Go汇编语言
快速入门
Go汇编语言并不是一个独立的语言,因为Go汇编程序无法独立使用。Go汇编代码 必须以Go包的方式组织,同时包中至少要有一个Go语言文件用于指明当前包名等 基本包信息。如果Go汇编代码中定义的变量和函数要被其它Go语言代码引用,还 需要通过Go语言代码将汇编中定义的符号声明出来。用于变量的定义和函数的定义 Go汇编文件类似于C语言中的.c文件,而用于导出汇编中定义符号的Go源文件类似 于C语言的.h文件
定义整数变量
package pkg
var Id = 9527代码中只定义了一个int类型的包级变量,并进行了初始化。然后用以下命令查看的 Go语言程序对应的伪汇编代码:
$ go tool compile -S pkg.go
"".Id SNOPTRDATA size=8
0x0000 37 25 00 00 00 00 00 00 .....其中 go tool compile 命令用于调用Go语言提供的底层命令工具,其中 -S 参 数表示输出汇编格式。输出的汇编比较简单,其中 "".Id 对应Id变量符号,变量 的内存大小为8个字节。变量的初始化内容为 37 25 00 00 00 00 00 00 ,对应 十六进制格式的0x2537,对应十进制为9527。SNOPTRDATA是相关的标志,其中 NOPTR表示数据中不包含指针数据。
以上的内容只是目标文件对应的汇编,和Go汇编语言虽然相似当并不完全等价。 Go语言官网自带了一个Go汇编语言的入门教程,地址 在:https://golang.org/doc/asm 。
Go汇编语言提供了DATA命令用于初始化包变量,DATA命令的语法如下:
DATA symbol+offset(SB)/width, value其中symbol为变量在汇编语言中对应的标识符,offset是符号开始地址的偏移量, width是要初始化内存的宽度大小,value是要初始化的值。其中当前包中Go语言定 义的符号symbol,在汇编代码中对应 ·symbol ,其中“·”中点符号为一个特殊的 unicode符号。
我们采用以下命令可以给Id变量初始化为十六进制的0x2537,对应十进制的 9527(常量需要以美元符号$开头表示):
DATA ·Id+0(SB)/1,$0x37
DATA ·Id+1(SB)/1,$0x25变量定义好之后需要导出以供其它代码引用。Go汇编语言提供了GLOBL命令用于 将符号导出:
GLOBL symbol(SB), width其中symbol对应汇编中符号的名字,width为符号对应内存的大小。用以下命令将 汇编中的·Id变量导出:
GLOBL ·Id, $8为了便于其它包使用该Id变量,我们还需要在Go代码中声明该变量,同时也给变量 指定一个合适的类型。修改pkg.go的内容如下:
package pkg
var Id int现状Go语言的代码不再是定义一个变量,语义变成了声明一个变量(声明一个变量 时不能再进行初始化操作)。而Id变量的定义工作已经在汇编语言中完成了。
我们将完整的汇编代码放到pkg_amd64.s文件中:
GLOBL ·Id(SB),$8
DATA ·Id+0(SB)/1,$0x37
DATA ·Id+1(SB)/1,$0x25
DATA ·Id+2(SB)/1,$0x00
DATA ·Id+3(SB)/1,$0x00
DATA ·Id+4(SB)/1,$0x00
DATA ·Id+5(SB)/1,$0x00
DATA ·Id+6(SB)/1,$0x00
DATA ·Id+7(SB)/1,$0x00文件名pkg_amd64.s的后缀名表示AMD64环境下的汇编代码文件。 虽然pkg包是用汇编实现,但是用法和之前的Go语言版本完全一样:
package main
import pkg "pkg包的路径"
func main() {
println(pkg.Id)
}定义字符串变量
虽然从Go语言角度看,定义字符串和整数变量的写法基本相同,但是字符串底层却有着比单个整数更复杂的数据结构。
package pkg
var Name = "gopher"然后用以下命令查看的Go语言程序对应的伪汇编代码:
$ go tool compile -S pkg.go
go.string."gopher" SRODATA dupok size=6
0x0000 67 6f 70 68 65 72 gopher
"".Name SDATA size=16
0x0000 00 00 00 00 00 00 00 00 06 00 00 00 00 00 00 00 ......
..........
rel 0+8 t=1 go.string."gopher"+0输出中出现了一个新的符号go.string."gopher",根据其长度和内容分析可以猜测是 对应底层的"gopher"字符串数据。因为Go语言的字符串并不是值类型,Go字符串 其实是一种只读的引用类型。如果多个代码中出现了相同的"gopher"只读字符串 时,程序链接后可以引用的同一个符号go.string."gopher"。因此,该符号有一个 SRODATA标志表示这个数据在只读内存段,dupok表示出现多个相同标识符的数 据时只保留一个就可以了。
而真正的Go字符串变量Name对应的大小却只有16个字节了。其实Name变量并没 有直接对应“gopher”字符串,而是对应16字节大小的reflect.StringHeader结构体:
type reflect.StringHeader struct {
Data uintptr
Len int
}从汇编角度看,Name变量其实对应的是reflect.StringHeader结构体类型。前8个字 节对应底层真实字符串数据的指针,也就是符号go.string."gopher"对应的地址。后 8个字节对应底层真实字符串数据的有效长度,这里是6个字节。
现在创建pkg_amd64.s文件,尝试通过汇编代码重新定义并初始化Name字符串:
GLOBL ·NameData(SB),$8
DATA ·NameData(SB)/8,$"gopher"
GLOBL ·Name(SB),$16
DATA ·Name+0(SB)/8,$·NameData(SB)
DATA ·Name+8(SB)/8,$6因为在Go汇编语言中,go.string."gopher"不是一个合法的符号,因此我们无法通过 手工创建(这是给编译器保留的部分特权,因为手工创建类似符号可能打破编译器 输出代码的某些规则)。因此我们新创建了一个·NameData符号表示底层的字符串 数据。然后定义·Name符号内存大小为16字节,其中前8个字节用·NameData符号 对应的地址初始化,后8个字节为常量6表示字符串长度。
当用汇编定义好字符串变量并导出之后,还需要在Go语言中声明该字符串变量。然 后就可以用Go语言代码测试Name变量了:
package main
import pkg "path/to/pkg"
func main() {
println(pkg.Name)
}不幸的是这次运行产生了以下错误:
pkgpath.NameData: missing Go type information for global symbol:
size 8错误提示汇编中定义的NameData符号没有类型信息。其实Go汇编语言中定义的数 据并没有所谓的类型,每个符号只不过是对应一块内存而已,因此NameData符号 也是没有类型的。但是Go语言是再带垃圾回收器的语言,而Go汇编语言是工作在 自动垃圾回收体系框架内的。当Go语言的垃圾回收器在扫描到NameData变量的时 候,无法知晓该变量内部是否包含指针,因此就出现了这种错误。错误的根本原因 并不是NameData没有类型,而是NameData变量没有标注是否会含有指针信息。 通过给NameData变量增加一个NOPTR标志,表示其中不会包含指针数据可以修复 该错误:
#include "textflag.h"
GLOBL ·NameData(SB),NOPTR,$8通过给·NameData增加NOPTR标志的方式表示其中不含指针数据。我们也可以通 过给·NameData变量在Go语言中增加一个不含指针并且大小为8个字节的类型来修 改该错误:
package pkg
var NameData [8]byte
var Name string我们将NameData声明为长度为8的字节数组。编译器可以通过类型分析出该变量会包含指针,因此汇编代码中可以省略NOPTR标志。现在垃圾回收器在遇到该量的时候就会停止内部数据的扫描。在这个实现中,Name字符串底层其实引用的是NameData内存对应的“gopher”字串数据。因此,如果NameData发生变化,Name字符串的数据也会跟着变化
func main() {
println(pkg.Name)
pkg.NameData[0] = '?'
