网络请求超时,一次哭笑不得的错误排查
最近生产上的某个系统拉取上游的服务偶发性的拉取不上来【报错显示超时、500 error】,遂对其进行了一次全方面的排查和分析,这篇文章便是记录一下这次问题排查的。
背景
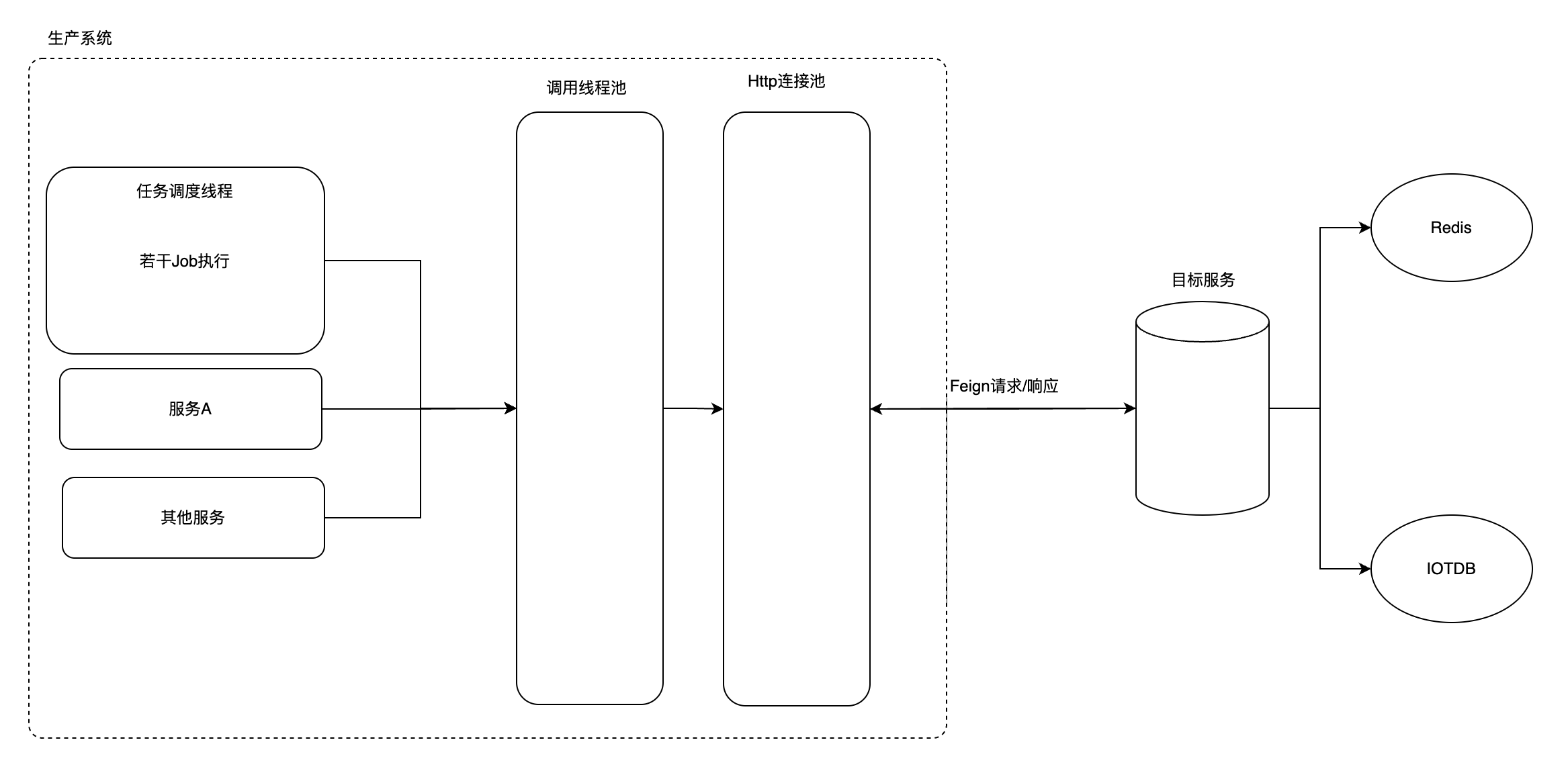
具体调用链路如上图所示,往大了看就是很平常的Feign调用,但往再下看细看,在调用端,也就是从HttpClient连接池调用发起往回推到,可以看见线程池里面的若干任务都有调用这个Feign接口,继续往前追溯,可以找到具体的调用入口,这里主要分为了三大类,调度任务、服务A以及其他服务。
- 调度任务:在交接班,每天早8晚8的时候会调度大量任务,其中不少任务都会走调用服务调用Feign获取对应数据【每次高峰期大概会发起n次调用】。
- 服务A:相对于调度任务会比较频繁调用,每半分钟大概会发起n次请求【后续进行了优化,中间加了一层redis,大概每半分钟只会发起n/几十次调用】
- 其他服务:这块对调用服务的调用相对很少,这里只是列出来。根据经验这块其实不是影响因素,后续证明也确实不是。
而往后看被调用端,就是一个暴露服务,根据不同接口走redis查询亦或IOTDB查询【这块还是拉上对应服务团队的人开会才了解到的,毕竟对于我们调用方来讲,调用的服务内部实现是一个黑盒】
因此,整个请求调用服务链路节点大致如上。
问题排查三板斧
在理清楚整个调用链路节点后,首要任务不是立即定位根因,而是快速缩小排查范围。这个时候,"三板斧"法则就显得尤为重要——网络、内存、CPU,三者合一,几乎覆盖了 80% 的线上问题。
一斧:网络先查通断与延迟
网络问题是系统中最常见也是最隐蔽的问题。尤其是跨可用区、跨地域部署时,网络的不稳定往往是性能下降的元凶。特别是在我们这里报错捕获的异常还是一个网络请求超时。
典型症状:
请求超时 / Socket hang up / 连接重置
某个服务节点响应慢,但代码本身没变化【符合当前症状】
链路追踪中发现"卡"在调用外部依赖时
排查手段:
查看链路追踪中某一 hop 的耗时分布,是否集中在某个节点或 IP 上。
检查服务间网络 RTT(Round Trip Time),比如使用 ping、traceroute、或者服务内埋点的连接耗时指标。
如果是 K8s 场景,建议排查 CNI 插件的转发性能,以及是否有 SNAT/iptables 层转发瓶颈。
但遗憾的是,通过指标数据分析,网络的问题被排除了。正常情况下的请求响应都是毫秒级别。而对于高峰情况下才暴露出了响应时长在秒级别。因此这里引出了一个典型的生产消费问题,是高峰期调用方太过频繁,导致被调用方服务被拖慢了? 带着这个疑问,继续了剩余的两板斧。
二斧:内存观察是否"撑爆"了服务
内存问题往往带来更"温水煮青蛙"式的故障表现。它不像网络那样立刻炸掉服务,但却能逐步侵蚀服务能力,直至 OOM 或性能崩溃。特别是在网络排查哪一步观察到的情况,以及下面对自身调用方服务的排查,又引出了我的一个疑问。**难道是高峰期的调用频繁导致对方内存撑爆了?**遗憾的是,暂时这边看不到被调用方的情况,因此带着疑问,继续排查第三斧了。
