索引恢复流程分析
索引恢复(indices.recovery)是ES数据恢复过程。待恢复的数据是客户端写入成功,但未执行刷盘(flush)的Lucene分段。例如,当节点异常重启时,写入磁盘的数据先到文件系统的缓冲,未必来得及刷盘,如果不通过某种方式将未刷盘的数据找回来,则会丢失一些数据,这是保持数据完整性的体现;另一方面,由于写入操作在多个分片副本上没有来得及全部执行,副分片需要同步成和主分片完全一致,这是数据副本一致性的体现。
根据数据分片性质,索引恢复过程可分为主分片恢复流程和副分 片恢复流程。
- 主分片从translog中自我恢复,尚未执行flush到磁盘的Lucene分段可以从translog中重建;
- 副分片需要从主分片中拉取Lucene分段和translog进行恢复。但是有机会跳过拉取Lucene分段的过程。
索引恢复的触发条件包括从快照备份恢复、节点加入和离开、索 引的_open操作等。
恢复工作一般经历以下几个阶段(stage),如下表所示

主分片和副分片恢复都会经历这些阶段,但有时候会跳过具体执 行过程,只是在流程上体现出经历了这个短暂阶段。例如,副分片恢复时会跳过 TRANSLOG 重放过程;主分片恢复过程中的INDEX阶段不会在节点之间复制数据。
相关配置
索引恢复流程有以下配置项,都支持动态调整,如下表所示。

流程概述
recovery由clusterChanged触发,从触发到开始执行恢复的调 用关系如下: indicesClusterStateService#applyClusterState ->createOrUpdateShards() ->createShard() ->indicesService.createShard() ->indexShard.startRecovery()
此时执行线程池为clusterApplierService#updateTask,执行具体的恢复工作时,会到另一个线程池中执行。无论哪种恢复类型,都在generic线程池中。
主分片恢复流程
1. INIT阶段
一个分片的恢复流程中,从开始执行恢复的那一刻起,被标记为 INIT 阶段,INIT 标记在IndexShard#startRecovery 函数的参数中传入,在判断此分片属于哪种恢复类型之前就被设置为INIT阶段。
接下来,恢复流程在新的线程池中开始执行,开始阶段主要是一 些验证工作,例如,校验当前分片是否为主分片,分片状态是否异常等。
做完简单的校验工作后,进入INDEX阶段。
2. INDEX阶段
本阶段从Lucene读取最后一次提交的分段信息,获取其中的版本 号,更新当前索引版本:
final Store store = indexShard.store();
si = store.readLastCommittedSegmentsInfo();
version = si.getVersion();
recoveryState.getIndex().updateVersion(version);3. VERIFY_INDEX阶段
VERIFY_INDEX中的INDEX指Lucene index,因此本阶段的作 用是验证当前分片是否损坏,是否进行本项检查取决于配置项:
index.shard.check_on_startup该配置的取值如下表所示。


在索引的数据量较大时,分片检查会消耗更多的时间。