println(pkg.Name)
}当然这和字符串的只读定义是冲突的,正常的代码需要避免出现这种情况。最好的 方法是不要导出内部的NameData变量,这样可以避免内部数据被无意破坏。
在用汇编定义字符串时我们可以换一种思维:将底层的字符串数据和字符串头结构 体定义在一起,这样可以避免引入NameData符号:
GLOBL ·Name(SB),$24
DATA ·Name+0(SB)/8,$·Name+16(SB)
DATA ·Name+8(SB)/8,$6
DATA ·Name+16(SB)/8,$"gopher"在新的结构中,Name符号对应的内存从16字节变为24字节,多出的8个字节存放 底层的“gopher”字符串。·Name符号前16个字节依然对应reflect.StringHeader结构 体:Data部分对应 $·Name+16(SB) ,表示数据的地址为Name符号往后偏移16个 字节的位置;Len部分依然对应6个字节的长度。这是C语言程序员经常使用的技 巧。
定义main函数
我们现在将尝试用汇编实现函数,然后输出一个字符串。先创建main.go文件,创建并初始化字符串变量,同时声明main函数:
package main
var helloworld = "你好, 世界"
func main()然后创建main_amd64.s文件,里面对应main函数的实现:
TEXT ·main(SB), $16-0
MOVQ ·helloworld+0(SB), AX; MOVQ AX, 0(SP)
MOVQ ·helloworld+8(SB), BX; MOVQ BX, 8(SP)
CALL runtime·printstring(SB)
CALL runtime·printnl(SB)
RETTEXT ·main(SB), $16-0 用于定义 main 函数,其中 $16-0 表示 main 函数的 帧大小是16个字节(对应string头部结构体的大小,用于 给 runtime·printstring 函数传递参数), 0 表示 main 函数没有参数和返回 值。 main 函数内部通过调用运行时内部的 runtime·printstring(SB) 函数来 打印字符串。然后调用 runtime·printnl 打印换行符号。
Go语言函数在函数调用时,完全通过栈传递调用参数和返回值。先通过MOVQ指 令,将helloworld对应的字符串头部结构体的16个字节复制到栈指针SP对应的16字 节的空间,然后通过CALL指令调用对应函数。最后使用RET指令表示当前函数返 回。
特殊字符
Go语言函数或方法符号在编译为目标文件后,目标文件中的每个符号均包含对应包 的绝对导入路径。因此目标文件的符号可能非常复杂,比如“path/to/pkg. (*SomeType).SomeMethod”或“go.string."abc"”等名字。目标文件的符号名中不仅 仅包含普通的字母,还可能包含点号、星号、小括弧和双引号等诸多特殊字符。而 Go语言的汇编器是从plan9移植过来的二把刀,并不能处理这些特殊的字符,导致 了用Go汇编语言手工实现Go诸多特性时遇到种种限制。
Go汇编语言同样遵循Go语言少即是多的哲学,它只保留了最基本的特性:定义变 量和全局函数。其中在变量和全局函数等名字中引入特殊的分隔符号支持Go语言等 包体系。为了简化Go汇编器的词法扫描程序的实现,特别引入了Unicode中的中 点 · 和大写的除法 / ,对应的Unicode码点为 U+00B7 和 U+2215 。汇编器编译 后,中点 · 会被替换为ASCII中的点“.”,大写的除法会被替换为ASCII码中的除 法“/”,比如 math/rand·Int 会被替换为 math/rand.Int 。这样可以将中点和浮 点数中的小数点、大写的除法和表达式中的除法符号分开,可以简化汇编程序词法 分析部分的实现。
即使暂时抛开Go汇编语言设计取舍的问题,在不同的操作系统不同等输入法中如何 输入中点 · 和除法 / 两个字符就是一个挑战。这两个字符在 https://golang.org/doc/asm 文档中均有描述,因此直接从该页面复制是最简单可靠 的方式。
如果是macOS系统,则有以下几种方法输入中点 · :在不开输入法时,可直接用 option+shift+9 输入;如果是自带的简体拼音输入法,输入左上角 ~ 键对应 · , 如果是自带的Unicode输入法,则可以输入对应的Unicode码点。其中Unicode输入 法可能是最安全可靠等输入方式。
没有分号
Go汇编语言中分号可以用于分隔同一行内的多个语句。下面是用分号混乱排版的汇 编代码:
TEXT ·main(SB), $16-0; MOVQ ·helloworld+0(SB), AX; MOVQ ·hellowo
rld+8(SB), BX;
MOVQ AX, 0(SP);MOVQ BX, 8(SP);CALL runtime·printstring(SB);
CALL runtime·printnl(SB);
RET;和Go语言一样,也可以省略行尾的分号。当遇到末尾时,汇编器会自动插入分号。 下面是省略分号后的代码:
TEXT ·main(SB), $16-0
MOVQ ·helloworld+0(SB), AX; MOVQ AX, 0(SP)
MOVQ ·helloworld+8(SB), BX; MOVQ BX, 8(SP)
CALL runtime·printstring(SB)
CALL runtime·printnl(SB)
RET和Go语言一样,语句之间多个连续的空白字符和一个空格是等价的。
计算机结构
X86-64体系结构
X86其实是是80X86的简称(后面三个字母),包括Intel 8086、80286、80386以 及80486等指令集合,因此其架构被称为x86架构。x86-64是AMD公司于1999年设 计的x86架构的64位拓展,向后兼容于16位及32位的x86架构。X86-64目前正式名 称为AMD64,也就是Go语言中GOARCH环境变量指定的AMD64。
在使用汇编语言之前必须要了解对应的CPU体系结构。下面是X86/AMD架构图:

左边是内存部分是常见的内存布局。其中text一般对应代码段,用于存储要执行指 令数据,代码段一般是只读的。然后是rodata和data数据段,数据段一般用于存放 全局的数据,其中rodata是只读的数据段。而heap段则用于管理动态的数据,stack 段用于管理每个函数调用时相关的数据。在汇编语言中一般重点关注text代码段和 data数据段,因此Go汇编语言中专门提供了对应TEXT和DATA命令用于定义代码和 数据。
中间是X86提供的寄存器。寄存器是CPU中最重要的资源,每个要处理的内存数据 原则上需要先放到寄存器中才能由CPU处理,同时寄存器中处理完的结果需要再存 入内存。X86中除了状态寄存器FLAGS和指令寄存器IP两个特殊的寄存器外,还有 AX、BX、CX、DX、SI、DI、BP、SP几个通用寄存器。在X86-64中又增加了八个 以R8-R15方式命名的通用寄存器。因为历史的原因R0-R7并不是通用寄存器,它们 只是X87开始引入的MMX指令专有的寄存器。在通用寄存器中BP和SP是两个比较 特殊的寄存器:其中BP用于记录当前函数帧的开始位置,和函数调用相关的指令会 隐式地影响BP的值;SP则对应当前栈指针的位置,和栈相关的指令会隐式地影响 SP的值;而某些调试工具需要BP寄存器才能正常工作。
右边是X86的指令集。CPU是由指令和寄存器组成,指令是每个CPU内置的算法, 指令处理的对象就是全部的寄存器和内存。我们可以将每个指令看作是CPU内置标 准库中提供的一个个函数,然后基于这些函数构造更复杂的程序的过程就是用汇编 语言编程的过程。
Go汇编中的伪寄存器
Go汇编为了简化汇编代码的编写,引入了PC、FP、SP、SB四个伪寄存器。四个 伪寄存器加其它的通用寄存器就是Go汇编语言对CPU的重新抽象,该抽象的结构 也适用于其它非X86类型的体系结构。
四个伪寄存器和X86/AMD64的内存和寄存器的相互关系如下图: 
在AMD64环境,伪PC寄存器其实是IP指令计数器寄存器的别名。伪FP寄存器对应 的是函数的帧指针,一般用来访问函数的参数和返回值。伪SP栈指针对应的是当前 函数栈帧的底部(不包括参数和返回值部分),一般用于定位局部变量。伪SP是一 个比较特殊的寄存器,因为还存在一个同名的SP真寄存器。真SP寄存器对应的是 栈的顶部,一般用于定位调用其它函数的参数和返回值。
当需要区分伪寄存器和真寄存器的时候只需要记住一点:伪寄存器一般需要一个标 识符和偏移量为前缀,如果没有标识符前缀则是真寄存器。比如 (SP) 、 +8(SP) 没有标识符前缀为真SP寄存器,而 a(SP) 、 b+8(SP) 有标识符为前缀表示伪寄存器。
X86-64指令集
很多汇编语言的教程都会强调汇编语言是不可移植的。严格来说汇编语言是在不同 的CPU类型、或不同的操作系统环境、或不同的汇编工具链下是不可移植的,而在 同一种CPU中运行的机器指令是完全一样的。汇编语言这种不可移植性正是其普及 的一个极大的障碍。虽然CPU指令集的差异是导致不好移植的较大因素,但是汇编 语言的相关工具链对此也有不可推卸的责任。而源自Plan9的Go汇编语言对此做了 一定的改进:首先Go汇编语言在相同CPU架构上是完全一致的,也就是屏蔽了操 作系统的差异;同时Go汇编语言将一些基础并且类似的指令抽象为相同名字的伪指 令,从而减少不同CPU架构下汇编代码的差异(寄存器名字和数量的差异是一直存 在的)。