典型症状:
响应变慢,但 CPU 占用正常
服务重启频繁,伴随 OOM 日志
JVM GC 次数激增 / Go 的 GC Pause 增高 / Python 报 MemoryError
排查手段:
指标层:查看服务实例的内存使用曲线、GC 频率、堆外内存增长趋势。
日志层:排查是否存在大对象堆积、缓存未释放、连接未关闭等内存泄漏行为。
工具层:JVM 可用 MAT、VisualVM、JFR 等工具抓取堆快照;Go 可以使用 pprof;Node.js 有 clinic.js;Rust、C++ 则可借助 Valgrind、Massif 等。
三斧:CPU 分析代码执行的热点
CPU 问题往往指向计算密集型逻辑或意外的死循环、资源竞争。和网络、内存相比,CPU 更贴近业务代码。但通过对代码的分析和各项指标的查看,确实也不像是CPU被打满了。特别是这种情况是偶发的。
典型症状:
单核占用 100%,服务无响应
某些请求路径性能异常,但逻辑"貌似没问题"
压测时 TPS 突然掉头向下,Latency 激增
排查手段:
指标层:抓 Prometheus 的 CPU 使用率 / Load Average,结合系统级别的 top、htop。
Trace 层:OpenTelemetry / SkyWalking 等链路追踪工具往往能看出慢请求在哪个方法上耗时最长。
Profiling:建议所有服务集成运行时性能分析器(如 Pyroscope、Parca、Datadog APM 等),可以实时获取火焰图(Flamegraph)分析 CPU 消耗热点。
因此,当三板斧轮完后,这边得出了一个大致的结论。或许问题就出在提出的第一个疑问上,典型的一个生产消费问题。但这个毕竟是调用的上游接口,认为有问题得拿出证据出来。因此,又对自身系统的关键节点加了一些可观测性的日志。
观测性
观测性并不是简单的日志收集、指标上报或链路追踪,它是系统可被理解程度的总和。之所以先谈论观测性,是因为系统崩了,我们能不能不靠猜,通过这些观测数据知道它为什么崩、哪里崩、什么时候开始崩?换句话说就是快速定位问题的故障节点所在,然后进行对症下药。
当然,对于当前这个遗留的老系统而言,虽然对网络、CPU、内存、以及GC、Tomcat线程、数据库连接池等等都进行了监控。但是这是系统层面比较大粒度的一个监控。要想通过这些信息快速找到问题所在,比较有难度(至少我一时间没看出来问题所在,毕竟各项指标都显示正常🫣),特别是这部分遗留代码还没有对应的上下文日志。因此,首先要做的便是收集足够的信息,然后进行推断。
笔者这里鉴于是生产的线上情况,采用了arthas字节码插桩的形式加入了对应的一部分日志进去。具体关于字节码编程和arthas相关的内容,感兴趣的可以自行搜索,这里就不在阐述。
从入口逆推
既然超时是发生在feign调用那里,因此我的思路便是从feign调用那里着手,先追加日志记录每次请求的往返时长,以及对应的HttpClient的请求线程数等数据。然后往前推,追加调用线程池那里的数据。最后分析调用源头。
