
使用下面的命令注册一个仓库: 
本例中,注册的仓库名称为my_backup,type为fs,指定仓库类 型为共享文件系统。共享文件系统支持的配置如下表所示。 
要获取某个仓库配置信息,可以使用下面的API:
curl -X GET "localhost:9200/_snapshot/my_backup"要获取多个存储库的信息,可以指定一个以逗号分隔的存储库列 表,还可以在指定存储库名称时使用“*”通配符。例如:
curl -X GET "localhost:9200/_snapshot/repo*,*backup*要获取当前全部仓库的信息,可以省略仓库名称,使用_all:
curl -X GET "localhost:9200/_snapshot
或
curl -X GET "localhost:9200/_snapshot/_all共享文件系统
当使用共享文件系统时,需要将同一个共享存储挂载到集群每个 节点的同一个挂载点(路径),包括所有数据节点和主节点。然后将 这个挂载点配置到elasticsearch.yml的path.repo字段。例如,挂载 点为/mnt/my_backup,那么在elasticsearch.yml中应该添加如下 配置:
path.repo: ["/mnt/my_backups"]path.repo配置以数组的形式支持多个值。如果配置多个值,则不 像path.data一样同时使用这些路径,相反,应该为每个挂载点注册不 同的仓库。例如,一个挂载点存储空间不足以容纳集群所有数据,可 使用多个挂载点,同时注册多个仓库,将数据分开快照到不同的仓库。
path.repo支持微软的UNC路径,配置格式如下:
path.repo: ["\\\\MY_SERVER\\Snapshots"]当配置完毕,需要重启所有节点使之生效。然后就可以通过仓库 API注册仓库,执行快照了。
使用共享存储的优点是跨版本兼容性好,适合迁移数据。缺点是 存储空间较小。如果使用HDFS,则受限于插件使用的HDFS版本。插 件版本要匹配ES,而这个匹配的插件使用固定版本的HDFS客户端。 一个HDFS客户端只支持写入某些兼容版本的HDFS集群。
快照
创建快照
存储库可以包含同一集群的多个快照。每个快照有唯一的名称标 识 。 通 过 以 下 命 令 在 my_backup 仓 库 中 为 全 部 索 引 创 建 名 为snapshot_1的快照:
curl -X PUT "
localhost:9200/_snapshot/my_backup/snapshot_1?
wait_for_completion=true"wait_for_completion参数是可选项,默认情况下,快照命令会 立即返回,任务在后台执行。如果想等待任务完成API才返回,则可以 将wait_for_completion参数设置为true,默认为false。
上述命令会为所有open状态的索引创建快照。如果想对部分索引 执行快照,则可以在请求的indices参数中指定: 
indices 字 段 支 持 多 索 引 语 法 , index_* 完 整 的 语 法 参 考 :https://www.elastic.co/guide/en/elasticsearch/reference/current/multi-index.html
另外两个参数:
ignore_unavailable, 跳过不存在的索引。默认为false, 因此默认情况下遇到不存在的索引快照失败。
include_global_state, 不快照集群状态。默认为false。注 意,集群设置和模板保存在集群状态中,因此默认情况下不快照集群 设置和模板,但是一般情况下我们需要将这些信息一起保存。
快照操作在主分片上执行。快照执行期间,不影响集群正常的读 写操作。在快照开始前,会执行一次flush,将操作系统内存“cache” 的数据刷盘。因此通过快照可以获取从成功执行快照的时间点开始, 磁盘中存储的Lucene数据,不包括后续的新增内容。但是每次快照过 程是增量的,下一次快照只会包含新增内容。
可以在任何时候为集群创建一个快照过程,无论集群健康是 Green、Yellow,还是Red。执行快照期间,被快照的分片不能移动到另一个节点,这可能会干扰重新平衡过程和分配过滤(allocation filtering)。这种分片迁移只可以在快照完成时进行。 快照开始后,可以用快照信息API和status API来监控进度。