X86是一个极其复杂的系统,有人统计x86-64中指令有将近一千个之多。不仅仅如 此,X86中的很多单个指令的功能也非常强大,比如有论文证明了仅仅一个MOV指 令就可以构成一个图灵完备的系统。以上这是两种极端情况,太多的指令和太少的 指令都不利于汇编程序的编写,但是也从侧面体现了MOV指令的重要性。
通用的基础机器指令大概可以分为数据传输指令、算术运算和逻辑运算指令、控制 流指令和其它指令等几类。
因此我们先看看重要的MOV指令。其中MOV指令可以用于将字面值移动到寄存 器、字面值移到内存、寄存器之间的数据传输、寄存器和内存之间的数据传输。需 要注意的是,MOV传输指令的内存操作数只能有一个,可以通过某个临时寄存器达 到类似目的。最简单的是忽略符号位的数据传输操作,386和AMD64指令一样,不 同的1、2、4和8字节宽度有不同的指令:
Data Type 386/AMD64 Comment
[1]byte MOVB B => Byte
[2]byte MOVW W => Word
[4]byte MOVL L => Long
[8]byte MOVQ Q => QuadwordMOV指令它不仅仅用于在寄存器和内存之间传输数据,而且还可以用于处理数据的 扩展和截断操作。当数据宽度和寄存器的宽度不同又需要处理符号位时,386和 AMD64有各自不同的指令:
Data Type 386 AMD64 Comment
int8 MOVBLSX MOVBQSX sign extend
uint8 MOVBLZX MOVBQZX zero extend
int16 MOVWLSX MOVWQSX sign extend
uint16 MOVWLZX MOVWQZX zero extend比如当需要将一个int64类型的数据转为bool类型时,则需要使用MOVBQZX指令处 理。
基础算术指令有ADD、SUB、MUL、DIV等指令。其中ADD、SUB、MUL、DIV用 于加、减、乘、除运算,最终结果存入目标寄存器。基础的逻辑运算指令有AND、 OR和NOT等几个指令,对应逻辑与、或和取反等几个指令。
名称 解释
ADD 加法
SUB 减法
MUL 乘法
DIV 除法
AND 逻辑与
OR 逻辑或
NOT 逻辑取反其中算术和逻辑指令是顺序编程的基础。通过逻辑比较影响状态寄存器,再结合有 条件跳转指令就可以实现更复杂的分支或循环结构。需要注意的是MUL和DIV等乘 除法指令可能隐含使用了某些寄存器,指令细节请查阅相关手册。
控制流指令有CMP、JMP-if-x、JMP、CALL、RET等指令。CMP指令用于两个操 作数做减法,根据比较结果设置状态寄存器的符号位和零位,可以用于有条件跳转 的跳转条件。JMP-if-x是一组有条件跳转指令,常用的有JL、JLZ、JE、JNE、 JG、JGE等指令,对应小于、小于等于、等于、不等于、大于和大于等于等条件时 跳转。JMP指令则对应无条件跳转,将要跳转的地址设置到IP指令寄存器就实现了 跳转。而CALL和RET指令分别为调用函数和函数返回指令。
名称 解释
JMP 无条件跳转
JMP-if-x 有条件跳转,JL、JLZ、JE、JNE、JG、JGE
CALL 调用函数
RET 函数返回无条件和有条件调整指令是实现分支和循环控制流的基础指令。理论上,我们也可 以通过跳转指令实现函数的调用和返回功能。不过因为目前函数已经是现代计算机 中的一个最基础的抽象,因此大部分的CPU都针对函数的调用和返回提供了专有的 指令和寄存器。
其它比较重要的指令有LEA、PUSH、POP等几个。其中LEA指令将标准参数格式 中的内存地址加载到寄存器(而不是加载内存位置的内容)。PUSH和POP分别是 压栈和出栈指令,通用寄存器中的SP为栈指针,栈是向低地址方向增长的。
名称 解释
LEA 取地址
PUSH 压栈
POP 出栈当需要通过间接索引的方式访问数组或结构体等某些成员对应的内存时,可以用 LEA指令先对目前内存取地址,然后在操作对应内存的数据。而栈指令则可以用于 函数调整自己的栈空间大小。
最后需要说明的是,Go汇编语言可能并没有支持全部的CPU指令。如果遇到没有 支持的CPU指令,可以通过Go汇编语言提供的BYTE命令将真实的CPU指令对应的 机器码填充到对应的位置。完整的X86指令在 https://github.com/golang/arch/blob/master/x86/x86.csv 文件定义。同时Go汇编还正对一些指令定义了别名,具体可以参考这里 https://golang.org/src/cmd/internal/obj/x86/anames.go 。
常量和全局变量
程序中的一切变量的初始值都直接或间接地依赖常量或常量表达式生成。在Go语言中很多变量是默认零值初始化的,但是Go汇编中定义的变量最好还是手工通过常量初始化。有了常量之后,就可以衍生定义全局变量,并使用常量组成的表达式初始化其它各种变量。
常量
Go汇编语言中常量以$美元符号为前缀。常量的类型有整数常量、浮点数常量、字符常量和字符串常量等几种类型。以下是几种类型常量的例子:
$1 // 十进制
$0xf4f8fcff // 十六进制
$1.5 // 浮点数
$'a' // 字符
$"abcd" // 字符串其中整数类型常量默认是十进制格式,也可以用十六进制格式表示整数常量。所有的常量最终都必须和要初始化的变量内存大小匹配。
对于数值型常量,可以通过常量表达式构成新的常量:
$2+2 // 常量表达式
$3&1<<2 // == $4
$(3&1)<<2 // == $4其中常量表达式中运算符的优先级和Go语言保持一致。
Go汇编语言中的常量其实不仅仅只有编译时常量,还包含运行时常量。比如包中全局的变量和全局函数在运行时地址也是固定不变的,这里地址不会改变的包变量和函数的地址也是一种汇编常量。
GLOBL ·NameData(SB),$8
DATA ·NameData(SB)/8,$"gopher"
GLOBL ·Name(SB),$16
DATA ·Name+0(SB)/8,$·NameData(SB)
DATA ·Name+8(SB)/8,$6其中 $·NameData(SB) 也是以$美元符号为前缀,因此也可以将它看作是一个常 量,它对应的是NameData包变量的地址。在汇编指令中,我们也可以通过LEA指 令来获取NameData变量的地址。
全局变量
在Go语言中,变量根据作用域和生命周期有全局变量和局部变量之分。全局变量是 包一级的变量,全局变量一般有着较为固定的内存地址,声明周期跨越整个程序运 行时间。而局部变量一般是函数内定义的的变量,只有在函数被执行的时间才被在 栈上创建,当函数调用完成后将回收(暂时不考虑闭包对局部变量捕获的问题)。
从Go汇编语言角度来看,全局变量和局部变量有着非常大的差异。在Go汇编中全 局变量和全局函数更为相似,都是通过一个人为定义的符号来引用对应的内存,区 别只是内存中存放是数据还是要执行的指令。因为在冯诺伊曼系统结构的计算机中 指令也是数据,而且指令和数据存放在统一编址的内存中。因为指令和数据并没有 本质的差别,因此我们甚至可以像操作数据那样动态生成指令(这是所有JIT技术的)原理。而局部变量则需在了解了汇编函数之后,才能通过SP栈空间来隐式定义。
在Go汇编语言中,内存是通过SB伪寄存器定位。SB是Static base pointer的缩写, 意为静态内存的开始地址。我们可以将SB想象为一个和内容容量有相同大小的字节 数组,所有的静态全局符号通常可以通过SB加一个偏移量定位,而我们定义的符号 其实就是相对于SB内存开始地址偏移量。对于SB伪寄存器,全局变量和全局函数 的符号并没有任何区别。
要定义全局变量,首先要声明一个变量对应的符号,以及变量对应的内存大小。导 出变量符号的语法如下:
GLOBL symbol(SB), widthGLOBL汇编指令用于定义名为symbol的变量,变量对应的内存宽度为width,内存宽度部分必须用常量初始化。下面的代码通过汇编定义一个int32类型的count变量:
GLOBL ·count(SB),$4其中符号 ·count 以中点开头表示是当前包的变量,最终符号名为被展开 为 path/to/pkg.count 。count变量的大小是4个字节,常量必须以$美元符号开 头。内存的宽度必须是2的指数倍,编译器最终会保证变量的真实地址对齐到机器 字倍数。需要注意的是,在Go汇编中我们无法为count变量指定具体的类型。在汇 编中定义全局变量时,我们只关心变量的名字和内存大小,变量最终的类型只能在 Go语言中声明
变量定义之后,我们可以通过DATA汇编指令指定对应内存中的数据,语法如下:
DATA symbol+offset(SB)/width, value具体的含义是从symbol+offset偏移量开始,width宽度的内存,用value常量对应的 值初始化。DATA初始化内存时,width必须是1、2、4、8几个宽度之一,因为再大 的内存无法一次性用一个uint64大小的值表示。