验证工作在 IndexShard#checkIndex 函数中完成。验证过程通过对比元信息中记录的checksum与Lucene文件的实际值,或者调用Lucene CheckIndex类中的checkIndexexorciseIndex方法完成。
默认配置为不执行验证索引,进入最重要的TRANSLOG阶段。
4. TRANSLOG阶段
一个Lucene索引由许多分段组成,每次搜索时遍历所有分段。内 部维护了一个称为“提交点”的信息,其描述了当前Lucene索引都包括哪些分段,这些分段已经被fsync系统调用,从操作系统的cache刷入磁盘。每次提交操作都会将分段刷入磁盘实现持久化。
本阶段需要重放事务日志中尚未刷入磁盘的信息,因此,根据最 后一次提交的信息做快照,来确定事务日志中哪些数据需要重放。重放完毕后将新生成的Lucene数据刷入磁盘。
5. FINALIZE阶段 本阶段执行刷新(refresh)操作,将缓冲的数据写入文件,但不 刷盘,数据在操作系统的cache中。
6. DONE阶段 DONE阶段是恢复工作的最后一个阶段,进入DONE阶段之前再次 执行refresh,然后更新分片状态。至此,主分片恢复完毕,对恢复结果进行处理。
副分片恢复流程
副分片恢复的核心思想是从主分片拉取Lucene分段和translog进 行恢复。按数据传递的方向,主分片节点称为Source,副分片节点称为Target。
为什么需要拉取主分片的translog?因为在副分片恢复期间允许新的写操作,从复制Lucene分段的那一刻开始,所恢复的副分片数据不包括新增的内容,而这些内容存在于主分片的translog中,因此副分片需要从主分片节点拉取translog进行重放,以获取新增内容。这就需要主分片节点的translog不被清理。为了防止主分片节点的translog被清理,这方面的实现机制经历了多次迭代。
在1.x版本时代,通过阻止刷新(refresh)操作,让translog都保留下来。但是这样可能会产生很大的translog。
在2.0~5.x版本时代,引入了translog.view的概念:
- 为了安全地完成recoveries/relocations操作,我们必须在 recovery过程开始后保证所有的操作已全部处理(一个特定的索引或更新请求称为一个操作),以便重放。目前是通过防止engine flush,从而确保操作operations都在translog中来实现的。这没问题,因为我们确实需要这些operations。如果另一个recovery并发启动,则可能会有不必要的长时间重试。如果我们在这个时候因为某种原因关闭了Engine(比如一个节点重新启动),当再次启动的时候,我们需要恢复一个很大的translog。
- 为了解决这个问题,translog被改为基于多个文件而不是一个文件。这允许recovery保留所需的文件,同时允许Engine执行flush,以及执行Lucene的commit(这将创建一个新的translog文件)。
- 重构了translog文件管理模块,允许存在多个文件。
- translog维护一个引用文件的列表,包括未完成的recovery,以及那些包含尚未提交到Lucene的operations的文件。
- 引入了新的translog.view概念,允许recovery获取一个引用,包括所有当前未提交的translog 文件,以及所有未来新创建的translog 文 件 , 直 到 view 关 闭 。 它 们 可 以 使 用 这 个 view 做operations的遍历操作。
