数组、切片和映射
数组
Go 语言里,数组是一个长度固定的数据类型,用于存储一段具有相同的类型的元素的连续块。数组存储的类型可以是内置类型,如整型或者字符串,也可以是某种结构类型。
数组是一种非常有用的数据结构,因为其占用的内存是连续分配的。由于内存连续,CPU能把正在使用的数据缓存更久的时间。而且内存连续很容易计算索引,可以快速迭代数组里的所有元素。数组的类型信息可以提供每次访问一个元素时需要在内存中移动的距离。既然数组的每个元素类型相同,又是连续分配,就可以以固定速度索引数组中的任意数据,速度非常快。
声明和初始化
声明数组时需要指定内部存储的数据的类型,以及需要存储的元素的数量。
// 声明一个包含 5 个元素的整型数组
var array [5]int一旦声明,数组里存储的数据类型和数组长度就都不能改变了。如果需要存储更多的元素,就需要先创建一个更长的数组,再把原来数组里的值复制到新数组里。
Go 语言中声明变量时,总会使用对应类型的零值来对变量进行初始化。数组也不例外。当数组初始化时,数组内每个元素都初始化为对应类型的零值。
使用数组字面量声明数组
// 声明一个包含 5 个元素的整型数组
// 用具体值初始化每个元素
array := [5]int{10, 20, 30, 40, 50}Go 自动计算声明数组的长度
// 声明一个整型数组
// 用具体值初始化每个元素
// 容量由初始化值的数量决定
array := [...]int{10, 20, 30, 40, 50}声明数组并指定特定元素的值
// 声明一个有 5 个元素的数组
// 用具体值初始化索引为 1 和 2 的元素
// 其余元素保持零值
array := [5]int{1: 10, 2: 20}使用数组
要访问数组里某个单独元素,使用[]运算符
// 声明一个包含 5 个元素的整型数组
// 用具体值初始为每个元素
array := [5]int{10, 20, 30, 40, 50}
// 修改索引为 2 的元素的值
array[2] = 35访问指针数组的元素
// 声明包含 5 个元素的指向整数的数组
// 用整型指针初始化索引为 0 和 1 的数组元素
array := [5]*int{0: new(int), 1: new(int)}
// 为索引为 0 和 1 的元素赋值
*array[0] = 10
*array[1] = 20把同样类型的一个数组赋值给另外一个数组
// 声明第一个包含 5 个元素的字符串数组
var array1 [5]string
// 声明第二个包含 5 个元素的字符串数组
// 用颜色初始化数组