获取快照信息
当快照开始后,使用下面的API来获取快照的信息:
curl -X GET "
localhost:9200/_snapshot/my_backup/snapshot_1"主要是开始结束时间、集群版本、当前阶段、成功及失败情况等 基本信息。快照执行期间会经历以下几个阶段,如下表所示。  如果一些快照不可用导致命令失败,则可以通过设置布尔参数 ignore_unavailable来返回当前可用的所有快照。
如果一些快照不可用导致命令失败,则可以通过设置布尔参数 ignore_unavailable来返回当前可用的所有快照。
快照status
_status API用于返回快照的详细信息。 可以使用下面的命令来查询当前正在运行的全部快照的详细状态 信息:
curl -X GET "localhost:9200/_snapshot/_status"取消、删除快照和恢复操作
在设计上,快照和恢复在同一个时间点只允许运行一个快照或一 个恢复操作。如果想终止正在进行的快照操作,则可以使用删除快照 命令来终止它。删除快照操作将检查当前快照是否正在运行,如果正 在运行,则删除操作会先停止快照,然后从仓库中删除数据。如果是 已完成的快照,则直接从仓库中删除快照数据。
curl -X DELETE "
localhost:9200/_snapshot/my_backup/snapshot_1"恢复操作使用标准分片恢复机制。因此,如果要取消正在运行的 恢复,则可以通过删除正在恢复的索引来实现。注意,索引数据将全 部删除。
从快照恢复
要恢复一个快照,目标索引必须处于关闭状态。 使用下面的命令恢复一个快照:
curl -X POST "
localhost:9200/_snapshot/my_backup/snapshot_1/_restore"默认情况下,快照中的所有索引都被恢复,但不恢复集群状态。 通过调节参数,可以有选择地恢复部分索引和全局集群状态。索引列 表支持多索引语法。 
恢复完成后,当前集群与快照同名的索引、模板会被覆盖。在集 群中存在,但快照中不存在的索引、索引别名、模板不会被删除。因 此恢复并非同步成与快照一致。
部分恢复
默认情况下,在恢复操作时,如果参与恢复的一个或多个索引在 快照中没有可用分片,则整个恢复操作失败。这可能是因为创建快照 时一些分片备份失败导致的。可以通过设置 partial参数为true来尽可 能恢复。但是,只有备份成功的分片才会成功恢复,丢失的分片将被 创建一个空的分片。
监控恢复进度
恢复过程是基于ES标准恢复机制的,因此标准的恢复监控服务可 以用来监视恢复的状态。当执行集群恢复操作时通常会进入Red状 态,这是因为恢复操作是从索引的主分片开始的,在此期间主分片状 态变为不可用,因此集群状态表现为Red。一旦ES主分片恢复完成, 整个集群的状态将被转换成Yellow,并且开始创建所需数量的副分 片。一旦创建了所有必需的副分片,集群转换到Green状态。
查看集群的健康情况只是在恢复过程中比较高级别的状态,还可 以通过使用 indices recovery与cat recovery的API来获得更详细的 恢复过程信息与索引的当前状态信息。
创建快照的实现原理
在快照的实现原理中我们重点关注几个问题:快照是如何实现 的?增量过程是如何实现的?为什么删除旧快照不影响其他快照?
ES的快照创建是基于Lucene快照实现的。但是Lucene中的快照 概念与ES的并不相同。
Lucene快照是对最后一个提交点的快照,一次快照包含最后一次 提交点的信息,以及全部分段文件。因此这个快照实际上就是对已刷 盘数据的完整的快照。注意Lucene中没有增量快照的概念。每一次都 是对整个Lucene索引完整快照,它代表这个Lucene索引的最新状 态。之所以称为快照,是因为从创建一个Lucene快照开始,与此快照 相 关 的 物 理 文 件 都 保 证 不 会 删 除 。在 Lucene 中 , 快 照 通 过 SnapshotDeletionPolicy实现。从Lucene 2.3版本开始支持。
你可能还记得,在副分片的恢复过程中,也需要对主分片创建 Lucene快照,然后复制数据文件。
因此总结来说:
- Lucene快照负责获取最新的、已刷盘的分段文件列表,并保证 这些文件不被删除,这个文件列表就是ES要执行复制的文件。