创建一个视图可以获取后续的所有操作,直到关闭视图。刷新可 以自由执行,translog文件删除逻辑基于文件级别的引用计数。当获得一个视图时,这些计数器会增加。创建快照时同样会用到视图来读取 translog 中的操作,视图必须一直保存直到最后一个快照被消费完 。这 在 recovery 流 程 中 没 问 题 , 但 是 在 Primary Replica Resyncer中存在一个小bug,只影响未发布的代码。具体请参考 https://github.com/elastic/elasticsearch/pull/25862。
因此从6.0版本开始,translog.view 被移除。引入 TranslogDeletionPolicy 的概念,负责维护活跃( liveness )的translog文件。这个类的实现非常简单,它将translog做一个快照来保持translog不被清理。这样使用者只需创建一个快照,无须担心视图之类。恢复流程实际上确实需要一个视图,现在可以通过获取一个简单的保留锁来防止清理translog。这消除了视图概念的需求。在保证translog不被清理后,恢复核心处理过程由两个内部阶段(phase)组成。
phase1:在主分片所在节点,获取translog保留锁,从获取保 留锁开始,会保留translog不受其刷盘清空的影响。然后调用Lucene接口把shard做快照,快照含有shard中已经刷到磁盘的文件引用,把这些shard数据复制到副本节点。在phase1结束前,会向副分片节点发送告知对方启动Engine,在phase2开始之前,副分片就可以正常处理写请求了。
phase2:对translog做快照,这个快照里包含从phase1开 始,到执行translog快照期间的新增索引。将这些translog发送到副分片所在节点进行重放。由于phase1需要通过网络复制大量数据,过程非常漫长,在ES6.x中,有两个机会可以跳过phase1:
- (1)如果可以基于恢复请求中的SequenceNumber进行恢复, 则跳过phase1。
- (2)如果主副两分片有相同的syncid且doc数相同,则跳过 phase1。
synced flush机制
为了解决副分片恢复过程第一阶段时间太漫长而引入了synced flush,默认情况下5分钟没有写入操作的索引被标记为inactive,执行synced flush,生成一个唯一的syncid,写入分片的所有副本中。这个syncid是分片级,意味着拥有相同syncid的分片具有相同的Lucene索引。
synced flush本质上是一次普通的flush操作,只是在Lucene的commit过程中多写了一个syncid。原则上,在没有数据写入的情况下,各分片在同一时间“flush”成功后,它们理应有相同的Lucene索引内容,无论Lucene分段是否一致。于是给分片分配一个id,表示数据一致。
但 是 显 然 synced flush 期 间 不 能 有 新 写 入 的 内 容 , 如 果syncflush执行期间收到写请求,则ES选择了写入可用性:让synced flush失败,让写操作成功。在没有执行flush的情况下已有syncid不会失效。