array2 := [5]string{"Red", "Blue", "Green", "Yellow", "Pink"}
// 把 array2 的值复制到 array1
array1 = array2编译器会阻止类型不同的数组互相赋值
// 声明第一个包含 4 个元素的字符串数组
var array1 [4]string
// 声明第二个包含 5 个元素的字符串数组
// 使用颜色初始化数组
array2 := [5]string{"Red", "Blue", "Green", "Yellow", "Pink"}
// 将 array2 复制给 array1
array1 = array2
Compiler Error:
cannot use array2 (type [5]string) as type [4]string in assignment复制数组指针,只会复制指针的值,而不会复制指针所指向的值
// 声明第一个包含 3 个元素的指向字符串的指针数组
var array1 [3]*string
// 声明第二个包含 3 个元素的指向字符串的指针数组
// 使用字符串指针初始化这个数组
array2 := [3]*string{new(string), new(string), new(string)}
// 使用颜色为每个元素赋值
*array2[0] = "Red"
*array2[1] = "Blue"
*array2[2] = "Green"
// 将 array2 复制给 array1
array1 = array2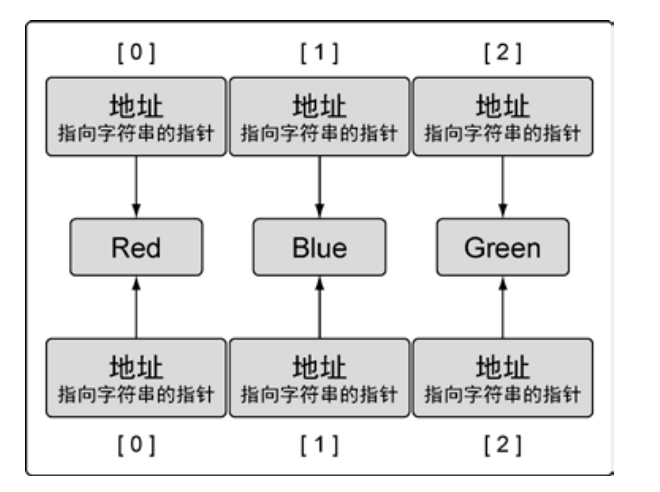
在函数间传递数组
根据内存和性能来看,在函数间传递数组是一个开销很大的操作。在函数之间传递变量时,总是以值的方式传递的。如果这个变量是一个数组,意味着整个数组,不管有多长,都会完整复制,并传递给函数。
使用值传递,在函数间传递大数组
// 声明一个需要 8 MB 的数组
var array [1e6]int
// 将数组传递给函数 foo
foo(array)
// 函数 foo 接受一个 100 万个整型值的数组
func foo(array [1e6]int) {
...
}每次函数 foo 被调用时,必须在栈上分配 8 MB 的内存。之后,整个数组的值(8 MB 的内存)被复制到刚分配的内存里。虽然 Go 语言自己会处理这个复制操作,不过还有一种更好且更有效的方法来处理这个操作。可以只传入指向数组的指针,这样只需要复制 8 字节的数据而不是 8 MB 的内存数据到栈上。
// 分配一个需要 8 MB 的数组
