Actor模型
第一次看到Actor模型这个词还要追述到几年前在网易实习的时候,当时组内便是基于Actor做相关的一些开发,然后去了解了一下,后续也没什么实践的地方,只在一些书本或文章上看到过相关的一些内容,逐渐都快忘了这么一个东西,但最近无意间在github上又看到了相关内容,比较感兴趣,遂又去了解了一下,在此简单记录
关于Actor
Actor模型是一种用于处理并发计算和分布式系统的抽象模型。由Carl Hewitt在1973年提出,它将计算过程分解为独立的、并发的“actor”。每个actor是一个独立的计算实体,具有自己的状态和行为,并通过消息传递与其他actor进行通信。也就是说,它可以被分配,分布,调度到不同的CPU,不同的节点,乃至不同的时间片上运行,而不影响最终的结果。因此Actor在空间(分布式)和时间(异步驱动)上解耦的。我们在了解actor模型之前,首先来了解actor模型主要是为了解决什么样的问题。
- 在面向对象的语言中一个显著的特点是封装,然后通过对象提供的一些方法来操作其状态,但是共享内存的模型下,多线程对共享对象的并发访问会造成并发安全问题。一般会采用加锁的方式去解决,但加锁会带来一些问题:
- 加锁的开销很大,线程上下文切换的开销大
- 加锁导致线程block,无法去执行其他的工作,被block无法执行的线程,其实也是占据了一种系统资源
- 加锁在编程语言层面无法防止隐藏的死锁问题
- 我们知道Java中并发模型是通过共享内存来实现。而cpu中会利用局部cache来加速主存的访问,为了解决多线程间缓存不一致的问题,在java中一般会通过使用volatile或者Atmoic来标记变量,通过Jmm的happens before机制来保障多线程间共享变量的可见性。因此从某种意义上来说是没有共享内存的,而是通过cpu将cache line的数据刷新到主存的方式来实现可见。因此与其去通过标记共享变量或者加锁的方式,依赖cpu缓存更新,倒不如每个并发实例之间只保存local的变量,而在不同的实例之间通过message来传递。
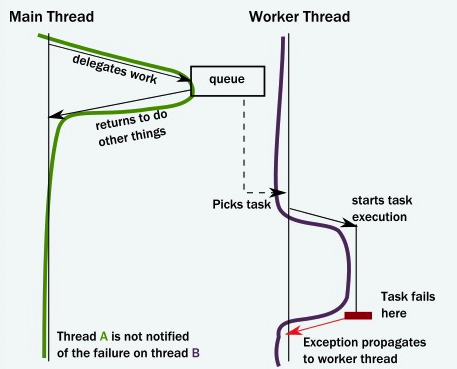
- call stack的问题:当我们编程模型异步化之后,还有一个比较大的问题是调用栈转移的问题,如下图中主线程提交了一个异步任务到队列中,Worker thread 从队列提取任务执行,调用栈就变成了workthread发起的,当任务出现异常时,处理和排查就变得困难。
那Actor模型又是如何解决这些问题的呢?
使用 Actor 允许我们:
- 在不使用锁的情况下强制封装。
- 利用协同实体对信号作出反应、改变状态、相互发送信号的模型来驱动整个应用程序向前发展。
- 不要担心执行机制与我们的世界观(world view)不匹配。
Actor 的核心思想是 独立维护隔离状态,并基于消息传递实现异步通信。围绕其进行实现,actor 通常包含以下特征:
- 每个 actor 持有一个邮箱(mailbox),本质上是一个队列,用于存储消息。
- 每个 actor 可以发送消息至任何 actor。
- 每个 actor 可以通过处理消息来更新内部状态,对于外部而言,actor 的状态是隔离的状态(isolated state)。
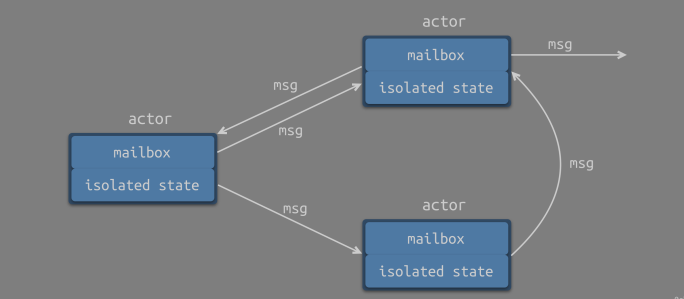
当 Actor 收到消息时会发生以下情况:
- Actor 将消息添加到队列的末尾。
- 如果 Actor 没有执行计划,则将其标记为准备执行。
- 一个(隐藏的)调度程序实体获取 Actor 并开始执行它。
- Actor 从队列前面选择消息。
- Actor 修改内部状态,向其他 Actor 发送消息。
- Actor 没有预约(unscheduled)。
为了便于通信,actor 模型使用 异步 消息传递。消息传递不使用任何中间实体,如:通道(channel)。由于 actor 模型的消息是异步传递的,中间可能会经过很长时间,甚至丢失,因此无法保证消息到达目标 actor 时的顺序。每个 actor 都完全独立于任何其他实例,actor 之间的交互完全基于异步消息,因此能够在很大程度上避免共享内存的存在问题。
任务调度
Actor 模型根据任务调度的方式可以分为两种,分别是:
- 基于线程(thread-based)的 actor 模型
- 事件驱动(event-driven)的 actor 模型
基于线程(thread-based)的 actor 模型