在某个分片上执行普通flush操作会删除已有syncid。因此, synced flush操作是一个不可靠操作,只适用于冷索引。
副分片节点处理过程
副分片恢复的 VERIFY_INDEX、TRANSLOG、FINALIZE 三个阶 段由主分片节点发送的RPC调用触发,如下图所示。
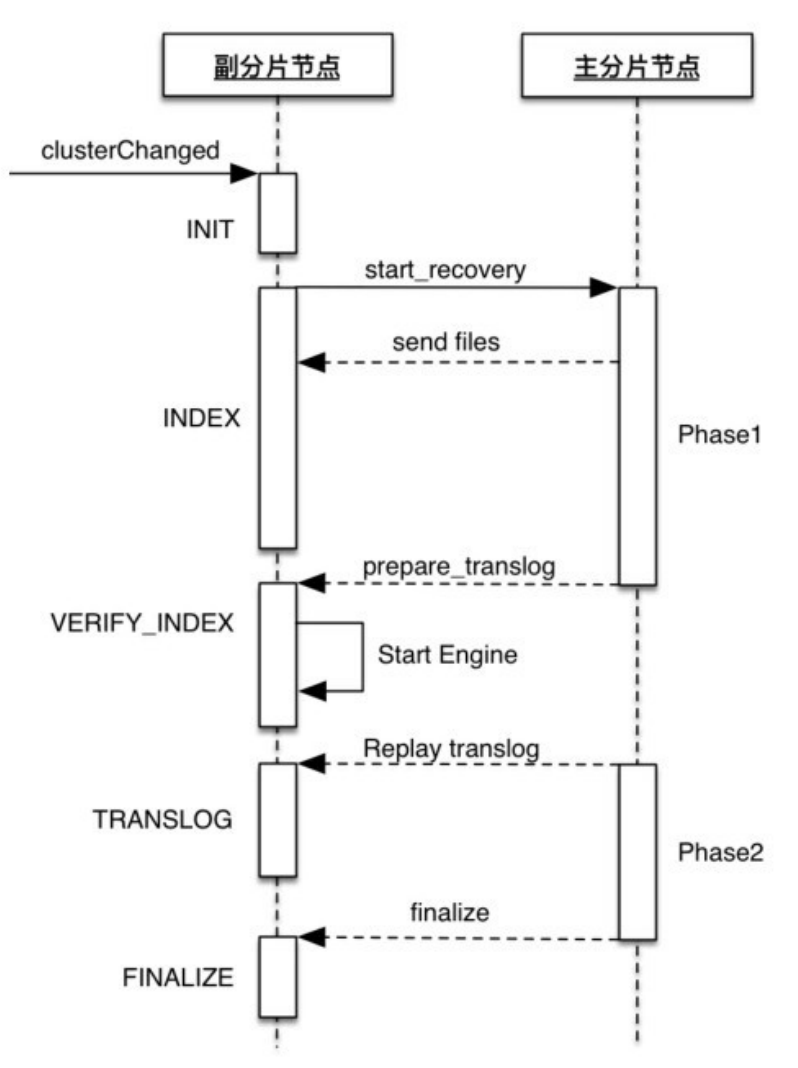
在副分片恢复过程中,副分片节点会向主分片节点发送start_recovery的RPC请求,主分片节点对此请求的处理注册在 PeerRecoverySourceService 类中,内部类 PeerRecoverySourceService.StartRecoveryTransportRequestHandler负责处理此RPC请求。
类似的,主分片节点也会向副分片节点发送一些RPC请求,副分 片节点对这些请求的处理以XXXRequestHandler的方式注册在 PeerRecoveryTargetService类中,包括接收Lucene文件、接收translog并重放、执行清理等操作
1. INIT阶段
本阶段在副分片节点执行。 与主分片恢复的INIT阶段类似,恢复任务开始时被设置为INIT阶 段,进行副分片恢复时,在新的线程池中执行恢复任务。
构建准备发往主分片的StartRecoveryRequest请求,请求中包 括将本次要恢复的shard相关信息,如shardid 、metadataSnapshot等。metadataSnapshot中包含syncid。然后进入INDEX阶段
2. INDEX阶段
INDEX阶段负责将主分片的Lucene数据复制到副分片节点。向主分片节点发送action为 internal:index/shard/recovery/start_recovery的PRC请求,并阻塞当前线程,等待响应,直到对方处理完成。然后设置为DONE阶段。概括来说,主分片节点收到请求后把Lucene和translog发送给副分片。
线程阻塞等待INDEX阶段完成,然后直接到DONE阶段。在这期 间主分片节点会发送几次RPC调用,通知副分片节点启动Engine,执行清理等操作。VERIFY_INDEX和TRANSLOG阶段也是由主分片节点的RPC调用触发的。
3. VERIFY_INDEX阶段
副分片的索引验证过程与主分片相同,是否进行验证取决于配 置。默认为不执行索引验证。
4. TRANSLOG阶段
TRANSLOG阶段负责将主分片的translog数据复制到副分片节点 进行重放。
先创建新的Engine,跳过Engine自身的translog恢复。此时主 分片的phase2尚未开始,接下来的 TRANSLOG 阶段就是等待主分片节点将 translog 发到副分片节点进行重放,也就是phase2的执行过程。
5. FINALIZE阶段
主分片节点执行完 phase2,调用 finalizeRecovery,向副分片节点发送 action 为internal:index/shard/recovery/finalize 的RPC请求,副分片节点对此 action的处理为先更新全局检查点,然后执行与主分片相同的清理操作
6. DONE阶段
副分片节点等待INDEX阶段执行完成后,调用onGoingRecoveries.markRecoveryAsDon(recoveryId)进入DONE 阶段。主要处理是调用indexShard#postRecovery,与主分片的postRecovery处理过程相同,包括对恢复成功或失败的处理,也和主分片的处理过程相同。