var array [1e6]int
// 将数组的地址传递给函数 foo
foo(&array)
// 函数 foo 接受一个指向 100 万个整型值的数组的指针
func foo(array *[1e6]int) {
...
}这次函数 foo 接受一个指向 100 万个整型值的数组的指针。现在将数组的地址传入函数,只需要在栈上分配 8 字节的内存给指针就可以。
这个操作会更有效地利用内存,性能也更好。不过要意识到,因为现在传递的是指针,所以如果改变指针指向的值,会改变共享的内存。
切片的内部实现和基础功能
切片是一种数据结构,这种数据结构便于使用和管理数据集合。切片是围绕动态数组的概念构建的,可以按需自动增长和缩小。切片的动态增长是通过内置函数 append 来实现的。这个函数可以快速且高效地增长切片。还可以通过对切片再次切片来缩小一个切片的大小。因为切片的底层内存也是在连续块中分配的,所以切片还能获得索引、迭代以及为垃圾回收优化的好处。
内部实现
切片是一个很小的对象,对底层数组进行了抽象,并提供相关的操作方法。切片有 3 个字段 的数据结构,这些数据结构包含 Go 语言需要操作底层数组的元数据。这 3 个字段分别是指向底层数组的指针、切片访问的元素的个数(即长度)和切片允许增长 到的元素个数(即容量)。

创建和初始化
make 和切片字面量
// 创建一个字符串切片
// 其长度和容量都是 5 个元素
slice := make([]string, 5)
// 创建一个整型切片
// 其长度为 3 个元素,容量为 5 个元素
slice := make([]int, 3, 5)
// 创建一个整型切片
// 使其长度大于容量
slice := make([]int, 5, 3)
Compiler Error:
len larger than cap in make([]int)通过切片字面量来声明切片
// 创建字符串切片
// 其长度和容量都是 5 个元素
slice := []string{"Red", "Blue", "Green", "Yellow", "Pink"}
// 创建一个整型切片
// 其长度和容量都是 3 个元素
slice := []int{10, 20, 30}
// 创建字符串切片
// 使用空字符串初始化第 100 个元素
slice := []string{99: ""}记住,如果在[]运算符里指定了一个值,那么创建的就是数组而不是切片。只有不指定值 的时候,才会创建切片。
// 创建有 3 个元素的整型数组
array := [3]int{10, 20, 30}
// 创建长度和容量都是 3 的整型切片