对于int32类型的count变量来说,我们既可以逐个字节初始化,也可以一次性初始化:
DATA ·count+0(SB)/1,$1
DATA ·count+1(SB)/1,$2
DATA ·count+2(SB)/1,$3
DATA ·count+3(SB)/1,$4
// or
DATA ·count+0(SB)/4,$0x04030201因为X86处理器是小端序,因此用十六进制0x04030201初始化全部的4个字节,和 用1、2、3、4逐个初始化4个字节是一样的效果。
最后还需要在Go语言中声明对应的变量(和C语言头文件声明变量的作用类似), 这样垃圾回收器会根据变量的类型来管理其中的指针相关的内存数据。
数组类型
汇编中数组也是一种非常简单的类型。Go语言中数组是一种有着扁平内存结构的基 础类型。因此 [2]byte 类型和 [1]uint16 类型有着相同的内存结构。只有当数 组和结构体结合之后情况才会变的稍微复杂。
下面我们尝试用汇编定义一个 [2]int 类型的数组变量num:
var num [2]int然后在汇编中定义一个对应16字节大小的变量,并用零值进行初始化:
GLOBL ·num(SB),$16
DATA ·num+0(SB)/8,$0
DATA ·num+8(SB)/8,$0
汇编代码中并不需要NOPTR标志,因为Go编译器会从Go语言语句声明的 [2]int 类型中推导出该变量内部没有指针数据。
bool型变量
Go汇编语言定义变量无法指定类型信息,因此需要先通过Go语言声明变量的类 型。以下是在Go语言中声明的几个bool类型变量:
var (
boolValue bool
trueValue bool
falseValue bool
)在Go语言中声明的变量不能含有初始化语句。然后下面是amd64环境的汇编定义:
GLOBL ·boolValue(SB),$1 // 未初始化
GLOBL ·trueValue(SB),$1 // var trueValue = true
DATA ·trueValue(SB)/1,$1 // 非 0 均为 true
GLOBL ·falseValue(SB),$1 // var falseValue = true
DATA ·falseValue(SB)/1,$0bool类型的内存大小为1个字节。并且汇编中定义的变量需要手工指定初始化值, 否则将可能导致产生未初始化的变量。当需要将1个字节的bool类型变量加载到8字 节的寄存器时,需要使用MOVBQZX指令将不足的高位用0填充。
int型变量
所有的整数类型均有类似的定义的方式,比较大的差异是整数类型的内存大小和整数是否是有符号。下面是声明的int32和uint32类型变量:
var int32Value int32
var uint32Value uint32在Go语言中声明的变量不能含有初始化语句。然后下面是amd64环境的汇编定义:
GLOBL ·int32Value(SB),$4
DATA ·int32Value+0(SB)/1,$0x01 // 第0字节
DATA ·int32Value+1(SB)/1,$0x02 // 第1字节
DATA ·int32Value+2(SB)/2,$0x03 // 第3-4字节
GLOBL ·uint32Value(SB),$4
DATA ·uint32Value(SB)/4,$0x01020304 // 第1-4字节汇编定义变量时初始化数据并不区分整数是否有符号。只有CPU指令处理该寄存器数据时,才会根据指令的类型来取分数据的类型或者是否带有符号位。
float型变量
Go汇编语言通常无法区分变量是否是浮点数类型,与之相关的浮点数机器指令会将变量当作浮点数处理。Go语言的浮点数遵循IEEE754标准,有float32单精度浮点数和float64双精度浮点数之分。
IEEE754标准中,最高位1bit为符号位,然后是指数位(指数为采用移码格式表 示),然后是有效数部分(其中小数点左边的一个bit位被省略)。

IEEE754浮点数还有一些奇妙的特性:比如有正负两个0;除了无穷大和无穷小Inf 还有非数NaN;同时如果两个浮点数有序那么对应的有符号整数也是有序的(反之 则不一定成立,因为浮点数中存在的非数是不可排序的)。浮点数是程序中最难琢 磨的角落,因为程序中很多手写的浮点数字面值常量根本无法精确表达,浮点数计 算涉及到的误差舍入方式可能也的随机的。
下面是在Go语言中声明两个浮点数(如果没有在汇编中定义变量,那么声明的同时也会定义变量)。
var float32Value float32
var float64Value float64然后在汇编中定义并初始化上面声明的两个浮点数:
GLOBL ·float32Value(SB),$4
DATA ·float32Value+0(SB)/4,$1.5 // var float32Value = 1.5
GLOBL ·float64Value(SB),$8
DATA ·float64Value(SB)/8,$0x01020304 // bit 方式初始化如果要通过整数指令处理浮点数的 加减法必须根据浮点数的运算规则进行:先对齐小数点,然后进行整数加减法,最 后再对结果进行归一化并处理精度舍入问题。不过在目前的主流CPU中,都提针对 浮点数提供了专有的计算指令。
string类型变量
从Go汇编语言角度看,字符串只是一种结构体。string的头结构定义如下:
type reflect.StringHeader struct {
Data uintptr
Len int
}在amd64环境中StringHeader有16个字节大小,因此我们先在Go代码声明字符串变 量,然后在汇编中定义一个16字节大小的变量:
var helloworld stringGLOBL ·helloworld(SB),$16同时我们可以为字符串准备真正的数据。在下面的汇编代码中,我们定义了一个 text当前文件内的私有变量(以 <> 为后缀名),内容为“Hello World!”:
GLOBL text<>(SB),NOPTR,$16
DATA text<>+0(SB)/8,$"Hello Wo"
DATA text<>+8(SB)/8,$"rld!"虽然 text<> 私有变量表示的字符串只有12个字符长度,但是我们依然需要将变量 的长度扩展为2的指数倍数,这里也就是16个字节的长度。其中 NOPTR 表 示 text<> 不包含指针数据。
然后使用text私有变量对应的内存地址对应的常量来初始化字符串头结构体中的 Data部分,并且手工指定Len部分为字符串的长度:
DATA ·helloworld+0(SB)/8,$text<>(SB) // StringHeader.Data
DATA ·helloworld+8(SB)/8,$12 // StringHeader.Len需要注意的是,字符串是只读类型,要避免在汇编中直接修改字符串底层数据的内容。
slice类型变量
slice变量和string变量相似,只不过是对应的是切片头结构体而已。切片头的结构如下:
type reflect.SliceHeader struct {
Data uintptr
Len int
Cap int
}对比可以发现,切片的头的前2个成员字符串是一样的。因此我们可以在前面字符串变量的基础上,再扩展一个Cap成员就成了切片类型了:
var helloworld []byteGLOBL ·helloworld(SB),$24 // var helloworld []byte("H
ello World!")
DATA ·helloworld+0(SB)/8,$text<>(SB) // StringHeader.Data
DATA ·helloworld+8(SB)/8,$12 // StringHeader.Len
DATA ·helloworld+16(SB)/8,$16 // StringHeader.Cap
GLOBL text<>(SB),$16
DATA text<>+0(SB)/8,$"Hello Wo" // ...string data...
DATA text<>+8(SB)/8,$"rld!" // ...string data...因为切片和字符串的相容性,我们可以将切片头的前16个字节临时作为字符串使用,这样可以省去不必要的转换。
map/channel类型变量
map/channel等类型并没有公开的内部结构,它们只是一种未知类型的指针,无法直接初始化。在汇编代码中我们只能为类似变量定义并进行0值初始化:
var m map[string]int
var ch chan intGLOBL ·m(SB),$8 // var m map[string]int
DATA ·m+0(SB)/8,$0
GLOBL ·ch(SB),$8 // var ch chan int
DATA ·ch+0(SB)/8,$0其实在runtime包中为汇编提供了一些辅助函数。比如在汇编中可以通过runtime.makemap和runtime.makechan内部函数来创建map和chan变量。辅助函数的签名如下:
func makemap(mapType *byte, hint int, mapbuf *any) (hmap map[any
]any)
func makechan(chanType *byte, size int) (hchan chan any)需要注意的是,makemap是一种范型函数,可以创建不同类型的map,map的具体类型是通过mapType参数指定。
变量的内存布局
在Go汇编语言中变量是没有类型的。因此在Go语言中有着不 同类型的变量,底层可能对应的是相同的内存结构。深刻理解每个变量的内存布局是汇编编程时的必备条件。
首先查看前面已经见过的 [2]int 类型数组的内存布局: 
变量在data段分配空间,数组的元素地址依次从低向高排列。
然后再查看下标准库图像包中 image.Point 结构体类型变量的内存布局:

变量也时在data段分配空间,变量结构体成员的地址也是依次从低向高排列。
因此 [2]int 和 image.Point 类型底层有着近似相同的内存布局。
标识符规则和特殊标志
Go语言的标识符可以由绝对的包路径加标识符本身定位,因此不同包中的标识符即 使同名也不会有问题。Go汇编是通过特殊的符号来表示斜杠和点符号,因为这样可 以简化汇编器词法扫描部分代码的编写,只要通过字符串替换就可以了。
下面是汇编中常见的几种标识符的使用方式(通常也适用于函数标识符):
GLOBL ·pkg_name1(SB),$1
GLOBL main·pkg_name2(SB),$1
GLOBL my/pkg·pkg_name(SB),$1此外,Go汇编中可以定义仅当前文件可以访问的私有标识符(类似C语言中文件内static修饰的变量),以 <> 为后缀名:
GLOBL file_private<>(SB),$1这样可以减少私有标识符对其它文件内标识符命名的干扰。
此外,Go汇编语言还在"textflag.h"文件定义了一些标志。其中用于变量的标志有DUPOK、RODATA和NOPTR几个。DUPOK表示该变量对应的标识符可能有多个,在链接时只选择其中一个即可(一般用于合并相同的常量字符串,减少重复数据占用的空间)。RODATA标志表示将变量定义在只读内存段,因此后续任何对此变量的修改操作将导致异常(recover也无法捕获)。NOPTR则表示此变量的内部不含指针数据,让垃圾回收器忽略对该变量的扫描。如果变量已经在Go代码中声明过的话,Go编译器会自动分析出该变量是否包含指针,这种时候可以不用手写NOPTR标志。
比如下面的例子是通过汇编来定义一个只读的int类型的变量:
var const_id int // readonly#include "textflag.h"
GLOBL ·const_id(SB),NOPTR|RODATA,$8
DATA ·const_id+0(SB)/8,$9527我们使用#include语句包含定义标志的"textflag.h"头文件(和C语言中预处理相同)。然后GLOBL汇编命令在定义变量时,给变量增加了NOPTR和RODATA两个标志(多个标志之间采用竖杠分割),表示变量中没有指针数据同时定义在只读数据段。
变量一般也叫可取地址的值,但是const_id虽然可以取地址,但是确实不能修改。不能修改的限制并不是由编译器提供,而是因为对该变量的修改会导致对只读内存段进行写,从而导致异常。
真实的环境中并不推荐通过汇编定义变量——因为用Go语言定义变量更加简单和安全。在Go语言中定义变量,编译器可以帮助我们计算好变量的大小,生成变量的初始值,同时也包含了足够的类型信息。汇编语言的优势是挖掘机器的特性和性能,用汇编定义变量则 无法发挥这些优势。因此在理解了汇编定义变量的用法后,建议大家谨慎使用。
函数
因为Go汇编语言中,可以也建议通过Go语言来定义全局变量,那 么剩下的也就是函数了。只有掌握了汇编函数的基本用法,才能真正算是Go汇编语 言入门。
基本语法
函数标识符通过TEXT汇编指令定义,表示该行开始的指令定义在TEXT内存段。 TEXT语句后的指令一般对应函数的实现,但是对于TEXT指令本身来说并不关心后 面是否有指令。因此TEXT和LABEL定义的符号是类似的,区别只是LABEL是用于 跳转标号,但是本质上他们都是通过标识符映射一个内存地址。 函数的定义的语法如下:
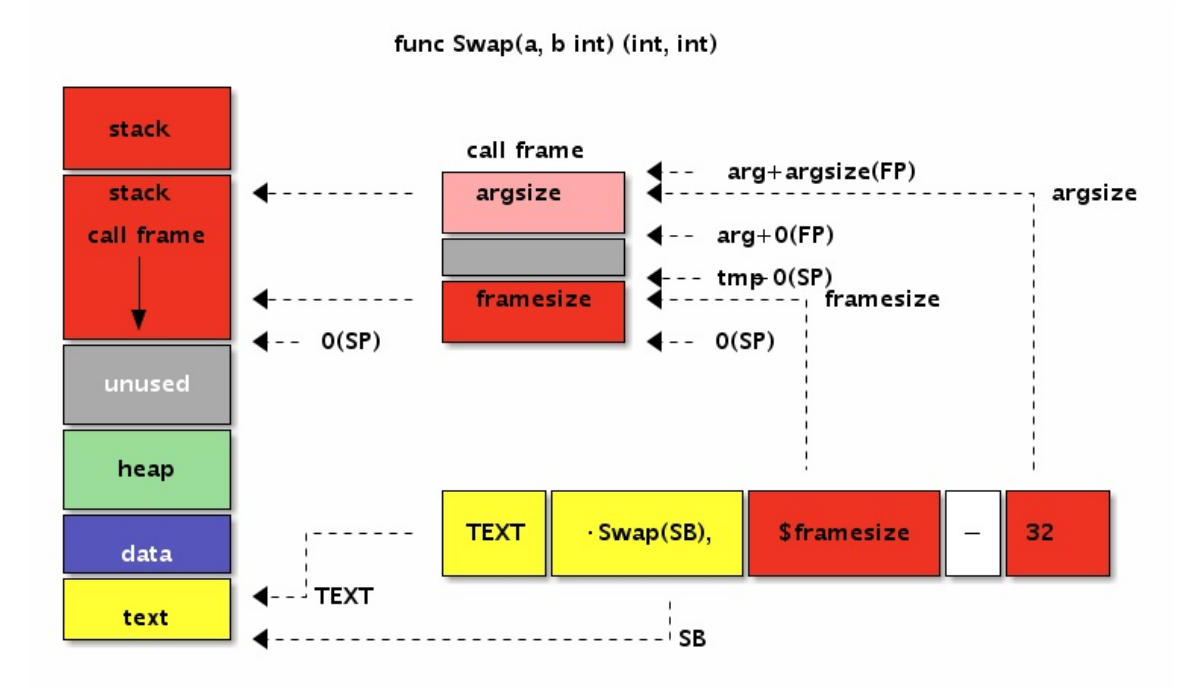
TEXT symbol(SB), [flags,] $framesize[-argsize]函数的定义部分由5个部分组成:TEXT指令、函数名、可选的flags标志、函数帧大小和可选的函数参数大小。
其中TEXT用于定义函数符号,函数名中当前包的路径可以省略。函数的名字后面 是 (SB) ,表示是函数名符号相对于SB伪寄存器的偏移量,二者组合在一起最终 是绝对地址。作为全局的标识符的全局变量和全局函数的名字一般都是基于SB伪寄 存器的相对地址。标志部分用于指示函数的一些特殊行为,标志 在 textlags.h 文件中定义,常见的 NOSPLIT 主要用于指示叶子函数不进行栈分 裂。framesize部分表示函数的局部变量需要多少栈空间,其中包含调用其它函数时 准备调用参数的隐式栈空间。最后是可以省略的参数大小,之所以可以省略是因为 编译器可以从Go语言的函数声明中推导出函数参数的大小。
我们首先从一个简单的Swap函数开始。Swap函数用于交互输入的两个参数的顺 序,然后通过返回值返回交换了顺序的结果。如果用Go语言中声明Swap函数,大 概这样的:
package main
//go:nosplit
func Swap(a, b int) (int, int)下面是main包中Swap函数在汇编中两种定义方式:
// func Swap(a, b int) (int, int)
TEXT ·Swap(SB), NOSPLIT, $0-32
// func Swap(a, b int) (int, int)
TEXT ·Swap(SB), NOSPLIT, $0
第一种是最完整的写法:函数名部分包含了当前包的路径,同时指明了函数的参数 大小为32个字节(对应参数和返回值的4个int类型)。第二种写法则比较简洁,省 略了当前包的路径和参数的大小。如果有NOSPLIT标注,会禁止汇编器为汇编函数 插入栈分裂的代码。NOSPLIT对应Go语言中的 //go:nosplit 注释。
目前可能遇到的函数标志有NOSPLIT、WRAPPER和NEEDCTXT几个。其中 NOSPLIT不会生成或包含栈分裂代码,这一般用于没有任何其它函数调用的叶子函 数,这样可以适当提高性能。WRAPPER标志则表示这个是一个包装函数,在 panic或runtime.caller等某些处理函数帧的地方不会增加函数帧计数。最后的 NEEDCTXT表示需要一个上下文参数,一般用于闭包函数。
需要注意的是函数也没有类型,上面定义的Swap函数签名可以下面任意一种格式:
func Swap(a, b, c int) int
func Swap(a, b, c, d int)
func Swap() (a, b, c, d int)
func Swap() (a []int, d int)
// ...对于汇编函数来说,只要是函数的名字和参数大小一致就可以是相同的函数了。而且在Go汇编语言中,输入参数和返回值参数是没有任何的区别的。
函数参数和返回值
对于函数来说,最重要的是函数对外提供的API约定,包含函数的名称、参数和返回值。当这些都确定之后,如何精确计算参数和返回值的大小是第一个需要解决的问题。
比如有一个Swap函数的签名如下:
func Swap(a, b int) (ret0, ret1 int)对于这个函数,我们可以轻易看出它需要4个int类型的空间,参数和返回值的大小也就是32个字节:
TEXT ·Swap(SB), $0-32那么如何在汇编中引用这4个参数呢?为此Go汇编中引入了一个FP伪寄存器,表示函数当前帧的地址,也就是第一个参数的地址。因此我们以通过 +0(FP) 、 +8(FP) 、 +16(FP) 和 +24(FP) 来分别引用a、b、ret0和ret1四个参数。
但是在汇编代码中,我们并不能直接以 +0(FP) 的方式来使用参数。为了编写易于维护的汇编代码,Go汇编语言要求,任何通过FP伪寄存器访问的变量必和一个临时标识符前缀组合后才能有效,一般使用参数对应的变量名作为前缀。
下面的代码演示了如何在汇编函数中使用参数和返回值:
TEXT ·Swap(SB), $0
MOVQ a+0(FP), AX // AX = a
MOVQ b+8(FP), BX // BX = b
MOVQ BX, ret0+16(FP) // ret0 = BX
MOVQ AX, ret1+24(FP) // ret1 = AX
RET从代码可以看出a、b、ret0和ret1的内存地址是依次递增的,FP伪寄存器是第一个变量的开始地址。
参数和返回值的内存布局
如果是参数和返回值类型比较复杂的情况该如何处理呢?下面我们再尝试一个更复杂的函数参数和返回值的计算。比如有以下一个函数:
func Foo(a bool, b int16) (c []byte)函数的参数有不同的类型,而且返回值中含有更复杂的切片类型。我们该如何计算每个参数的位置和总的大小呢?