通过分析HttpClient的请求线程数、响应时长以及对应的调用线程池数据得出了一个结论,被调用方某个时刻开始响应时长变慢。进而导致http请求迟迟得不到响应,挂在那里,导致请求积压。进而导致线程池里面的调度持续积压(特别是高峰时期),到超过等候时长后便报错超时异常。
上游接受的流量超载
当确定问题所在,于是下一步便是拿着证据和分析便去找上游服务协商如何解决(跨团队协作信息沟通往往是影响效率的重要因素,因此确定问题所在,也要带上证据)。
后续便是上游排查问题的流程了,最后给到的反馈是频繁调用的那个接口走的是IOTDB,对应响应是有点慢,然后又拉上了IOTDB团队协商解决。具体这里就不详述了,无非就是走缓存,增加集群之类的。
当上游还在观测以及确定方案时,我借用来权限,进入对方系统查看观察了一下日志,不看还好,一看发现了一些异常的流量请求(不是来自于我们系统的),突然间的发现似乎找到了问题所在。(前面虽然确定了上游接口慢,但还是在反思我们调用方的调用有那么频繁吗?虽然理智告诉我并不频繁,但确实上游服务被请求崩了🤣)。异常的流量请求打崩了上游服务,导致我们下游调用方的请求响应变慢,进而拖累了后续的调用线程和业务逻辑。导致出现了偶发的请求超时现象。
通过异常流量追溯,发现流量来自另外一个团队的系统。请求量级达到了上游服务的处理上线,致使其不断重启。到了这里,好吧,闹了个大乌龙🤣。问题出在另外的系统调用上。
最后找到对应团队,他们自称是秒级调用频率,但是从最终的日志记录来看,实绩频率已经达到了每毫秒实时都有请求打进来。然后最终就是对方降频,调整。完毕后,观察了一段时间,确实再无对应问题出现。至此问题解决了,但过程和结构确实令人哭笑不得。
小结
这件令人哭笑不得的滑稽问题排查给了我一些警示:
系统性思维的重要性:在排查问题时,不能只关注自己负责的系统,而应该从整个调用链路的角度去思考。这次问题虽然表现为我们系统的请求超时,但根源却在其他系统的异常流量上。
可观测性的价值:如果没有足够的日志和监控数据,这次问题的排查可能会走很多弯路。通过添加关键节点的日志,我们才能快速定位到问题所在。这也提醒我们在系统设计时就要考虑好可观测性。
跨团队协作的艺术:在排查跨团队的问题时,证据和数据的沟通比主观判断更有说服力。带着具体的数据和日志去沟通,能大大提高问题解决的效率。
问题排查的方法论:这次经历验证了"三板斧"排查方法的有效性。从网络、内存、CPU三个维度入手,能帮助我们快速缩小问题范围,避免在错误的方向上浪费时间。
系统设计的思考:这次事件也暴露了上游服务在流量控制方面的不足。作为调用方,我们也应该考虑增加熔断、降级等保护机制,避免被上游服务的问题拖垮。
保持怀疑精神:即使在找到初步原因后,也要保持怀疑和探索的态度。这次如果不是继续深入查看上游日志,可能就会错过真正的根因。
当然话虽这么说,面对一些陈年老项目处理起来也确实不容易😂。这次问题排查虽然令人哭笑不得,但确实也加深了自己的认识【任何系统都不是完全可靠的】,也为今后的系统设计和问题排查提供了宝贵的经验。