slice := []int{10, 20, 30}nil 和空切片
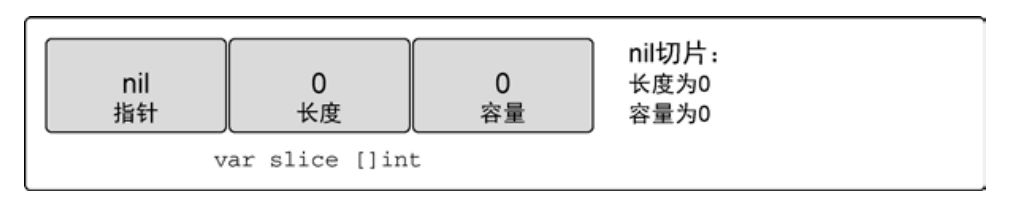
// 创建 nil 整型切片
var slice []int在 Go 语言里,nil 切片是很常见的创建切片的方法。nil 切片可以用于很多标准库和内置函数。在需要描述一个不存在的切片时,nil 切片会很好用。例如,函数要求返回一个切片但是发生异常的时候
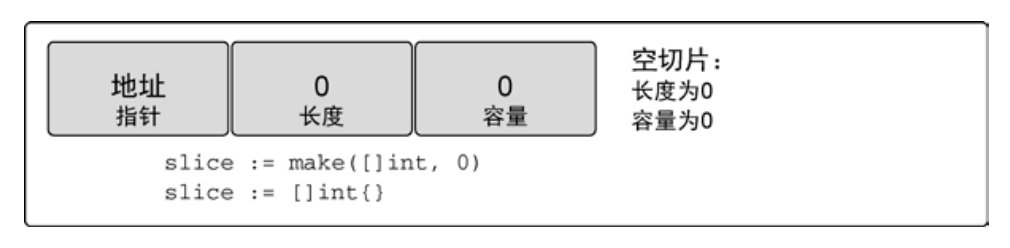
// 使用 make 创建空的整型切片
slice := make([]int, 0)
// 使用切片字面量创建空的整型切片
slice := []int{}空切片在底层数组包含 0 个元素,也没有分配任何存储空间。想表示空集合时空切片很有用,例如,数据库查询返回 0 个查询结果时
使用切片
使用切片字面量来声明切片
// 创建一个整型切片
// 其容量和长度都是 5 个元素
slice := []int{10, 20, 30, 40, 50}
// 改变索引为 1 的元素的值
slice[1] = 25使用切片创建切片
// 创建一个整型切片
// 其长度和容量都是 5 个元素
slice := []int{10, 20, 30, 40, 50}
// 创建一个新切片
// 其长度为 2 个元素,容量为 4 个元素
newSlice := slice[1:3]我们有了两个切片,它们共享同一段底层数组,但通过不同的切片会看到底层数组的不同部分
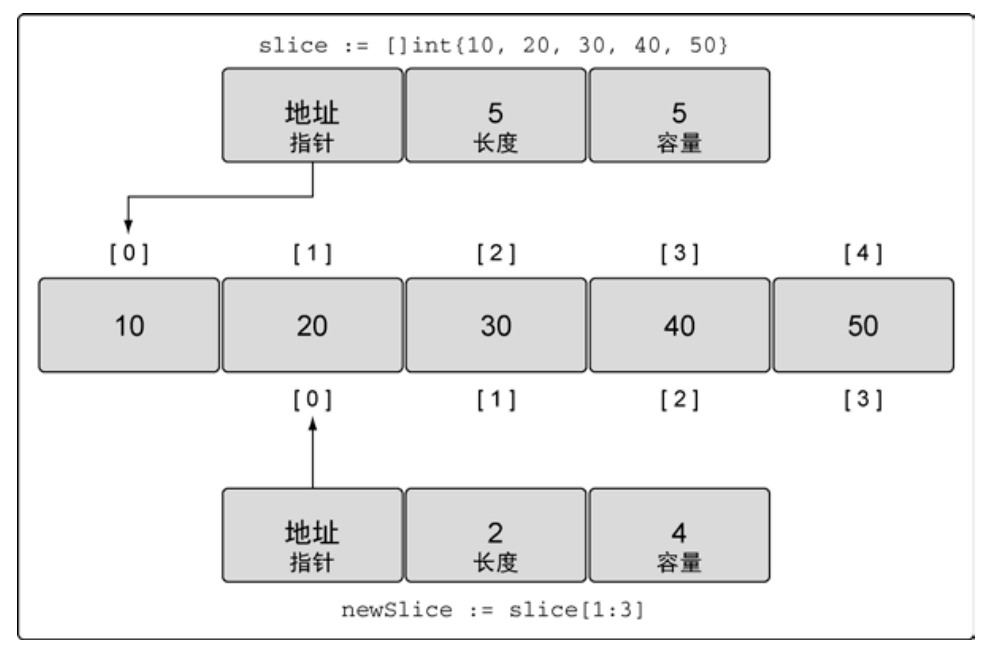
如何计算长度和容量
对底层数组容量是 k 的切片 slice[i:j]来说
长度: j - i
容量: k - i修改切片内容可能导致的结果
// 创建一个整型切片
// 其长度和容量都是 5 个元素
slice := []int{10, 20, 30, 40, 50}
// 创建一个新切片
// 其长度是 2 个元素,容量是 4 个元素
newSlice := slice[1:3]
// 修改 newSlice 索引为 1 的元素
// 同时也修改了原来的 slice 的索引为 2 的元素
newSlice[1] = 35把 35 赋值给 newSlice 的第二个元素(索引为 1 的元素)的同时也是在修改原来的 slice 的第 3 个元素(索引为 2 的元素)
切片只能访问到其长度内的元素。试图访问超出其长度的元素将会导致语言运行时异常,与切片的容量相关联的元素只能用于增长切片。在使用这部分元素前,必须将其合并到切片的长度里。