其实函数参数和返回值的大小以及对齐问题和结构体的大小和成员对齐问题是一致的,函数的第一个参数和第一个返回值会分别进行一次地址对齐。我们可以用诡代思路将全部的参数和返回值以同样的顺序分别放到两个结构体中,将FP伪寄存器作为唯一的一个指针参数,而每个成员的地址也就是对应原来参数的地址。
用这样的策略可以很容易计算前面的Foo函数的参数和返回值的地址和总大小。为了便于描述我们定义一个 Foo_args_and_returns 临时结构体类型用于诡代原始的参数和返回值:
type Foo_args struct {
a bool
b int16
c []byte
}
type Foo_returns struct {
c []byte
}然后将Foo原来的参数替换为结构体形式,并且只保留唯一的FP作为参数:
func Foo(FP *SomeFunc_args, FP_ret *SomeFunc_returns) {
// a = FP + offsetof(&args.a)
_ = unsafe.Offsetof(FP.a) + uintptr(FP) // a
// b = FP + offsetof(&args.b)
// argsize = sizeof(args)
argsize = unsafe.Offsetof(FP)
// c = FP + argsize + offsetof(&return.c)
_ = uintptr(FP) + argsize + unsafe.Offsetof(FP_ret.c)
// framesize = sizeof(args) + sizeof(returns)
_ = unsafe.Offsetof(FP) + unsafe.Offsetof(FP_ret)
return
}代码完全和Foo函数参数的方式类似。唯一的差异是每个函数的偏移量,通 过 unsafe.Offsetof 函数自动计算生成。因为Go结构体中的每个成员已经满足 了对齐要求,因此采用通用方式得到每个参数的偏移量也是满足对齐要求的。序言 注意的是第一个返回值地址需要重新对齐机器字大小的倍数。
Foo函数的参数和返回值的大小和内存布局:
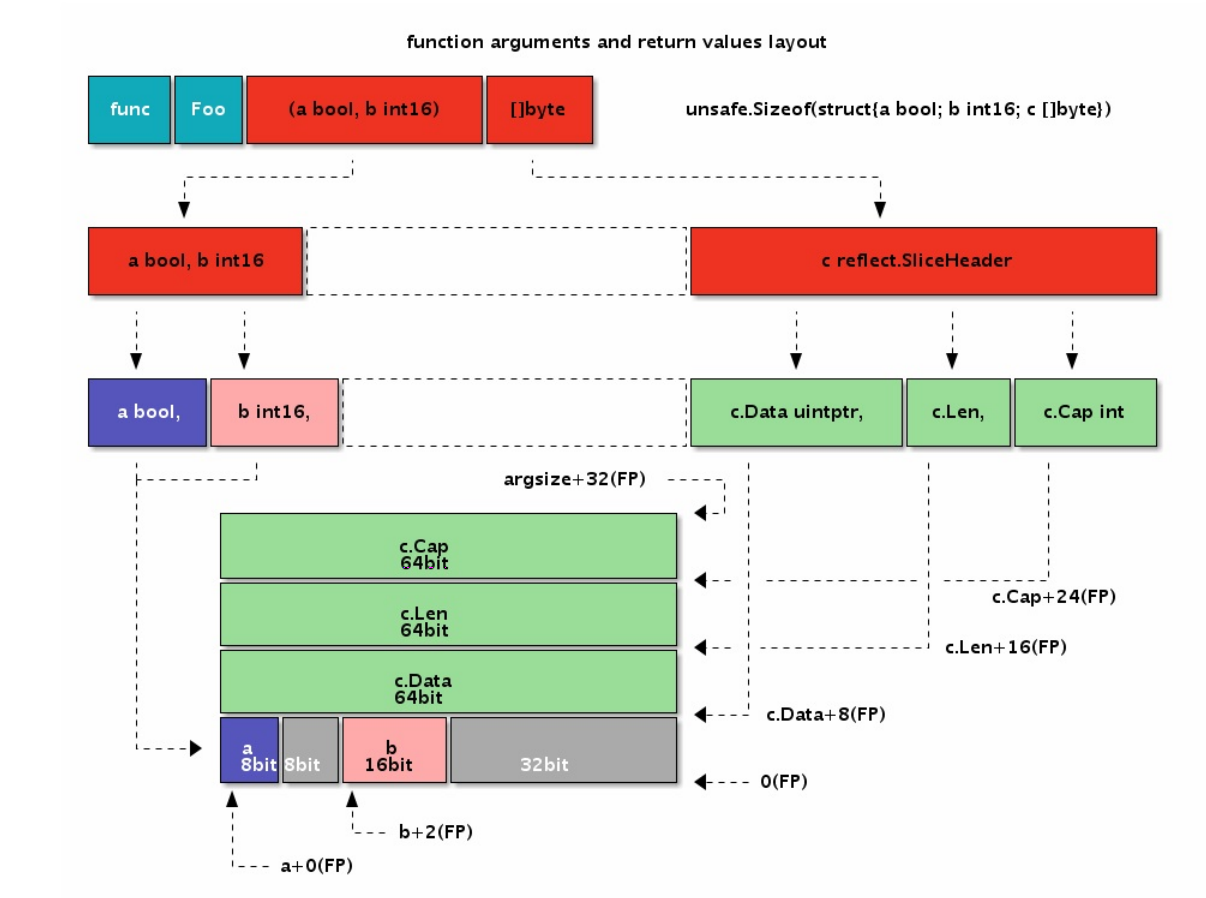
下面的代码演示了Foo汇编函数参数和返回值的定位:
TEXT ·Foo(SB), $0
MOVEQ a+0(FP), AX // a
MOVEQ b+2(FP), BX // b
MOVEQ c_dat+8*1(FP), CX // c.Data
MOVEQ c_len+8*2(FP), DX // c.Len
MOVEQ c_cap+8*3(FP), DI // c.Cap
RET其中a和b参数之间出现了一个字节的空洞,b和c之间出现了4个字节的空洞。出现空洞的原因是要保证每个参数变量地址都要对齐到相应的倍数。
函数中的局部变量
从Go语言函数角度讲,局部变量是函数内明确定义的变量,同时也包含函数的参数 和返回值变量。但是从Go汇编角度看,局部变量是指函数运行时,在当前函数栈帧 所对应的内存内的变量,不包含函数的参数和返回值(因为访问方式有差异)。函 数栈帧的空间主要由函数参数和返回值、局部变量和被调用其它函数的参数和返回 值空间组成。为了便于理解,我们可以将汇编函数的局部变量类比为Go语言函数中 显式定义的变量,不包含参数和返回值部分。
为了便于访问局部变量,Go汇编语言引入了伪SP寄存器,对应当前栈帧的底部。 因为在当前栈帧时栈的底部是固定不变的,因此局部变量的相对于伪SP的偏移量也 就是固定的,这可以简化局部变量的维护工作。SP真伪寄存器的区分只有一个原 则:如果使用SP时有一个临时标识符前缀就是伪SP,否则就是真SP寄存器。比 如 a(SP) 和 b+8(SP) 有a和b临时前缀,这里都是伪SP,而前缀部分一般用于表 示局部变量的名字。而 (SP) 和 +8(SP) 没有临时标识符作为前缀,它们都是真 SP寄存器。
在X86平台,函数的调用栈是从高地址向低地址增长的,因此伪SP寄存器对应栈帧 的底部其实是对应更大的地址。当前栈的顶部对应真实存在的SP寄存器,对应当前 函数栈帧的栈顶,对应更小的地址。如果整个内存用Memory数组表示,那 么 Memory[ 0(SP):end-0(SP) ] 就是对应当前栈帧的切片,其中开始位置是真SP 寄存器,结尾部分是伪SP寄存器。真SP寄存器一般用于表示调用其它函数时的参 数和返回值,真SP寄存器对应内存较低的地址,所以被访问变量的偏移量是正数; 而伪SP寄存器对应高地址,对应的局部变量的偏移量都是负数。
为了便于对比,我们将前面Foo函数的参数和返回值变量改成局部变量:
func Foo() {
var c []byte
var b int16
var a bool
}然后通过汇编语言重新实现Foo函数,并通过伪SP来定位局部变量
TEXT ·Foo(SB), $32-0
MOVQ a-32(SP), AX // a
MOVQ b-30(SP), BX // b
MOVQ c_data-24(SP), CX // c.Data
MOVQ c_len-16(SP), DX // c.Len
MOVQ c_cap-8(SP), DI // c.Cap
RETFoo函数有3个局部变量,但是没有调用其它的函数,因为对齐和填充的问题导致函 数的栈帧大小为32个字节。因为Foo函数没有参数和返回值,因此参数和返回值大 小为0个字节,当然这个部分可以省略不写。而局部变量中先定义的变量c离伪SP寄 存器对应的地址最近,最后定义的变量a离伪SP寄存器最远。有两个因素导致出现 这种逆序的结果:一个从Go语言函数角度理解,先定义的c变量地址要比后定义的 变量的地址更大;另一个是伪SP寄存器对应栈帧的底部,而X86中栈是从高向低生 长的,所以最先定义有着更大地址的c变量离栈的底部伪SP更近。
我们同样可以通过结构体来模拟局部变量的布局:
func Foo() {
var local [1]struct{
a bool
b int16
c []byte
}
var SP = &local[1];
_ = -(unsafe.Sizeof(local)-unsafe.Offsetof(local.a)) + uintp
tr(&SP) // a
_ = -(unsafe.Sizeof(local)-unsafe.Offsetof(local.b)) + uintp
tr(&SP) // b
_ = -(unsafe.Sizeof(local)-unsafe.Offsetof(local.c)) + uintp
tr(&SP) // c
}我们将之前的三个局部变量挪到一个结构体中。然后构造一个SP变量对应伪SP寄 存器,对应局部变量结构体的顶部。然后根据局部变量总大小和每个变量对应成员 的偏移量计算相对于伪SP的距离,最终偏移量是一个负数。
通过这种方式可以处理复杂的局部变量的偏移,同时也能保证每个变量地址的对齐 要求。当然,除了地址对齐外,局部变量的布局并没有顺序要求。对于汇编比较熟 悉可以根据自己的习惯组织变量的布局。 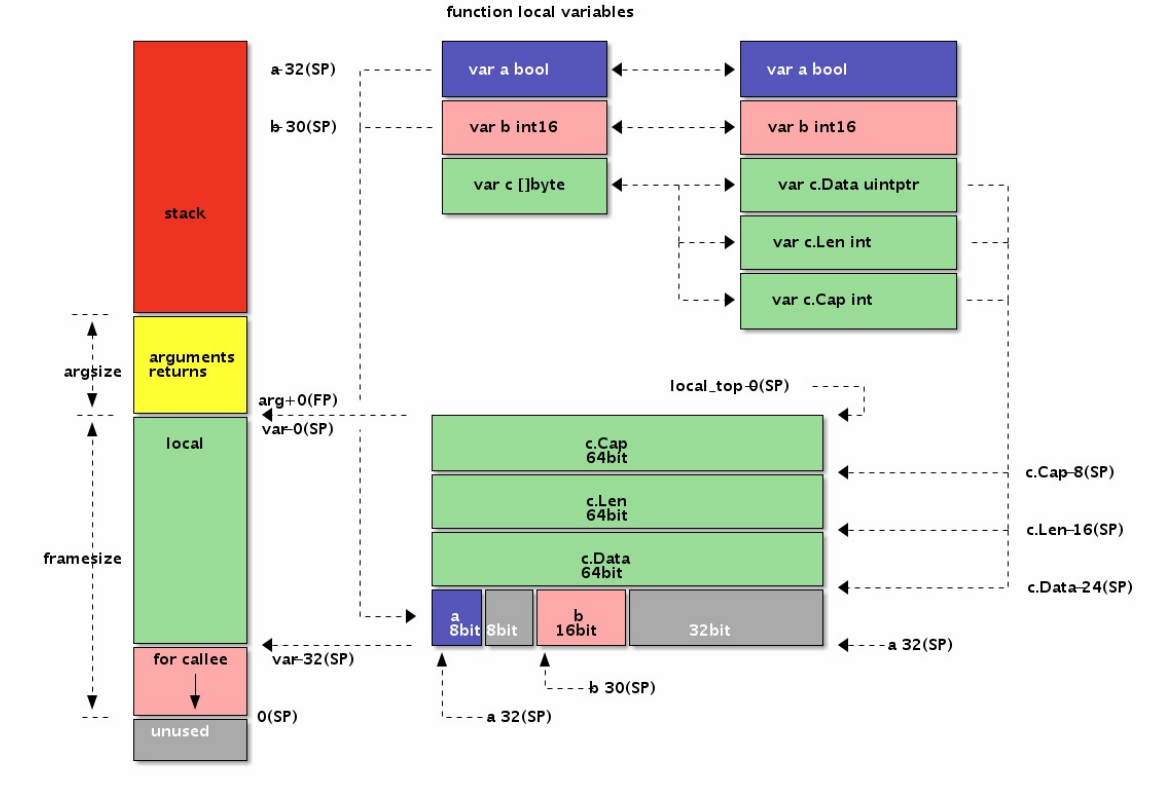
从图中可以看出Foo函数局部变量和前一个例子中参数和返回值的内存布局是完全 一样的,这也是我们故意设计的结果。但是参数和返回值是通过伪FP寄存器定位 的,FP寄存器对应第一个参数的开始地址(第一个参数地址较低),因此每个变量 的偏移量是正数。而局部变量是通过伪SP寄存器定位的,而伪SP寄存器对应的是 第一个局部变量的结束地址(第一个局部变量地址较大),因此每个局部变量的偏 移量都是负数。
调用其它函数
常见的用Go汇编实现的函数都是叶子函数,也就是被其它函数调用的函数,但是很少调用其它函数。这主要是因为叶子函数比较简单,可以简化汇编函数的编写;同时一般性能或特性的瓶颈也处于叶子函数。但是能够调用其它函数和能够被其它函数调用同样重要,否则Go汇编就不是一个完整的汇编语言。