基于线程的 actor 模型,其本质是为每一个 actor 分配一个独立的“线程”。这里的“线程”并不是严格意义的操作系统线程,而是广泛意义的执行过程,它可以是线程、协程或虚拟机线程。
在基于线程的 actor 模型中,每个 actor 独占一个线程,如果当前 actor 的邮箱为空,actor 会阻塞当前线程,等待接收新的消息。在实现中,一般使用 receive 原语。
这种 actor 模型实现起来比较简单,但是缺点也非常明显,由于线程数量受到系统的限制,因此 actor 的数量也会受到限制。现阶段,只有少部分 actor 模型采用基于线程的实现方式,如:Erlang、Scala Actor、Cloud Haskell。
事件驱动的 actor 模型
在事件驱动的 actor 模型,actor 并不直接与线程耦合,只有在事件触发(即接收消息)时,才为 actor 的任务分配线程并执行。这种方式使用续体闭包(Continuation Closure)来封装 actor 及其状态。当事件处理完毕,即退出线程。通过这种方式,我们可以使用很少的线程来执行大量 actor 产生的任务。在实现中,一般使用 react 原语。
事件驱动的 actor 模型在消息触发时,会自动创建并分配线程。在这种过程中,一般的优化是将 actor 执行建立在底层的线程池之上,这些线程可以是线程、协程或虚拟机线程。从概念上讲,这种实现与 run loop、event loop 机制非常相似。
现阶段,大部分 actor 模型采用事件驱动的调度方式。
Akka
Akka 是一个用 Scala 编写的库,用于在 JVM 平台上简化编写具有可容错的、高可伸缩性的 Java 和 Scala 的 Actor 模型应用,其同时提供了Java 和 Scala 的开发接口。Akka 允许我们专注于满足业务需求,而不是编写初级代码。在 Akka 中,Actor 之间通信的唯一机制就是消息传递。Akka 对 Actor 模型的使用提供了一个抽象级别,使得编写正确的并发、并行和分布式系统更加容易。Actor 模型贯穿了整个 Akka 库,为我们提供了一致的理解和使用它们的方法。
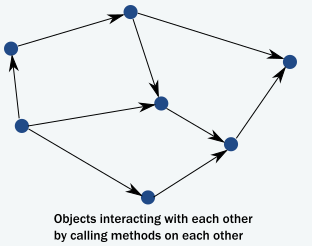
在面向对象语言中,我们通常很少考虑线程或线性执行路径。我们通常将系统设想为一个对象实例网络,这些对象实例对方法调用作出反应,修改其内部状态,然后通过方法调用相互通信,从而推动整个应用程序状态前进:
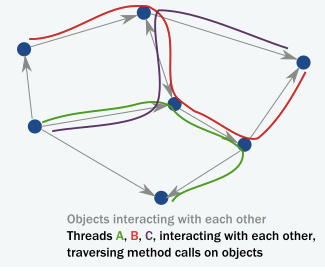
但是,在多线程分布式环境中,实际发生的情况是线程通过以下方法调用“遍历”对象实例网络。因此,线程才是真正推动执行的因素:
Actor 能够优雅地处理错误情况
由于我们不再拥有在相互发送消息的 Actor 之间共享的调用栈,因此我们需要以不同的方式处理错误情况。我们需要考虑两种错误:
- 第一种情况是,由于任务中的错误(通常是一些验证问题,如不存在的用户 ID),目标 Actor 上的委派任务失败。在这种情况下,由目标 Actor 封装的服务是完整的,只有任务本身是错误的。服务 Actor 应该用一条消息回复发送者,并显示错误情况。这里没有什么特别的,错误是域的一部分,因此错误也是普通消息。
- 第二种情况是当服务本身遇到内部故障时。Akka 要求所有 Actor 都被组织成一个树形的结构,即一个创造另一个 Actor 的 Actor 成为新 Actor 的父节点。这与操作系统将流程组织到树中的方式非常相似。就像处理过程一样,当一个 Actor 失败时,它的父 Actor 会得到通知,并且它可以对失败做出反应。另外,如果父 Actor 被停止,那么它的所有子 Actor 也将被递归地停止。这项服务称为监督,是 Akka 的核心概念。
一个监督者(父级节点)可以决定在某些类型的失败时重新启动其子 Actor,或者在其他失败时完全停止它们。子 Actor 永远不会默不作声地死去(除了进入一个无限循环之外),相反,他们要么失败,他们的父级可以对错误作出反应,要么他们被停止(在这种情况下,相关方会被自动通知)。总是有一个负责管理 Actor 的实体:它的父节点。从外部看不到重新启动:协作 Actor 可以在目标 Actor 重新启动时继续发送消息。
小结
从我个人理解角度说,akka的actor模型采用基于消息传递的机制实现并发编程,可以实现无锁异步化的编程模型,并且通过亲和性调度等方案,可以更好的利用cpu cache,对于高并发场景来说应该是一大利器。同样其中的某些思想,也适用于实时数据处理、分布式系统、IOT系统、游戏开发等场景。