切片增长
当append 调用返回时,会返回一个包含修改结果的新切片。函数 append 总是会增加新切片的长度,而容量有可能会改变,也可能不会改变,这取决于被操作的切片的可用容量。
使用 append 向切片增加元素
// 创建一个整型切片
// 其长度和容量都是 5 个元素
slice := []int{10, 20, 30, 40, 50}
// 创建一个新切片
// 其长度为 2 个元素,容量为 4 个元素
newSlice := slice[1:3]
// 使用原有的容量来分配一个新元素
// 将新元素赋值为 60
newSlice = append(newSlice, 60)
因为 newSlice 在底层数组里还有额外的容量可用,append 操作将可用的元素合并到切片的长度,并对其进行赋值。由于和原始的 slice 共享同一个底层数组,slice 中索引为 3 的元素的值也被改动了。
如果切片的底层数组没有足够的可用容量,append 函数会创建一个新的底层数组,将被引用的现有的值复制到新数组里,再追加新的值。
使用 append 同时增加切片的长度和容量
// 创建一个整型切片
// 其长度和容量都是 4 个元素
slice := []int{10, 20, 30, 40}
// 向切片追加一个新元素
// 将新元素赋值为 50
newSlice := append(slice, 50)当这个 append 操作完成后,newSlice 拥有一个全新的底层数组,这个数组的容量是原来的两倍。

函数 append 会智能地处理底层数组的容量增长。在切片的容量小于 1000 个元素时,总是会成倍地增加容量。一旦元素个数超过 1000,容量的增长因子会设为 1.25,也就是会每次增加 25%的容量。随着语言的演化,这种增长算法可能会有所改变。
创建切片时的 3 个索引
在创建切片时,还可以使用之前我们没有提及的第三个索引选项。第三个索引可以用来控制 新切片的容量。其目的并不是要增加容量,而是要限制容量。可以看到,允许限制新切片的容量 为底层数组提供了一定的保护,可以更好地控制追加操作。
// 创建字符串切片
// 其长度和容量都是 5 个元素
source := []string{"Apple", "Orange", "Plum", "Banana", "Grape"}
// 将第三个元素切片,并限制容量
// 其长度为 1 个元素,容量为 2 个元素
slice := source[2:3:4]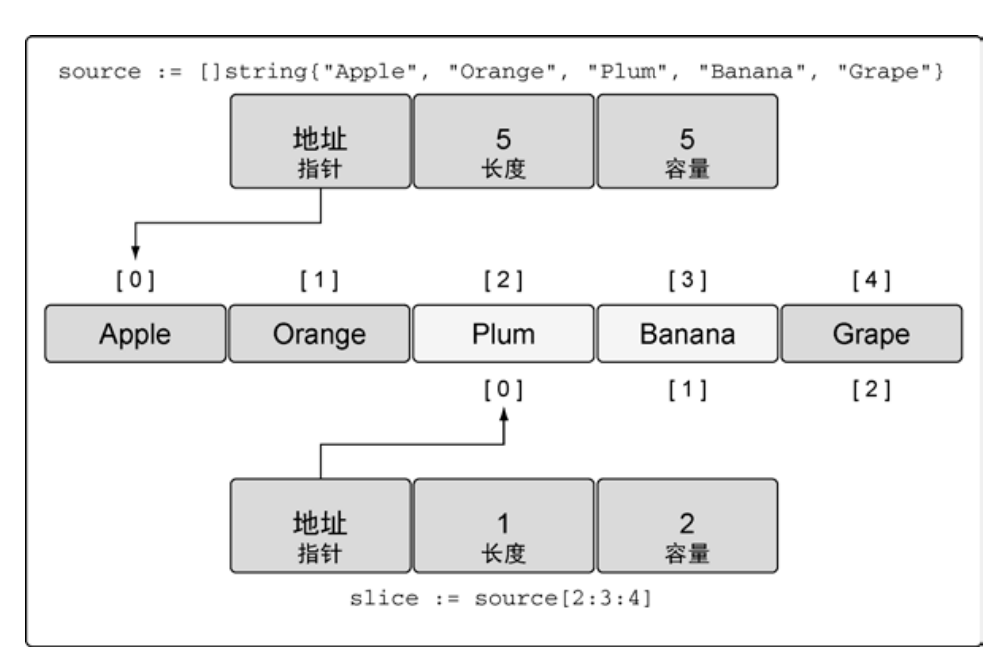
设置容量大于已有容量的语言运行时错误