汇编函数的参数是从哪里来的?答案同样明显,被调用函数的参数 是由调用方准备的:调用方在栈上设置好空间和数据后调用函数,被调用方在返回 前将返回值放在对应的位置,函数通过RET指令返回调用方函数之后,调用方再从 返回值对应的栈内存位置取出结果。Go语言函数的调用参数和返回值均是通过栈传 输的,这样做的优点是函数调用栈比较清晰,缺点是函数调用有一定的性能损耗 (Go编译器是通过函数内联来缓解这个问题的影响)。
为了便于展示,我们先使用Go语言来构造三个逐级调用的函数:
func main() {
printsum(1, 2)
}
func printsum(a, b int) {
var ret = sum(a, b)
println(ret)
}
func sum(a, b int) int {
return a+b
}其中main函数通过字面值常量直接调用printsum函数,printsum函数输出两个整数 的和。而printsum函数内部又通过调用sum函数计算两个数的和,并最终调用打印 函数进行输出。因为printsum既是被调用函数又是调用函数,所以它是我们要重点 分析的函数。

为了便于理解,我们对真实的内存布局进行了简化。要记住的是调用函数时,被调 用函数的参数和返回值内存空间都必须由调用者提供。因此函数的局部变量和为调 用其它函数准备的栈空间总和就确定了函数帧的大小。调用其它函数前调用方要选 择保存相关寄存器到栈中,并在调用函数返回后选择要恢复的寄存器进行保存。最 终通过CALL指令调用函数的过程和调用我们熟悉的调用println函数输出的过程类 似。
Go语言中函数调用是一个复杂的问题,因为Go函数不仅仅要了解函数调用参数的 布局,还会涉及到栈的跳转,栈上局部变量的生命周期管理。
宏函数
宏函数并不是Go汇编语言所定义,而是Go汇编引入的预处理特性自带的特性。
在C语言中我们可以通过带参数的宏定义一个交换2个数的宏函数:
#define SWAP(x, y) do{ int t = x; x = y; y = t; }while(0)我们可以用类似的方式定义一个交换两个寄存器的宏:
#define SWAP(x, y, t) MOVQ x, t; MOVQ y, x; MOVQ t, y因为汇编语言中无法定义临时变量,我们增加一个参数用于临时寄存器。下面是通 过SWAP宏函数交换AX和BX寄存器的值,然后返回结果:
// func Swap(a, b int) (int, int)
TEXT ·Swap(SB), $0-32
MOVQ a+0(FP), AX // AX = a
MOVQ b+8(FP), BX // BX = b
SWAP(AX, BX, CX) // AX, BX = b, a
MOVQ AX, ret0+16(FP) // return
MOVQ BX, ret1+24(FP) //
RET因为预处理器可以通过条件编译针对不同的平台定义宏的实现,这样可以简化平台带来的差异。
控制流
程序主要有顺序、分支和循环几种执行流程。
顺序执行
顺序执行是我们比较熟悉的工作模式,类似俗称流水账编程。所有不含分支、循环 和goto语句,并且没有递归调用的Go函数一般都是顺序执行的。
func main() {
var a = 10
println(a)
var b = (a+a)*a
println(b)
}我们尝试用Go汇编的思维改写上述函数。因为X86指令中一般只有2个操作数,因 此在用汇编改写时要求出现的变量表达式中最多只能有一个运算符。同时对于一些 函数调用,也需要用汇编中可以调用的函数来改写。
第一步改写依然是使用Go语言,只不过是用汇编的思维改写:
func main() {
var a, b int
a = 10
runtime.printint(a)
runtime.printnl()
b = a
b += b
b *= a
runtime.printint(b)
runtime.printnl()
}首选模仿C语言的处理方式在函数入口处声明全部的局部变量。然后根据MOV、 ADD、MUL等指令的风格,将之前的变量表达式展开为用 = 、 += 和 *= 几种运 算表达的多个指令。最后用runtime包内部的printint和printnl函数代替之前的println 函数输出结果。
经过用汇编的思维改写过后,上述的Go函数虽然看着繁琐了一点,但是还是比较容 易理解的。下面我们进一步尝试将改写后的函数继续转译为汇编函数:
TEXT ·main(SB), $24-0
MOVQ $0, a-8*2(SP) // a = 0
MOVQ $0, b-8*1(SP) // b = 0
// 将新的值写入a对应内存
MOVQ $10, AX // AX = 10
MOVQ AX, a-8*2(SP) // a = AX
// 以a为参数调用函数
MOVQ AX, 0(SP)
CALL runtime·printint(SB)
CALL runtime·printnl(SB)
// 函数调用后, AX/BX 寄存器可能被污染, 需要重新加载
MOVQ a-8*2(SP), AX // AX = a
MOVQ b-8*1(SP), BX // BX = b
// 计算b值, 并写入内存
MOVQ AX, BX // BX = AX // b = a
ADDQ BX, BX // BX += BX // b += a
IMULQ AX, BX // BX *= AX // b *= a
MOVQ BX, b-8*1(SP) // b = BX
// 以b为参数调用函数
MOVQ BX, 0(SP)
CALL runtime·printint(SB)
CALL runtime·printnl(SB)
RET汇编实现main函数的第一步是要计算函数栈帧的大小。因为函数内有a、b两个int类 型变量,同时调用的runtime·printint函数参数是一个int类型并且没有返回值,因此 main函数的栈帧是3个int类型组成的24个字节的栈内存空间。
在函数的开始处先将变量初始化为0值,其中 a-82(SP) 对应a变量、 a- 81(SP) 对应b变量(因为a变量先定义,因此a变量的地址更小)。
然后给a变量分配一个AX寄存器,并且通过AX寄存器将a变量对应的内存设置为 10,AX也是10。为了输出a变量,需要将AX寄存器的值放到 0(SP) 位置,这个位 置的变量将在调用runtime·printint函数时作为它的参数被打印。因为我们之前已经 将AX的值保存到a变量内存中了,因此在调用函数前并不需要再进行寄存器的备份 工作。
在调用函数返回之后,全部的寄存器将被视为可能被调用的函数修改,因此我们需 要从a、b对应的内存中重新恢复寄存器AX和BX。然后参考上面Go语言中b变量的 计算方式更新BX对应的值,计算完成后同样将BX的值写入到b对应的内存。
需要说明的是,上面的代码中 IMULQ AX, BX 使用了 IMULQ 指令来计算乘法。没 有使用 MULQ 指令的原因是 MULQ 指令默认使用 AX 保存结果。
最后以b变量作为参数再次调用runtime·printint函数进行输出工作。所有的寄存器同 样可能被污染,不过main函数马上就返回了,因此不再需要恢复AX、BX等寄存器 了。
重新分析汇编改写后的整个函数会发现里面很多的冗余代码。我们并不需要a、b两 个临时变量分配两个内存空间,而且也不需要在每个寄存器变化之后都要写入内 存。下面是经过优化的汇编函数:
TEXT ·main(SB), $16-0
// var temp int
// 将新的值写入a对应内存
MOVQ $10, AX // AX = 10
MOVQ AX, temp-8(SP) // temp = AX
// 以a为参数调用函数
CALL runtime·printint(SB)
CALL runtime·printnl(SB)
// 函数调用后, AX 可能被污染, 需要重新加载