主分片节点处理过程
副分片恢复的INDEX阶段向主分片节点发送 action 为internal:index/shard/recovery/start_recovery 的恢复请求,主分片对此请求的处理过程是副分片恢复的核心流程。核心流程如下图所示。
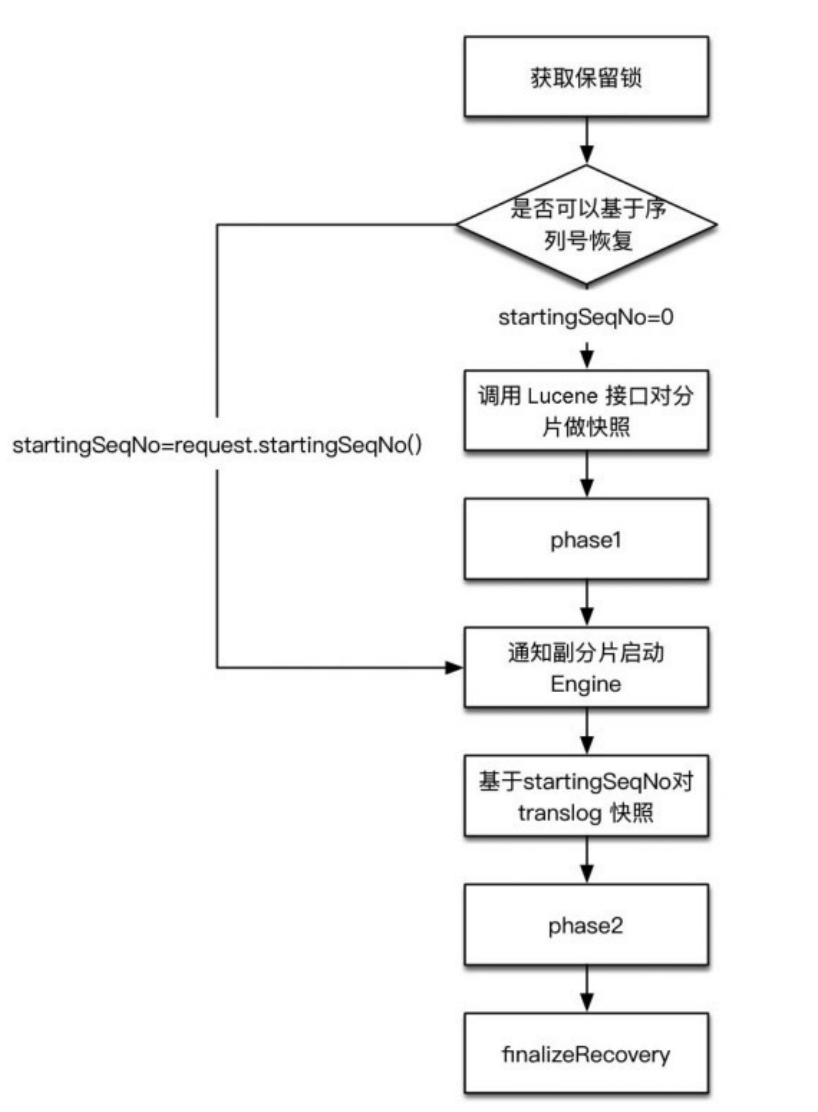
phase1检查目标节点上的段文件,并对缺失的部分进行复制。只 有具有相同大小和校验和的段才能被重用。但是由于分片副本执行各自的合并策略,所以合并出来的段文件相同的概率很低。
phase2将translog批量发送到副分片节点,发送时将待发送的 translog组合成一批来提高发送效率,默认的批量大小为512KB,不支持配置。
recovery速度优化
众所周知,索引恢复是集群启动过程中最缓慢的过程,集群完全重启,或者Master节点挂掉后,新选出的Master也有可能执行这个过程。
下面归纳一下有哪些方法可以提升索引恢复速度:
- 配置项cluster.routing.allocation.node_concurrent_recoveries 决定了单个节点执行副分片recovery时的最大并发数(进/出),默认为2,适当提高此值可以增加recovery并发数。
- 配置项indices.recovery.max_bytes_per_sec决定节点间复制数据时的限速,可以适当提高此值或取消限速。
- 配置项cluster.routing.allocation.node_initial_primaries_recoveries 决定了单个节点执行主分片recovery时的最大并发数,默认为4。由于主分片的恢复不涉及在网络上复制数据,仅在本地磁盘读写,所以在节点配置了多个数据磁盘的情况下,可以适当提高此值。
- 在重启集群之前,先停止写入端,执行sync flush,让恢复过程有机会跳过phase1。
- 适当地多保留些translog,配置项index.translog.retention.size 默认最大保留512MB,index.translog.retention.age默认为不超过12小时。调整这两个配置可让恢复过程有机会跳过phase1。
- 合并 Lucene 分段,对于冷索引甚至不再更新的索引执行 _forcemerge,较少的 Lucene分段可以提升恢复效率,例如,减少对比,降低文件传输请求数量。
- 最后,可以考虑允许主副分片存在一定程度的不一致,修改 ES 恢复流程,少量的不一致则跳过phase1。
如何保证副分片和主分片一致
索引恢复过程的一个难点在于如何维护主副分片的一致性。假设 副分片恢复期间一直有写操作,如何实现一致呢?我们先看看早期的做法:在2.0版本之前,副分片恢复要经历三个阶段。
- phase1:将主分片的 Lucene 做快照,发送到 target。期间不 阻塞索引操作,新增数据写到主分片的translog。
- phase2:将主分片translog做快照,发送到target重放,期间 不阻塞索引操作。
- phase3:为主分片加写锁,将剩余的translog发送到target。此时数据量很小,写入过程的阻塞很短。
从理论上来说,只要流程上允许将写操作阻塞一段时间,实现主 副一致是比较容易的。