// 这个切片操作试图设置容量为 4
// 这比可用的容量大
source := []string{"Apple", "Orange", "Plum", "Banana", "Grape"}
slice := source[2:3:6]
// 6 > 5
Runtime Error:
panic: runtime error: slice bounds out of range内置函数 append 会首先使用可用容量。一旦没有可用容量,会分配一个新的底层数组。这导致很容易忘记切片间正在共享同一个底层数组。一旦发生这种情况,对切片修改,很可能会导致随机且奇怪的问题。对切片内容的修改会影响多个切片,却很难找到问题的原因。
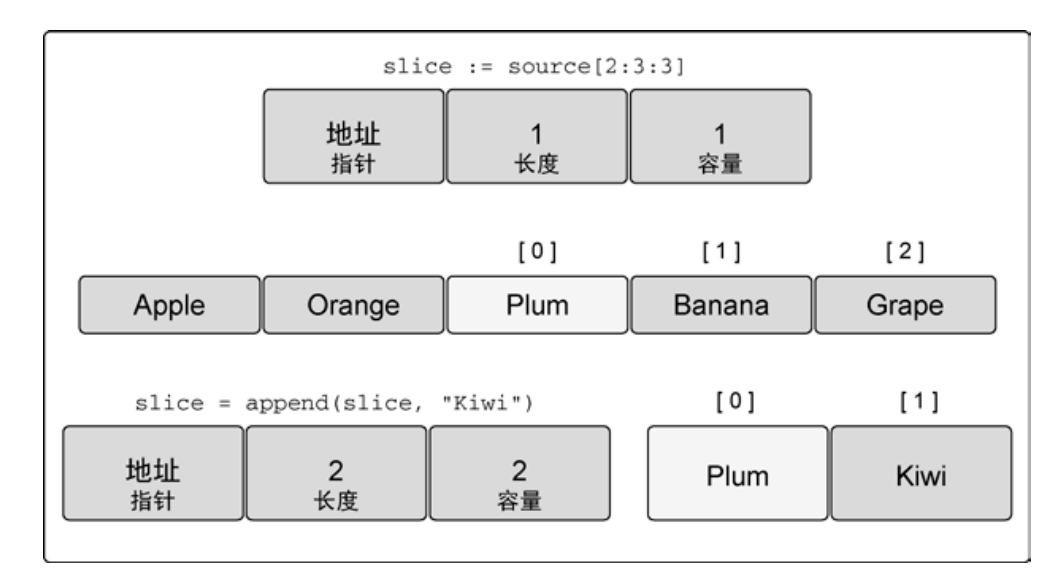
如果在创建切片时设置切片的容量和长度一样,就可以强制让新切片的第一个 append 操作创建新的底层数组,与原有的底层数组分离。新切片与原有的底层数组分离后,可以安全地进行后续修改。
// 创建字符串切片
// 其长度和容量都是 5 个元素
source := []string{"Apple", "Orange", "Plum", "Banana", "Grape"}
// 对第三个元素做切片,并限制容量
// 其长度和容量都是 1 个元素
slice := source[2:3:3]
// 向 slice 追加新字符串
slice = append(slice, "Kiwi")如果不加第三个索引,由于剩余的所有容量都属于 slice,向 slice 追加 Kiwi 会改变原有底层数组索引为 3 的元素的值 Banana。不过我们限制了 slice 的容量为 1。当我们第一次对 slice 调用 append 的时候,会创建一个新的底层数组,这个数组包括 2 个元素,并将水果 Plum 复制进来,再追加新水果 Kiwi,并返回一个引用了这个底层数组的新切片.
因为新的切片 slice 拥有了自己的底层数组,所以杜绝了可能发生的问题。我们可以继续向新切片里追加水果,而不用担心会不小心修改了其他切片里的水果。同时,也保持了为切片申请新的底层数组的简洁。
内置函数 append 也是一个可变参数的函数。这意味着可以在一次调用传递多个追加的值。如果使用...运算符,可以将一个切片的所有元素追加到另一个切片里.
// 创建两个切片,并分别用两个整数进行初始化
s1 := []int{1, 2}
s2 := []int{3, 4}
// 将两个切片追加在一起,并显示结果
fmt.Printf("%v\n", append(s1, s2...))