- ES负责数据复制、仓库管理、增量备份,以及快照删除。
创建快照的整体过程如下图所示。 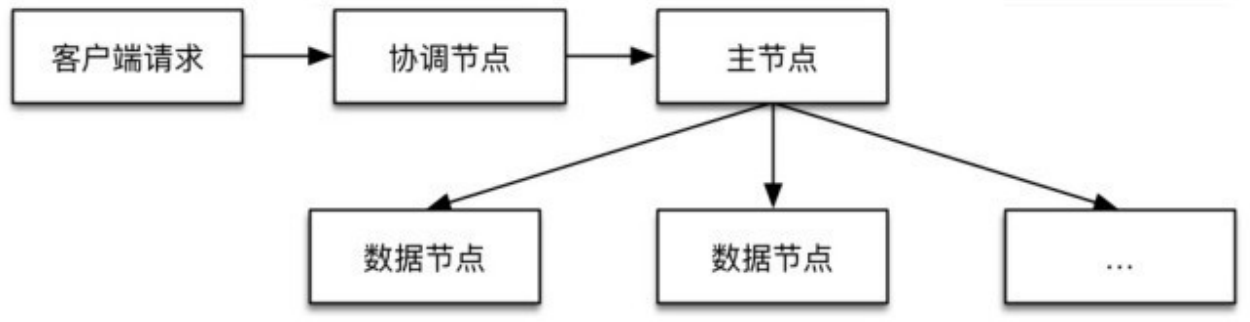
ES创建快照的过程涉及3种类型的节点:
- 协调节点, 接收客户端请求,转发到主节点。
- 主节点, 将创建快照相关的请求信息放到集群状态中广播下 去,数据节点收到后执行数据复制。同时负责在仓库中写入集群状态 数据。
- 数据节点, 负责将Lucene文件复制到仓库,并在数据复制完毕 后清理仓库中与任何快照都不相关的文件。由于数据分布在各个数据 节点,因此复制操作必须由数据节点执行。每个数据节点将快照请求 中本地存储的主分片复制到仓库。
快照过程是对Lucene物理文件的复制过程,一个Lucene索引由 许多不同类型的文件组成,完整的介绍可以参考 Lucene 官方手册
如果数据节点在执行快照过程中异常终止,例如,I/O错误,进程 被“kill”,服务器断电等异常,则这个节点上执行的快照尚未成功,当 这个节点重新启动,不会继续之前的数据复制流程。对于整个快照进 程来说,最终结果是部分成功、部分失败。快照信息中会记录失败的 节点和分片,以及与错误相关的原因。
Lucene文件格式简介
1. 定义 Lucene中基本的概念包括index、document、field和term。 一个index包含一系列的document:
· 一个document是一系列的fields;
· 一个field是一系列命名的terms;
· 一个term是一系列bytes。2. 分段 Lucene索引可能由多个分段(segment)组成,每个分段是一 个完全独立的索引,可以独立执行搜索。有两种情况产生新的分段:
· refresh操作产生一个Lucene分段。为新添加的documents创
建新的分段。
· 已存在的分段合并,产生新分段。一次对Lucene索引的搜索需要搜索全部分段。
3. 文件命名规则
属于一个段的所有文件都具有相同的名称和不同的扩展名。当使 用复合索引文件(默认)时,除.si write.lock .del外的其他文件被 合并压缩成单个.cfs文件。 文件名不会被重用,也就是说,任何文件被保存到目录中时,它 有唯一的文件名。这是通过简单的生成方法实现的,例如,第一个分 段文件名为segments_1,接下来是segments_2。
4. 文件扩展名摘要

协调节点流程
协调节点负责解析请求,将请求转发给主节点。
处理线程:http_server_worker。
协调节点注册的 REST action为create_snapshot_action,相 应的 Handler为 RestCreateSnapshotAction类。当协调节点收到客 户端请求后,在BaseRestHandler#handleRequest中处理请求,调 用 RestCreateSnapshotAction#prepareRequest 解析 REST 请 求,将请求封装为CreateSnapshotRequest结构,然后将该请求发 送到Master节点。
在TransportMasterNodeAction.AsyncSingleAction#doStart 方法中,判断本地是否是主节点,如果是主节点,则转移到snapshot 线程处理,否则发送action为cluster:admin/snapshot/create的 RPC请求到主节点,request为组装好的CreateSnapshotRequest结 构。
从 实 现 角 度 来 说 , 协 调 节 点 和 主 节 点 都 会 执 行 TransportMasterNodeAction.AsyncSingleAction#doStart方法, 只是调用链不同。
主节点流程
主节点的主要处理过程是将请求转换成内部需要的数据结构,提 交一个集群任务进行处理,集群任务处理后生成的集群状态中会包含 请求快照的信息,主节点将新生成的集群状态广播下去,数据节点收 到后执行相应的实际数据的快照处理。
执 行 本 流 程 的 线 程 池 : http_server_worker->snapshot-> masterService#updateTask。