但是后来(从2.0版本开始),也就是引入translog.view概念的同时,phase3被删除。
phase3被删除,这个阶段是重放操作(operations),同时防 止新的写入 Engine。这是不必要的,因为自恢复开始,标准的 index操作会发送所有的操作到正在恢复中的分片。重放恢复开始时获取的view中的所有操作足够保证不丢失任何操作。
阻塞写操作的phase3被删除,恢复期间没有任何写阻塞过程。接 下来需要处理的就是解决phase1和phase2之间的写操作与phase2重放操作之间的时序和冲突问题。在副分片节点,phase1结束后,假如新增索引操作和 translog 重放操作并发执行,因为时序的关系会出现新老数据交替。如何实现主副分片一致呢?
假设在第一阶段执行期间,有客户端索引操作要求将docA的内容 写为1,主分片执行了这个操作,而副分片由于尚未就绪所以没有执行。第二阶段期间客户端索引操作要求写 docA 的内容为2,此时副分片已经就绪,先执行将docA写为2的新增请求,然后又收到了从主分片所在节点发送过来的translog重复写docA为1的请求该如何处理?
答案是在写流程中做异常处理,通过版本号来过滤掉过期操作。 写操作有三种类型:索引新文档、更新、删除。索引新文档不存在冲突问题,更新和删除操作采用相同的处理机制。每个操作都有一个版本号,这个版本号就是预期doc版本,它必须大于当前Lucene中的doc版本号,否则就放弃本次操作。对于更新操作来说,预期版本号是Lucene doc版本号+1。主分片节点写成功后新数据的版本号会放到写副本的请求中,这个请求中的版本号就是预期版本号。这样,时序上存在错误的操作被忽略,对于特定 doc,只有最新一次操作生效,保证了主副分片一致。
1. 索引新文档
不存在冲突问题,不需要处理。
2. 更新
判断本次操作的版本号是否小于Lucene中doc的版本号,如果小 于,则放弃本次操作。Index、Delete 都继承自 Operation,每个 Operation 都有一个版本号,这个版本号就是 doc版本号。对于副分片的写流程来说,正常情况下是主分片写成功后,相应doc写入的版本号被放到转发写副分片的请求中。对于更新来说,就是通过主分片将原doc版本号+1后转发到副分片实现的。
3. 删除
判断本次操作中的版本号是否小于Lucene中doc的版本号,如果 小于,则放弃本次操作。
recovery相关监控命令
在实际生产环境中我们经常需要了解recovery的进度和状态,ES 提供了丰富的API可以获取这些信息。
_cat/recovery 列出活跃的和已完成的recovery信息
{index}/_recovery 此API展示特定索引的recovery所处阶段,以及每个分片、每个 阶段的详细信息。
_stats 有时我们想知道sync flush是否完成,_stats API可以给出分片级信息,包括分片的sync_id 、 local_checkpoint 、global_checkpoint等,可以通过指定索引名称实现,或者使用_all输出全部索引的信息。
最后
- 主分片恢复的主要阶段是TRANSLOG阶段;
- 副分片恢复的主要阶段是INDEX和TRANSLOG阶段;
- 只有phase1有限速配置,phase2不限速;
- Lucene的“提交”概念就是从操作系统内存cache fsync到磁盘的过程。