Output:
[1 2 3 4]迭代切片
// 创建一个整型切片
// 其长度和容量都是 4 个元素
slice := []int{10, 20, 30, 40}
// 迭代每一个元素,并显示其值
for index, value := range slice {
fmt.Printf("Index: %d Value: %d\n", index, value)
}
当迭代切片时,关键字 range 会返回两个值。第一个值是当前迭代到的索引位置,第二个值是该位置对应元素值的一份副本,需要强调的是,range 创建了每个元素的副本,而不是直接返回对该元素的引用。如果使用该值变量的地址作为指向每个元素的指针,就会造成错误。让我们看看是为什么。
// 创建一个整型切片
// 其长度和容量都是 4 个元素
slice := []int{10, 20, 30, 40}
// 迭代每个元素,并显示值和地址
for index, value := range slice {
fmt.Printf("Value: %d Value-Addr: %X ElemAddr: %X\n",
value, &value, &slice[index])
}
Output:
Value: 10 Value-Addr: 10500168 ElemAddr: 1052E100
Value: 20 Value-Addr: 10500168 ElemAddr: 1052E104
Value: 30 Value-Addr: 10500168 ElemAddr: 1052E108
Value: 40 Value-Addr: 10500168 ElemAddr: 1052E10C因为迭代返回的变量是一个迭代过程中根据切片依次赋值的新变量,所以 value 的地址总是相同的。要想获取每个元素的地址,可以使用切片变量和索引值。
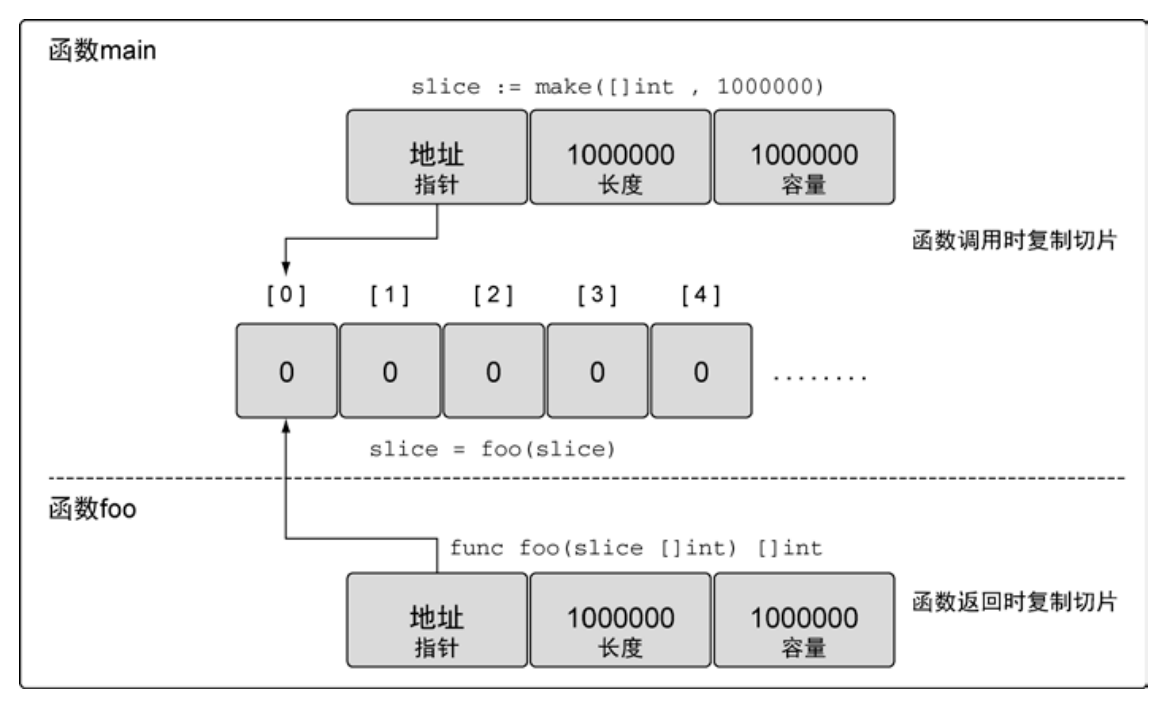
在函数间传递切片
在函数间传递切片就是要在函数间以值的方式传递切片。由于切片的尺寸很小,在函数间复制和传递切片成本也很低。让我们创建一个大切片,并将这个切片以值的方式传递给函数 foo。
// 分配包含 100 万个整型值的切片
slice := make([]int, 1e6)
// 将 slice 传递到函数 foo
slice = foo(slice)
// 函数 foo 接收一个整型切片,并返回这个切片
func foo(slice []int) []int {
...