主 节 点 收 到 协 调 节 点 发 来 的 请 求 也 是 在 TransportMasterNodeAction. AsyncSingleAction#doStart 方法 中 处 理 的 , 在 snapshot 线 程 池 中 执 行 TransportCreateSnapshotAction#masterOperation 方法。将收 到的 CreateSnapshotRequest 请求转换成 SnapshotsService.SnapshotRequest 结 构 , 调 用 snapshotsService.createSnapshot方法提交一个集群任务。
提交的任务在masterService#updateTask线程中执行。在任务 中对请求做非法检查,以及是否已经有快照在执行等验证操作,然后 将快照请求的相关信息放入集群状态中,广播到集群的所有节点,触 发数据节点对实际数据的处理。快照信息在集群状态的customs字段 中
主节点控制数据节点执行快照的方式,就是通过把要执行的快照 命令放到集群信息中广播下去。在执行快照过程中,主节点分成两个 步骤,下发两次集群状态。首次发送时,快照信息中的 State 设置为 INIT,数据节点进行一些初始化操作。待数据节点将这个集群状态处 理完毕后,主节点准备下发第二次集群状态。 第二次集群状态在SnapshotsService#beginSnapshot方法中 构建。 在下发第二次集群状态前,主节点会先将全局元信息和索引的元 数据信息写入仓库。
在新的集群状态中,将State设置为STARTED,并且根据将要快 照的索引列表计算出分片列表(注意全是主分片),数据节点收到后 真正开始执行快照。
数据节点流程
数据节点负责实际的快照实现,从全部将要快照的分片列表中找 出存储于本节点的分片,对这些分片创建Lucene快照,复制文件。
1. 对ClusterState的处理 对 收 到 的 集 群 状 态 的 处 理 在 clusterApplierService#updateTask 线程池中。启动快照时,在 snapshot线程池中。 数据节点对主节点发布的集群状态(ClusterState)的统一处理 在 ClusterApplierService#callClusterStateListeners 方 法 中 , clusterStateListeners 中存储了所有需要对集群状态进行处理的模 块。当收到集群状态时,遍历这个列表,调用各个模块相应的处理函 数 。 快 照 模 块 对 此 的 处 理 在 SnapshotShardsService#clusterChanged方法中。在该方法中, 在 做 完 一 些 简 单 的 验 证 之 后 , 调 用 SnapshotShardsService#processIndexShardSnapshots 进 入主 要处理逻辑。
数据节点对第一次集群状态的处理实际上没做什么有意义的操 作。对第二次集群状态的处理是真正快照的核心实现。
主节点第二次下发的集群状态中包含了要进行快照的分片列表。 数据节点收到后过滤一下本地有哪些分片,构建一个新的列表,后续 要进行快照的分片就在这个列表中。
然后遍历本地要处理的分片列表,在snapshot线程池中对分片并 行执行快照处理。并行数量取决于snapshot线程池中的线程个数,默 认的线程数最大值为:min(5, (处理器数量)/2)
处理完毕后,向主节点发送RPC请求以更新相应分片的快照状 态。
2. 对一个特定分片的快照实现
Lucene快照
Lucene的快照在SnapshotDeletionPolicy#snapshot方法中实 现。该方法返回一个提交点,通过提交点可以获取分片的最新状态, 包括全部Lucene 分段文件的列表。从得到这个列表开始,列表中的 文件都不会被删除,直到释放提交点。
ES快照整体过程
数 据 节 点 在 snapshot 线 程 池 中 执 行 SnapshotShardsService#snapshot方法,对特定分片创建快照。 在做完一些验证工作后,调用 Lucene 接口创建快照,返回 Engine.IndexCommitRef,其中含有最重要的提交点。然后根据 Lucene提交点创建ES快照
根据Lucene提交点计算两个列表
当前的Lucene提交点代表分片的最新状态,它包含全部Lucene 分段。如果不考虑增量备份,则把这个文件列表全部复制到仓库就可 以了。但是我们要实现的是每次快照都是增量的。实现方法就是计算 出两个列表:
(1)新增文件列表,代表将要复制到仓库的文件。遍历Lucene 提交点中的文件列表,如果仓库中已存在,则过滤掉,得到一个新增 文件列表。
(2)当前快照使用的全部文件列表,未来通过它找到某个快照相 关的全部相关文件。这个列表的内容就是Lucene提交点中的文件列表 的全部文件。
在此我们需要介绍Lucene文件的“不变性”,除了write.lock、 segments.gen两个文件,其他所有文件都不会更新,只写一次 (write once)。锁文件 write.lock 不需要复制。segments.gen是 较早期的Lucene版本中存在的一种文件,我们不再讨论。因此,所有 需要复制的文件都是不变的,无须考虑被更新的可能。所以在增量备 份时,通过文件名就可以识别唯一的文件。但是在存储到仓库时,ES 将文件全部重命名为以一个递增序号为名字的文件,并维护了对应关 系。
复制Lucene物理文件
在开始复制之前,快照任务被设置为STARTED阶段。现在开始复制新增文件,遍历新增文件列表,将这些文件复制到仓库。
复制过程中实现限速,并且计算校验和。Lucene 每个文件的元 信息中有计算好的校验和,在数据复制过程中,一边复制,一边计 算,复制完毕后对比校验和是否相同,以验证复制结果是否正确。校 验和很重要,在手工备份数据时,复制完毕后我们实际上不知道复制 的数据是否正确。校验和是对数据进行整型加法的计算,不会消耗多 少CPU资源。
复制文件的blobContainer.writeBlob是一个虚方法,对于不同 的仓库文件系统有不同的实现,对于共享文件系统(fs)来说,复制过 程通过Streams.copy实现,并在复制完成后执行IOUtils.fsync刷 盘。
生成快照文件
删除快照无关文件
遍历仓库中的全部快照,包括刚刚执行完的快照,删除仓库中不 被任何快照关联的文件。
删除快照实现原理
ES删除快照的核心思想就是,在要删除的快照所引用的物理文件 中,对不被任何其他快照使用的文件执行删除。每个快照都在自己的 元信息文件(snap-*)中描述了本快照使用的文件列表。想要删除一 些文件时,也不需要引用计数,只要待删除文件不被其他快照使用就 可以安全删除。
快照删除过程/取消过程涉及3种类型的节点:
· 协调节点, 接收客户端请求、转发到主节点。
· 主节点, 将删除创建快照相关的请求信息放到集群状态中广播
下去,删除快照和取消运行中的快照是同一个请求。数据节点负责取
消运行中的快照创建任务,主节点负责删除已创建完毕的快照。无论
如何,集群状态都会广播下去。当集群状态发布完毕,主节点开始执
行删除操作。所以现在知道为什么主节点也要访问仓库了。删除操作
确实没有必要要求各个数据节点去执行,任何节点都能看到仓库的全
部数据,只需要单一节点执行删除即可,因此删除操作由主节点执
行。
· 数据节点,负责取消正在运行的快照任务。协调节点流程
协调节点的任务与创建快照时相同,负责协调节点负责解析请 求,将请求转发给主节点。
处理线程:http_server_worker。删除快照的相应的 REST action 为 delete_snapshot_action。注册的 Handler 为 RestDeleteSnapshotAction。收到删除快照的 REST请求后,同样在BaseRestHandler#handleRequest中进行处 理,然后调用 RestDeleteSnapshotAction#prepareRequest 解析 REST 请求,将请求封装为DeleteSnapshotRequest结构,然后将 该请求发送到Master节点。
同 样 在TransportMasterNodeAction.AsyncSingleAction#doStart 方 法 中判断本地是否是主节点,如果是主节点,则本地在 snapshot 线程 池 中 执 行 , 否 则 将 转 发 过 去 , 请 求 的 action 为 cluster:admin/snapshot/delete
主节点流程