MOVQ temp-8*1(SP), AX // AX = temp
// 计算b值, 不需要写入内存
MOVQ AX, BX // BX = AX // b = a
ADDQ BX, BX // BX += BX // b += a
IMULQ AX, BX // BX *= AX // b *= a
// ...首先是将main函数的栈帧大小从24字节减少到16字节。唯一需要保存的是a变量的 值,因此在调用runtime·printint函数输出时全部的寄存器都可能被污染,我们无法 通过寄存器备份a变量的值,只有在栈内存中的值才是安全的。然后在BX寄存器并 不需要保存到内存。其它部分的代码基本保持不变
if/goto跳转
Go语言刚刚开源的时候并没有goto语句,后来Go语言虽然增加了goto语句,但是 并不推荐在编程中使用。有一个和cgo类似的原则:如果可以不使用goto语句,那 么就不要使用goto语句。Go语言中的goto语句是有严格限制的:它无法跨越代码 块,并且在被跨越的代码中不能含有变量定义的语句。虽然Go语言不推荐goto语 句,但是goto确实每个汇编语言码农的最爱。因为goto近似等价于汇编语言中的无 条件跳转指令JMP,配合if条件goto就组成了有条件跳转指令,而有条件跳转指令 正是构建整个汇编代码控制流的基石。
func If(ok bool, a, b int) int {
if ok { return a } else { return b }
}比如求两个数最大值的三元表达式 (a>b)?a:b 用If函数可以这样表达: If(a>b, a, b) 。因为语言的限制,用来模拟三元表达式的If函数不支持泛型(可以将a、b 和返回类型改为空接口,不过使用会繁琐一些)。
这个函数虽然看似只有简单的一行,但是包含了if分支语句。在改用汇编实现前, 我们还是先用汇编的思维来重新审视If函数。在改写时同样要遵循每个表达式只能 有一个运算符的限制,同时if语句的条件部分必须只有一个比较符号组成,if语句的 body部分只能是一个goto语句。
用汇编思维改写后的If函数实现如下:
func If(ok int, a, b int) int {
if ok == 0 { goto L }
return a
L:
return b
}因为汇编语言中没有bool类型,我们改用int类型代替bool类型(真实的汇编是用 byte表示bool类型,可以通过MOVBQZX指令加载byte类型的值,这里做了简化处 理)。当ok参数非0时返回变量a,否则返回变量b。我们将ok的逻辑反转下:当ok 参数为0时,表示返回b,否则返回变量a。在if语句中,当ok参数为0时goto到L标号 指定的语句,也就是返回变量b。如果if条件不满足,也就是ok参数非0,执行后面 的语句返回变量a。
上述函数的实现已经非常接近汇编语言,下面是改为汇编实现的代码:
TEXT ·If(SB), NOSPLIT, $0-32
MOVQ ok+8*0(FP), CX // ok
MOVQ a+8*1(FP), AX // a
MOVQ b+8*2(FP), BX // b
CMPQ CX, $0 // test ok
JZ L // if ok == 0, goto L
MOVQ AX, ret+24(FP) // return a
RET
L:
MOVQ BX, ret+24(FP) // return b
RET首先是将三个参数加载到寄存器中,ok参数对应CX寄存器,a、b分别对应AX、BX 寄存器。然后使用CMPQ比较指令将CX寄存器和常数0进行比较。如果比较的结果 为0,那么下一条JZ为0时跳转指令将跳转到L标号对应的语句,也就是返回变量b的 值。如果比较的结果不为0,那么JZ指令将没有效果,继续执行后面的指令,也就 是返回变量a的值。
在跳转指令中,跳转的目标一般是通过一个标号表示。不过在有些通过宏实现的函 数中,更希望通过相对位置跳转,这时候可以通过PC寄存器的偏移量来计算临近跳 转的位置
for循环
Go语言的for循环有多种用法,我们这里只选择最经典的for结构来讨论。经典的for 循环由初始化、结束条件、迭代步长三个部分组成,再配合循环体内部的if条件语 言,这种for结构可以模拟其它各种循环类型。
基于经典的for循环结构,我们定义一个LoopAdd函数,可以用于计算任意等差数列 的和:
func LoopAdd(cnt, v0, step int) int {
result := v0
for i := 0; i < cnt; i++ {
result += step
}
return result
}比如 1+2+...+100 等差数列可以这样计算 LoopAdd(100, 1, 1) , 而 10+8+...+0 等差数列则可以这样计算 LoopAdd(5, 10, -2) 。在用汇编彻底 重写之前先采用前面 if/goto 类似的技术来改造for循环。
新的LoopAdd函数只有if/goto语句构成:
func LoopAdd(cnt, v0, step int) int {
var i = 0
var result = 0
LOOP_BEGIN:
result = v0
LOOP_IF:
if i < cnt { goto LOOP_BODY }
goto LOOP_END
LOOP_BODY
i = i+1
result = result + step
goto LOOP_IF
LOOP_END:
return result
}函数的开头先定义两个局部变量便于后续代码使用。然后将for语句的初始化、结束 条件、迭代步长三个部分拆分为三个代码段,分别用LOOP_BEGIN、LOOP_IF、 LOOP_BODY三个标号表示。其中LOOP_BEGIN循环初始化部分只会执行一次, 因此该标号并不会被引用,可以省略。最后LOOP_END语句表示for循环的结束。 四个标号分隔出的三个代码段分别对应for循环的初始化语句、循环条件和循环体, 其中迭代语句被合并到循环体中了。
下面用汇编语言重新实现LoopAdd函数
#include "textflag.h"
// func LoopAdd(cnt, v0, step int) int
TEXT ·LoopAdd(SB), NOSPLIT, $0-32
MOVQ cnt+0(FP), AX // cnt
MOVQ v0+8(FP), BX // v0/result
MOVQ step+16(FP), CX // step
LOOP_BEGIN:
MOVQ $0, DX // i
LOOP_IF:
CMPQ DX, AX // compare i, cnt
JL LOOP_BODY // if i < cnt: goto LOOP_BODY
JMP LOOP_END
LOOP_BODY:
ADDQ $1, DX // i++
ADDQ CX, BX // result += step
JMP LOOP_IF
LOOP_END:
MOVQ BX, ret+24(FP) // return result
RET其中v0和result变量复用了一个BX寄存器。在LOOP_BEGIN标号对应的指令部分, 用MOVQ将DX寄存器初始化为0,DX对应变量i,循环的迭代变量。在LOOP_IF标 号对应的指令部分,使用CMPQ指令比较DX和AX,如果循环没有结束则跳转到 LOOP_BODY部分,否则跳转到LOOP_END部分结束循环。在LOOP_BODY部 分,更新迭代变量并且执行循环体中的累加语句,然后直接跳转到LOOP_IF部分进 入下一轮循环条件判断。LOOP_END标号之后就是返回累加结果的语句。
循环是最复杂的控制流,循环中隐含了分支和跳转语句。掌握了循环的写法基本也 就掌握了汇编语言的基础写法。更极客的玩法是通过汇编语言打破传统的控制流, 比如跨越多层函数直接返回,比如参考基因编辑的手段直接执行一个从C语言构建 的代码片段等。总之掌握规律之后,你会发现其实汇编语言编程会变得异常简单和 有趣。