return slice
}64 位架构的机器上,一个切片需要 24 字节的内存:指针字段需要 8 字节,长度和容量字段分别需要 8 字节。由于与切片关联的数据包含在底层数组里,不属于切片本身,所以将切片复制到任意函数的时候,对底层数组大小都不会有影响。复制时只会复制切片本身,不会涉及底层数组
映射的内部实现和基础功能
映射是一个集合,可以使用类似处理数组和切片的方式迭代映射中的元素。但映射是无序的 集合,意味着没有办法预测键值对被返回的顺序。即便使用同样的顺序保存键值对,每次迭代映 射的时候顺序也可能不一样。
使用 make 声明映射
// 创建一个映射,键的类型是 string,值的类型是 int
dict := make(map[string]int)
// 创建一个映射,键和值的类型都是 string
// 使用两个键值对初始化映射
dict := map[string]string{"Red": "#da1337", "Orange": "#e95a22"}映射的键可以是任何值。这个值的类型可以是内置的类型,也可以是结构类型,只要这个值 可以使用==运算符做比较。切片、函数以及包含切片的结构类型这些类型由于具有引用语义, 不能作为映射的键,使用这些类型会造成编译错误.
使用映射字面量声明空映射
// 创建一个映射,使用字符串切片作为映射的键
dict := map[[]string]int{}
Compiler Exception:
invalid map key type []string使用映射
// 创建一个空映射,用来存储颜色以及颜色对应的十六进制代码
colors := map[string]string{}
// 将 Red 的代码加入到映射
colors["Red"] = "#da1337"可以通过声明一个未初始化的映射来创建一个值为 nil 的映射(称为 nil 映射 )。nil 映射 不能用于存储键值对,否则,会产生一个语言运行时错误。
// 通过声明映射创建一个 nil 映射
var colors map[string]string
// 将 Red 的代码加入到映射
colors["Red"] = "#da1337"
Runtime Error:
panic: runtime error: assignment to entry in nil map从映射获取值并判断键是否存在
// 获取键 Blue 对应的值
value, exists := colors["Blue"]
// 这个键存在吗?
if exists {
fmt.Println(value)
}
// 获取键 Blue 对应的值
value := colors["Blue"]
// 这个键存在吗?
if value != "" {
fmt.Println(value)
}在 Go 语言里,通过键来索引映射时,即便这个键不存在也总会返回一个值。在这种情况下, 返回的是该值对应的类型的零值。
使用 range 迭代映射
// 创建一个映射,存储颜色以及颜色对应的十六进制代码
colors := map[string]string{
"AliceBlue": "#f0f8ff",
"Coral": "#ff7F50",
"DarkGray": "#a9a9a9",
"ForestGreen": "#228b22",
}
// 显示映射里的所有颜色
for key, value := range colors {
fmt.Printf("Key: %s Value: %s\n", key, value)
}从映射中删除一项
// 删除键为 Coral 的键值对
delete(colors, "Coral")
// 显示映射里的所有颜色
for key, value := range colors {
fmt.Printf("Key: %s Value: %s\n", key, value)
}注:这种方法只能用在映射存储的值都是非零值的情况
在函数间传递映射
在函数间传递映射并不会制造出该映射的一个副本。实际上,当传递映射给一个函数,并对 这个映射做了修改时,所有对这个映射的引用都会察觉到这个修改
func main() {
// 创建一个映射,存储颜色以及颜色对应的十六进制代码
colors := map[string]string{
"AliceBlue": "#f0f8ff",
"Coral": "#ff7F50",
"DarkGray": "#a9a9a9",
"ForestGreen": "#228b22",
}
// 显示映射里的所有颜色
for key, value := range colors {
fmt.Printf("Key: %s Value: %s\n", key, value)
}
// 调用函数来移除指定的键
removeColor(colors, "Coral")
// 显示映射里的所有颜色
for key, value := range colors {
fmt.Printf("Key: %s Value: %s\n", key, value)
}
}
// removeColor 将指定映射里的键删除
func removeColor(colors map[string]string, key string) {
delete(colors, key)
}