主节点收到协调节点的请求后提交集群任务,将请求信息放到新 的集群状态中广播下去,数据节点收到后检查是否有运行中的快照任 务需要取消,如果没有,则不做其他操作。主节点的集群状态发布成 功后,执行快照删除操作。 执 行 本 流 程 的 线 程 池 : http_server_worker->generic-> masterService#updateTask->snapshot。 主 节 点 收 到 协 调 节 点 发 来 的 请 求 也 是 在 TransportMasterNodeAction.AsyncSingleAction#doStart方法中 处 理 的 , 在 generic 线 程 池 中 执 行 TransportDeleteSnapshotAction#masterOperation,接着调用 SnapshotsService#deleteSnapshot提交集群任务。
1. 提交集群任务 将删除快照请求信息放到集群状态中,当集群状态发布成功后, 执行删除快照逻辑。
主节点会判断要删除的快照是正在进行中的,还是已完成的,对 进行中的快照执行取消逻辑,对已完成的快照执行删除逻辑,构建出 的集群状态是不同的。 对于删除过程,下发的集群状态内容如下图所示。删除请求信息 放在customs的SnapshotDeletionsInProgress字段中。
对于取消过程,下发的集群状态内容如下图所示。删除请求信息 放在 customs 的SnapshotsInProgress字段中,并将State设置为 ABORTED。创建快照时也放在SnapshotsInProgress字段中,区别 就是创建快照时State为STARTED。由于删除操作在主节点上执行,接下来我们进入主节点的快照删 除过程。
2. 快照删除 主节点的集群状态发布完毕,clusterStateProcessed方法负责 发 布 成 功 后 的 处 理 逻 辑 。 执 行 该 方 法 的 线 程 池 为 masterService#updateTask , 它 调 用 SnapshotsService#deleteSnapshotFromRepository方法执行删 除。该方法会转移到snapshot线程池执行具体的删除工作。
需要删除的内容包括元信息文件、索引分片,以及有可能要删除 的整个索引目录,并且更新快照列表的index文件(index-*)。
调用创建快照时相同的finalize方法,调用该方法时传入一个快照 列表,内部执行时遍历仓库中的文件,删除不被快照列表引用的文 件。在创建快照时传入全部快照列表,在删除快照时,传入的是需要 保留的快照列表。
3. 数据节点的取消过程 取消快照请求信息放在customs的SnapshotsInProgress字段 中 , State 为 ABORTED 。 数 据 节 点 对 此 的 处 理 在 SnapshotShardsService#processIndexShardSnapshots 方 法 中。创建快照的主要过程也在这个方法中,根据State状态判断需要启 动或取消运行中的快照。
快照运行过程中有多处会检查中止标识: · 在计算需要复制的Lucene文件列表时; · 在开始执行复制之前; · 在数据开始复制数据之后的读取过程中。
由于运行中的快照大部分时间在执行数据复制,因此取消操作大 部分在读取数据时中断。
运行中的快照被取消后,复制到一半的快照数据文件由主节点负 责清理。这个过程在主节点发布集群状态成功之后的快照删除逻辑中 执行,对一个已经取消的快照,执行正常的快照删除过程。
最后
- 主节点将快照命令放到集群状态中广播下去,以此控制数据节点 执行任务。数据节点执行完毕向主节点主动汇报状态。
- ES的配置文件更新后不能动态生效。但是提供了REST接口来调 整需要动态更新的参数。path.repo 字段需要写到配置文件中。当需 要迁移数据时就要先改配置重启集群,这样就不够方便。为什么不放 在REST请求信息中,而要求配置到文件里?
- 集群永久设置、模板都保存在集群状态中,默认为不进行快照和 恢复。注意索引别名不在集群状态中。快照默认会保存别名信息。
- Lucene段合并会导致增量快照时产生新增内容。当段文件比较 小时,在HDFS中可能会产生许多小文件。因此通过force_merge API 手工合并分段也有利于减少HDFS上的这些小文件。
- 快照写入了两个层面的元数据信息:集群层和索引层。
- 快照与集群是否健康无关,集群Red时也可以对部分索引执行快 照。
- 数据复制过程中会计算校验和,确保复制后数据的正确性。
- 数据节点并发复制数据时取决于线程池的线程数的最大值,该值 为 min(5,(处理器数量)/2)。
- 快照只对主分片执行。